[Spark] 01 - What is Spark
大数据
云计算概念
一、课程资源
厦大课程:Spark编程基础(Python版)
优秀博文:Spark源码分析系列(目录)
二、大数据特点
大数据4V特性
Volumn, Variety, Velocity, Value。
思维方式
通过数据发现问题,再解决问题。
全样分析,精确度的要求降低。
三、分布式方案
分布式存储
- 分布式文件系统:GFS/HDFS
- 分布式数据库:BigTable/HBase
- NoSql
分布式处理
- map/reduce【面向批处理】
- Spark【面向批处理】
- Flink
四、大数据计算模式
(1) 批处理计算
(2) 流计算
S4, Flume, Storm
(3) 图计算
GIS系统,Google Pregel, 有专门图计算的工具。
(4) 查询分析计算
Google Dremel, Hive, Cassandra, Impala等。
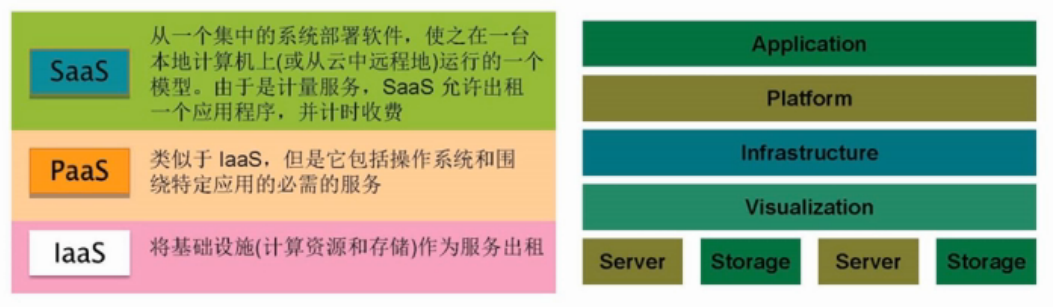
五、大数据服务
SaaS, PaaS, IaaS
六、大数据分析环境
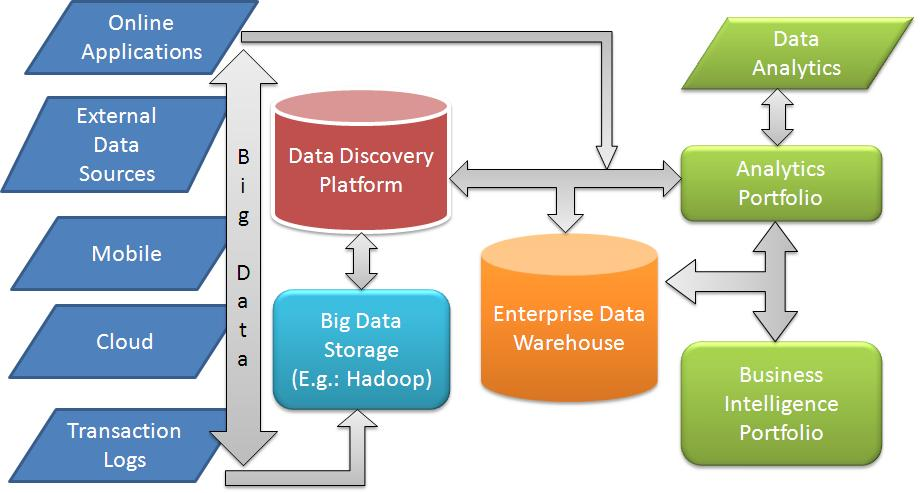
流程:ETL (Spark) --> Dataware house (HDFS, Cassandra, HBase) --> Data analysis (Spark) --> Reporting & visualization
Lambda 架构:同时处理“实时”和“离线”的部分。
生态系统
一、Hadoop 生态系统
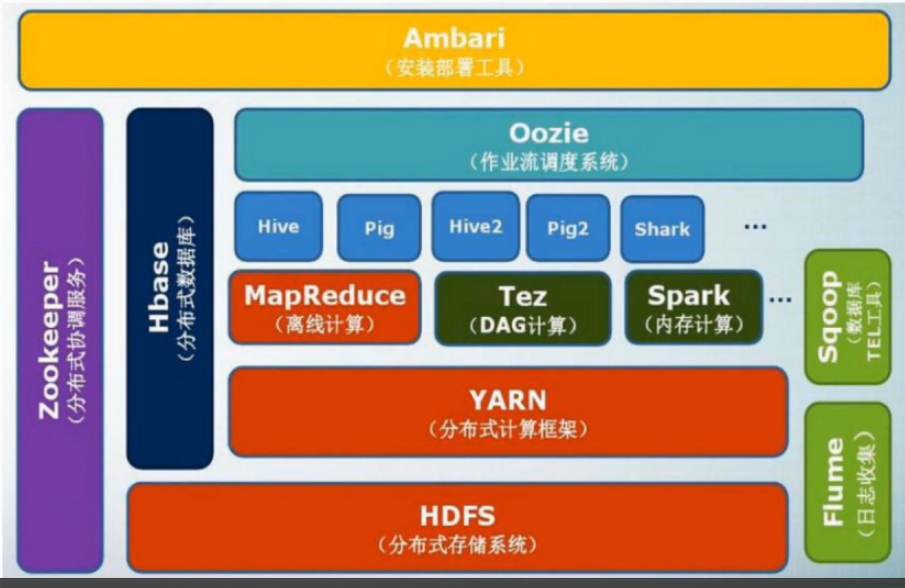
| Tez | 构建有向无环图。 |
| Hive | 数据仓库,用于企业决策,表面上写得是sql,实际转换为了mapReduce语句。 |
| Pig | 类似sql语句的脚本语言,可以嵌套在其他语言中。(提供轻量级sql接口) |
| Oozie | 先完成什么,再完成什么。 |
| Zookeeper | 集群管理,哪台机器是什么角色。 |
| Hbase | 面向列的存储,随机读写;HDFS是顺序读写。 |
| Flume | 日志收集。 |
| Sqoop | 关系型数据库导入Hadoop平台。主要用于在Hadoop(Hive)与传统的数据库间进行数据的传递 |
| Ambari | 部署和管理一整套的各个套件。 |
二、Spark 生态系统

三、Flink
Java派别的Spark竞争对手。
基于“流处理”模型,实时性比较好。
Goto: 第一次有人把Apache Flink说的这么明白!
四、Beam
翻译成Flink or Spark的形式,类似于 Keras,试图统一接口。
Goto: Apache Beam -- 简介
引入 Spark
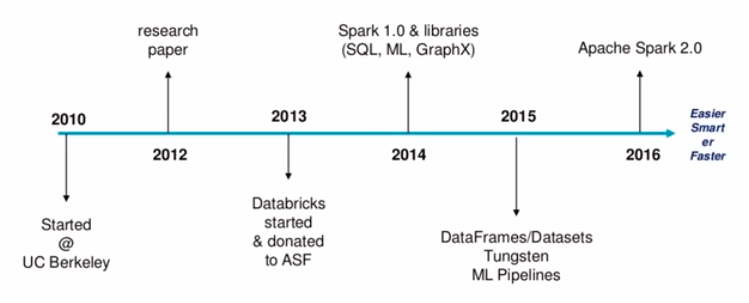
一、年轻
二、代码简洁
// word count.
rdd = sc.textFile("input.csv") wordCounts = rdd.map(lambda line: line.split(",")) \
.map(lambda word: (word, 1)) \
.reduceByKey(lambda x, y: x+y).collect()
Spark的设计与运行原理
原理分析
一、基本概念
(1) RDD 数据抽象
RDD: 弹性分布式数据集(内存中),存储资料的基本形式。
分区数量可以 动态变化。
(2) DAG 有向无环图
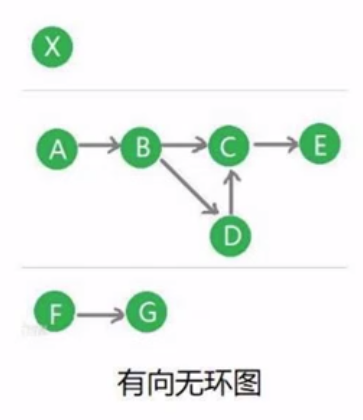
(3) 运行在Executor上的工作单元 - Task
“进程”派生出很多“线程”,然后完成每一个任务。
Executor进程,驻留在每一个work node上的。
(4) 作业 - Job
一个作业包含多个RDD。
一个作业分解为多组任务,每一组的集合就是 Stage。
(5) Applicaiton
用户编写的spark程序。
二、鸟瞰图
基本运行框架。其中,Cluster Manager: spark自带的、Yarn等等。
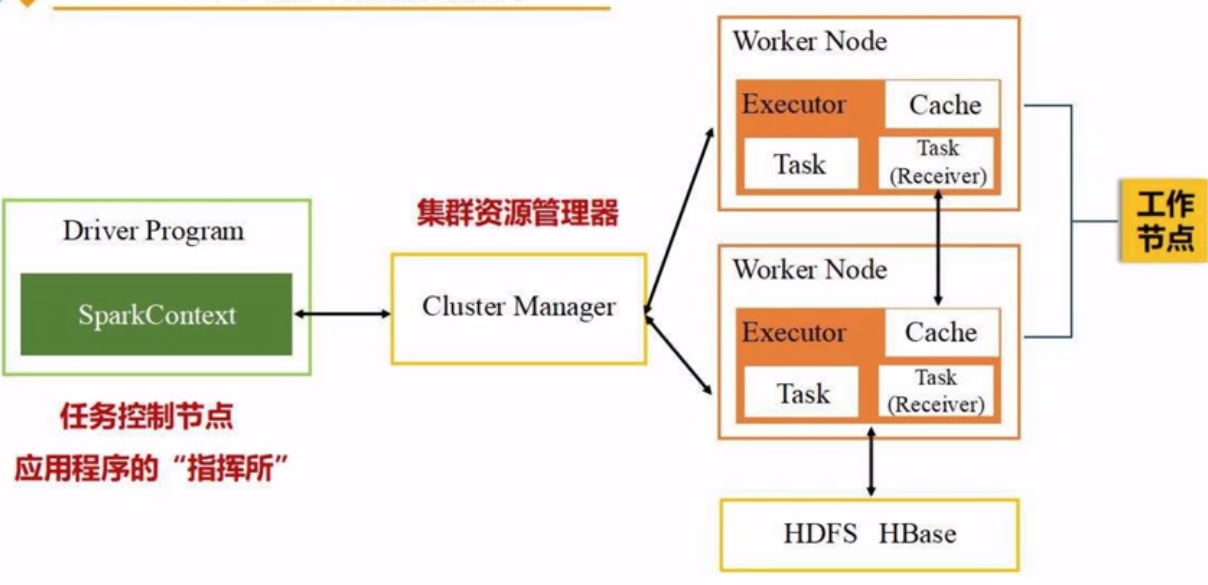
三、申请资源过程
- 主节点 Spark Driver (指挥所, 创建sc即指挥官) 向 Cluster Manager (Yarn) 申请资源。
- 启动 Executor进程,并且向它发送 code 和 files。
- 应用程序在 Executor进程 上派发出线程去执行任务。
- 最后把结果返回给 主节点 Spark Driver,写入HDFS or etc.
四、运行基本流程
SparkContext解析代码后,生成DAG图。
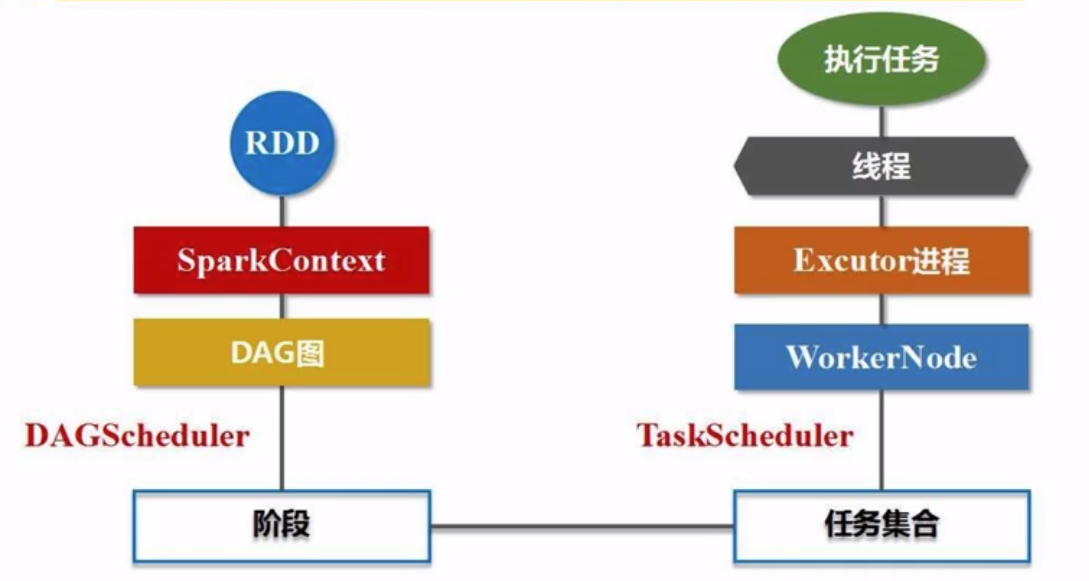
DAG Scheduler
一、 Resilient Distributed Dataset (RDD)
(1) 高度受限 - 只读
本质是:一个 "只读的" 分区记录集合。
Transformation 过程中,RDD --> RDD,期间允许“修改”。
(2) 两种“粗粒度”操作
* Action类型。(触发计算得到结果)
* Transformation类型。(只是做了个意向记录)
"细粒度" 怎么办?例如:网页爬虫,细粒度更新。
因为提供了更多的操作,这些 “操作的组合” 也可以做“相同的事情“。
(3) 更多的"操作"
比如:map, filter, groupBy, join
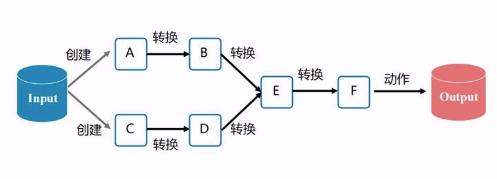
之所以”高效“,是因为管道化机制。所以不需要保存磁盘,输入直接对接上一次输出即可。
(4) 天然容错机制
数据复制,记录日志(关系数据库),但,这样开销太大了。
Spark是天然容错性:DAG,可以根据前后节点反推出错误的节点内容。
二、RDD优化
根据 “宽依赖” 划分 “阶段” 的过程。
“宽依赖” 是啥
一个父亲对多个儿子。
例如:groupByKey, join操作。
要点:若是宽依赖,则可划分为多个”阶段“。
“阶段” 如何划分
因为这样符合优化原理。

为何要划分 “阶段”
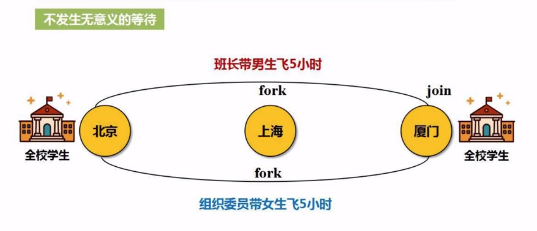
(a) 窄依赖:不要”落地“,好比不用”写磁盘“,形成管道化的操作。
原本的 "窄依赖" 操作流程。
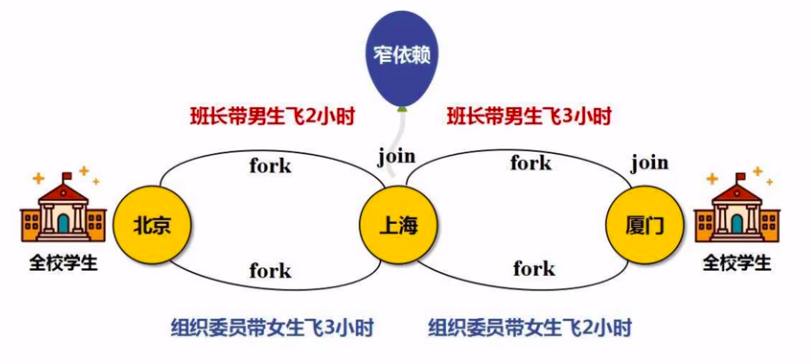
优化后的操作流程。
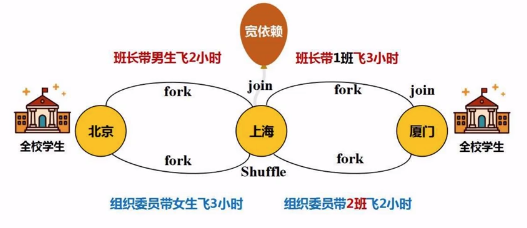
(b) 宽依赖:就会遇到shuffle操作,意味着“写磁盘”的一次操作。
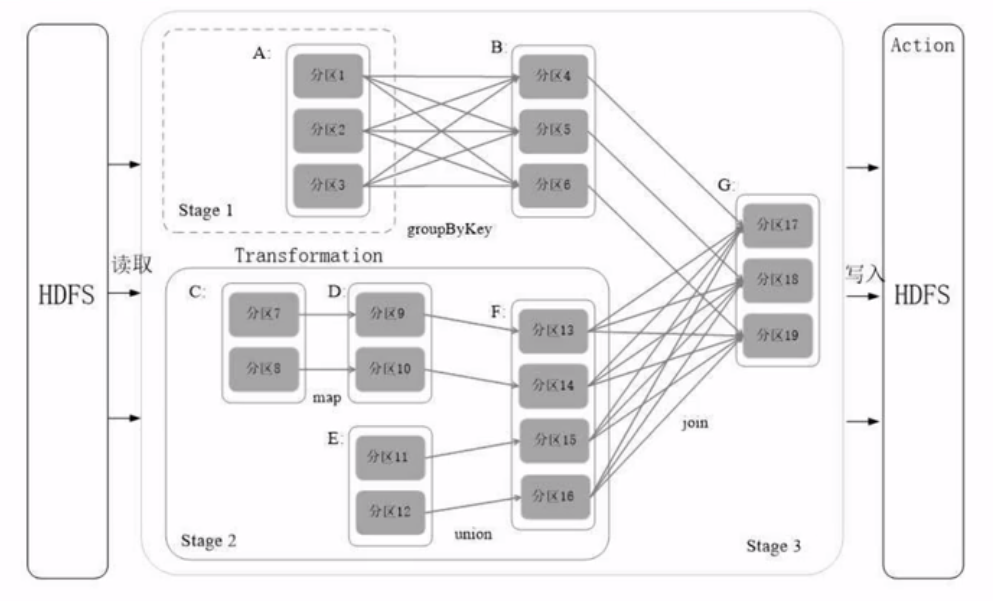
划分阶段实战
“窄依赖”:多个父亲对应一个儿子,不会阻碍效率。
内存有限的情况下 Spark 如何处理 T 级别的数据?
Ref: https://www.zhihu.com/question/23079001
/* implement */
End.
[Spark] 01 - What is Spark的更多相关文章
- [Spark] 06 - What is Spark Streaming
前言 Ref: 一文读懂 Spark 和 Spark Streaming[简明扼要的概览] 在讲解 "流计算" 之前,先做一个简单的回顾,亲! 一.MapReduce 的问题所在 ...
- [转] Spark快速入门指南 – Spark安装与基础使用
[From] https://blog.csdn.net/w405722907/article/details/77943331 Spark快速入门指南 – Spark安装与基础使用 2017年09月 ...
- Spark踩坑记——Spark Streaming+Kafka
[TOC] 前言 在WeTest舆情项目中,需要对每天千万级的游戏评论信息进行词频统计,在生产者一端,我们将数据按照每天的拉取时间存入了Kafka当中,而在消费者一端,我们利用了spark strea ...
- spark学习笔记总结-spark入门资料精化
Spark学习笔记 Spark简介 spark 可以很容易和yarn结合,直接调用HDFS.Hbase上面的数据,和hadoop结合.配置很容易. spark发展迅猛,框架比hadoop更加灵活实用. ...
- Spark On Yarn中spark.yarn.jar属性的使用
今天在测试spark-sql运行在yarn上的过程中,无意间从日志中发现了一个问题: spark-sql --master yarn // :: INFO Client: Requesting a n ...
- hadoop之Spark强有力竞争者Flink,Spark与Flink:对比与分析
hadoop之Spark强有力竞争者Flink,Spark与Flink:对比与分析 Spark是一种快速.通用的计算集群系统,Spark提出的最主要抽象概念是弹性分布式数据集(RDD),它是一个元素集 ...
- 【译】Spark官方文档——Spark Configuration(Spark配置)
注重版权,尊重他人劳动 转帖注明原文地址:http://www.cnblogs.com/vincent-hv/p/3316502.html Spark主要提供三种位置配置系统: 环境变量:用来启动 ...
- 【Spark学习】Apache Spark配置
Spark版本:1.1.1 本文系从官方文档翻译而来,转载请尊重译者的工作,注明以下链接: http://www.cnblogs.com/zhangningbo/p/4137969.html Spar ...
- Spark Streaming揭秘 Day35 Spark core思考
Spark Streaming揭秘 Day35 Spark core思考 Spark上的子框架,都是后来加上去的.都是在Spark core上完成的,所有框架一切的实现最终还是由Spark core来 ...
随机推荐
- redis最基础的入门教程
Redis最基础入门教程 简介 Redis 简介 Redis 优势 Redis与其他key-value存储有什么不同? 字符串(Strings) 哈希(Hash) 列表(List) 集合(Sets ...
- 关于Python虚拟环境与包管理你应该知道的事
关于我 一个有思想的程序猿,终身学习实践者,目前在一个创业团队任team lead,技术栈涉及Android.Python.Java和Go,这个也是我们团队的主要技术栈. Github:https:/ ...
- 十款强大的IDEA插件-Java开发者的利器
xl_echo编辑整理,欢迎转载,转载请声明文章来源.欢迎添加echo微信(微信号:t2421499075)交流学习. 百战不败,依不自称常胜,百败不颓,依能奋力前行.--这才是真正的堪称强大!! 插 ...
- c中自增自减的妙用
#include <stdio.h> int main() { ; printf("%d,%d,%d,%d",i++;i--;++i;--i); /*运算从右往左运算 ...
- go 学习笔记之详细说一说封装是怎么回事
关注公众号[雪之梦技术驿站]查看上篇文章 猜猜看go是不是面向对象语言?能不能面向对象编程? 虽然在上篇文章中,我们通过尝试性学习探索了 Go 语言中关于面向对象的相关概念,更确切的说是关于封装的基本 ...
- 0807 创建vue实例以及vue的基础指令
lession1 1.Vue的了解 渐进式框架 作者:尤雨溪 mvvm 2.创建vue实例 引入<script src="vue.js"><scr ...
- C#开发BIMFACE系列16 服务端API之获取模型数据1:查询满足条件的构件ID列表
系列目录 [已更新最新开发文章,点击查看详细] 源文件/模型转换完成之后,可以获取模型的具体数据.本篇介绍根据文件ID查询满足条件的构件ID列表. 请求地址:GET https://api.b ...
- codeforces 820 C. Mister B and Boring Game(找规律)
题目链接:http://codeforces.com/contest/820/problem/C 题解:显然a<=b的规律很好找只要 例如a=2,b=5,只要这样排列就行abbbbbbabbbb ...
- 牛客网暑期ACM多校训练营(第三场) E Sort String 哈希处理字符串(模板)
链接:https://www.nowcoder.com/acm/contest/141/E来源:牛客网 Eddy likes to play with string which is a sequen ...
- codeforces 765 D. Artsem and Saunder(数学题)
题目链接:http://codeforces.com/contest/765/problem/D 题意:题目中给出你两个公式,g(h(x))==x,h(g(x))==f(x).现给你f(x) 让你求符 ...