java架构之路-(源码)mybatis的一二级缓存问题
上次博客我们说了mybatis的基本使用,我们还捎带提到一下Mapper.xml中的select标签的useCache属性,这个就是设置是否存入二级缓存的。
回到我们正题,经常使用mybatis的小伙伴都知道,我们的mybatis是有两级缓存的,一级缓存默认开启,我们先来一下一级缓存吧,超级简单。
一级缓存:
我们还拿上次的源码来说
package mybatis; import mybatis.bean.StudentBean;
import mybatis.dao.StudentMapper;
import org.apache.ibatis.io.Resources;
import org.apache.ibatis.session.SqlSession;
import org.apache.ibatis.session.SqlSessionFactory;
import org.apache.ibatis.session.SqlSessionFactoryBuilder;
import org.junit.Before;
import org.junit.Test; import java.io.IOException;
import java.io.InputStream; public class Test1 { public SqlSession session;
public SqlSessionFactory sqlSessionFactory; @Before
public void init() throws IOException {
String resource = "mybatis-config.xml";
InputStream inputStream = Resources.getResourceAsStream(resource);
sqlSessionFactory = new SqlSessionFactoryBuilder().build(inputStream);
session = sqlSessionFactory.openSession();
} @Test
public void studentTest(){
StudentMapper mapper = session.getMapper(StudentMapper.class);
StudentBean result = mapper.selectUser(1);//这句执行了sql,也就是说,这句给一级缓存塞了值
StudentBean result2 = mapper.selectUser(1);//这句执行了sql,也就是说,这句给一级缓存塞了值 System.out.println(result==result2);
}
}
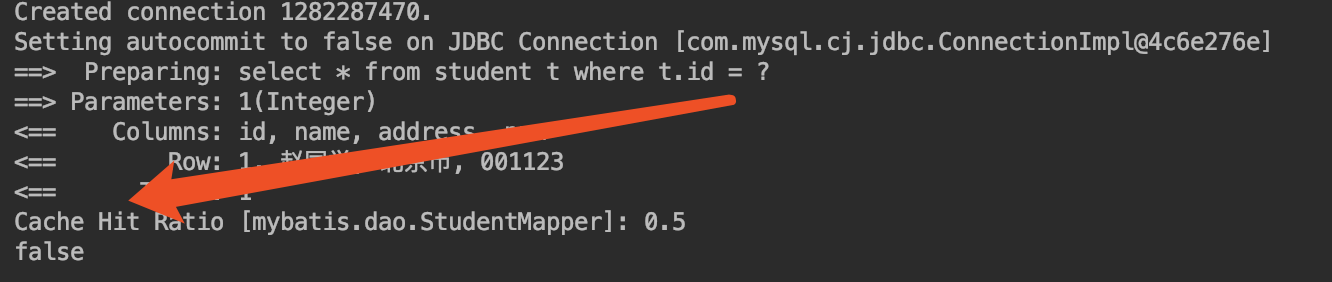
我们可以看到打印结果为true,说明了命中了我们的一级缓存。
一级缓存的限制比较多,需要在同一个session,同一个会话,同一个方法(statement),内执行完全相同的sql,才能保证缓存的成功。
我们打开Mybatis里的BaseExecutor类我们找到152行代码。
list = resultHandler == null ? (List<E>) localCache.getObject(key) : null;
这个就是我们的一级缓存localCache。清空方法是在BaseExcutor的116行clearLocalCache,来清空我们的一级缓存的,所以说执行update以后一级缓存会被清空,后面有机会我会告诉大家我是怎么找到的,只要记住一级缓存默认开启,是sqlSession级别的,几乎是没有生命的。然后记住什么情况下可以用,什么情况下不可以用,初级面试应该可以应付。
二级缓存:
二级缓存需要手动设置,只要在我们的配置文件内加入Cache标签就可以了。或者加入@Cache注解也是ok的,二级缓存是在session关闭时才写入的。为什么这样设计呢?我们来假想一下,我们开启session,做了一个insert写入,这时还没有提交,然后我们进行了查询,如果这时写入缓存,然后我们将insert进行回滚,那么我们的缓存就多了我们刚才写入的数据,这样的设计是显然不合理的,我们先来看一下二级缓存是怎么设置的。
谁说查询时候先查二级缓存,二级缓存没有再查一级缓存的,一律打死,一级缓存作用在session会话范围,你二级缓存的存入条件是session关闭,session都关闭了,还有毛线一级缓存了....
还是上次的代码:我们来回顾一下。
package mybatis; import mybatis.bean.StudentBean;
import mybatis.dao.StudentMapper;
import org.apache.ibatis.io.Resources;
import org.apache.ibatis.session.SqlSession;
import org.apache.ibatis.session.SqlSessionFactory;
import org.apache.ibatis.session.SqlSessionFactoryBuilder;
import org.junit.Before;
import org.junit.Test;
import java.io.IOException;
import java.io.InputStream; public class Test1 { public SqlSession session;
public SqlSessionFactory sqlSessionFactory; @Before
public void init() throws IOException {
String resource = "mybatis-config.xml";
InputStream inputStream = Resources.getResourceAsStream(resource);
sqlSessionFactory = new SqlSessionFactoryBuilder().build(inputStream);
session = sqlSessionFactory.openSession();
} @Test
public void studentTest(){
StudentMapper mapper = session.getMapper(StudentMapper.class);
StudentBean result = mapper.selectUser(1);
session.close(); session = sqlSessionFactory.openSession();
StudentMapper mapper2 = session.getMapper(StudentMapper.class);
StudentBean result2 = mapper2.selectUser(1);
System.out.println(result == result2); } }
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="mybatis.dao.StudentMapper">
<cache></cache>
<select id="selectUser" resultType="mybatis.bean.StudentBean">
select * from student t where t.id = #{id}
</select>
</mapper>
我们只需要加入cache标签即可以使用我们的二级缓存。select标签内有一个useCache属性设置成false就是说,这个sql不写入我们的缓存。需要注意的是要给予我们的实体Bean序列化,正因为序列化,我们的输入结果是false,说明并不是一个对象的。后面我会解释为什么需要做一个序列化,可以带着问题继续阅读。
注解方式这样写就ok了。
package mybatis.dao; import mybatis.bean.StudentBean;
import org.apache.ibatis.annotations.CacheNamespace;
import org.apache.ibatis.annotations.Select; @CacheNamespace
public interface StudentMapper { @Select("select * from student t where t.id = #{id}")
StudentBean selectUser(int id);
}
二级缓存适用范围:
1,必须是session提交以后,二级缓存才写入。
2,必须是同一个命名空间之下。
3,必须是相同的sql和参数。
4,如果是readWrite=true,实体类必须序列化
@CacheNamespace(readWrite = false)
这也就是我们说的为什么需要实例化,其实也可以不序列化的。但是我们要是改了其中一个数据,另外一个拿到的数据一定是修改后的,没有特殊需求最好是做一个序列化,不要写readWrite=false的设置,不写readWrite=false会提高一点点性能,但是自我觉得没必要冒那种风险。拿着这段代码自己测试一下,不带序列化的深拷贝对象会造成的结果。
package mybatis; import mybatis.bean.StudentBean;
import mybatis.dao.StudentMapper;
import org.apache.ibatis.io.Resources;
import org.apache.ibatis.session.SqlSession;
import org.apache.ibatis.session.SqlSessionFactory;
import org.apache.ibatis.session.SqlSessionFactoryBuilder;
import org.junit.Before;
import org.junit.Test;
import java.io.IOException;
import java.io.InputStream; public class Test1 { public SqlSession session;
public SqlSessionFactory sqlSessionFactory; @Before
public void init() throws IOException {
String resource = "mybatis-config.xml";
InputStream inputStream = Resources.getResourceAsStream(resource);
sqlSessionFactory = new SqlSessionFactoryBuilder().build(inputStream);
session = sqlSessionFactory.openSession();
} @Test
public void studentTest(){
StudentMapper mapper = session.getMapper(StudentMapper.class);
StudentBean result = mapper.selectUser(1);
System.out.println(result);
result.setId(2222);
session.commit(); session = sqlSessionFactory.openSession();
StudentMapper mapper2 = session.getMapper(StudentMapper.class);
StudentBean result2 = mapper2.selectUser(1);
System.out.println(result2); System.out.println(result == result2);
}
}
5,必须是相同的statement相同的方法。
内部还可以加很多属性的。
@CacheNamespace(
implementation = PerpetualCache.class, // 缓存实现 Cache接口 实现类
eviction = LruCache.class,// 缓存算法
flushInterval = 60000, // 刷新间隔时间 毫秒
size = 1024, // 最大缓存引用对象
readWrite = true, // 是否可写
blocking = false // 是否阻塞,防止缓存击穿的。
)
我们来简单的深入一下二级缓存的源码,我们在Mybatis的包里会看到这样一个文件,一个叫Cache的文件,也就是我们的缓存文件。
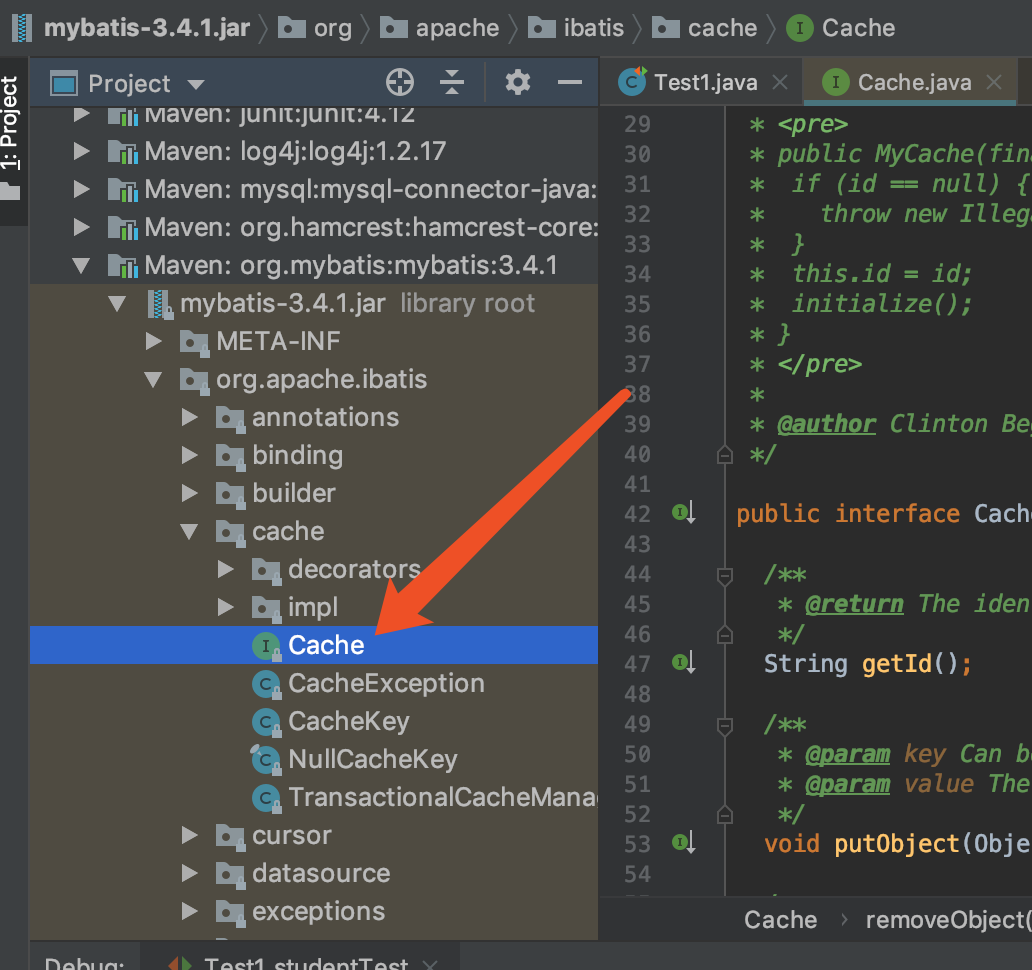
而且我们发现很多叫***Cahe的类都实现了他

TransactionalCache注释里明显的写到The 2nd level cache transactional buffer.二级缓存事务缓冲区。那么我们把断点打在他的get和put方法上,(可能是一个错误的示范,我会一步步告诉你们错了怎么改)
断点进到了getObject方法,我们点击开右边的参数栏,点击this,我们会看到我们的delegate参数,写着什么什么cache,再次点击还会发现什么什么Cache,直到不能向下点击为止
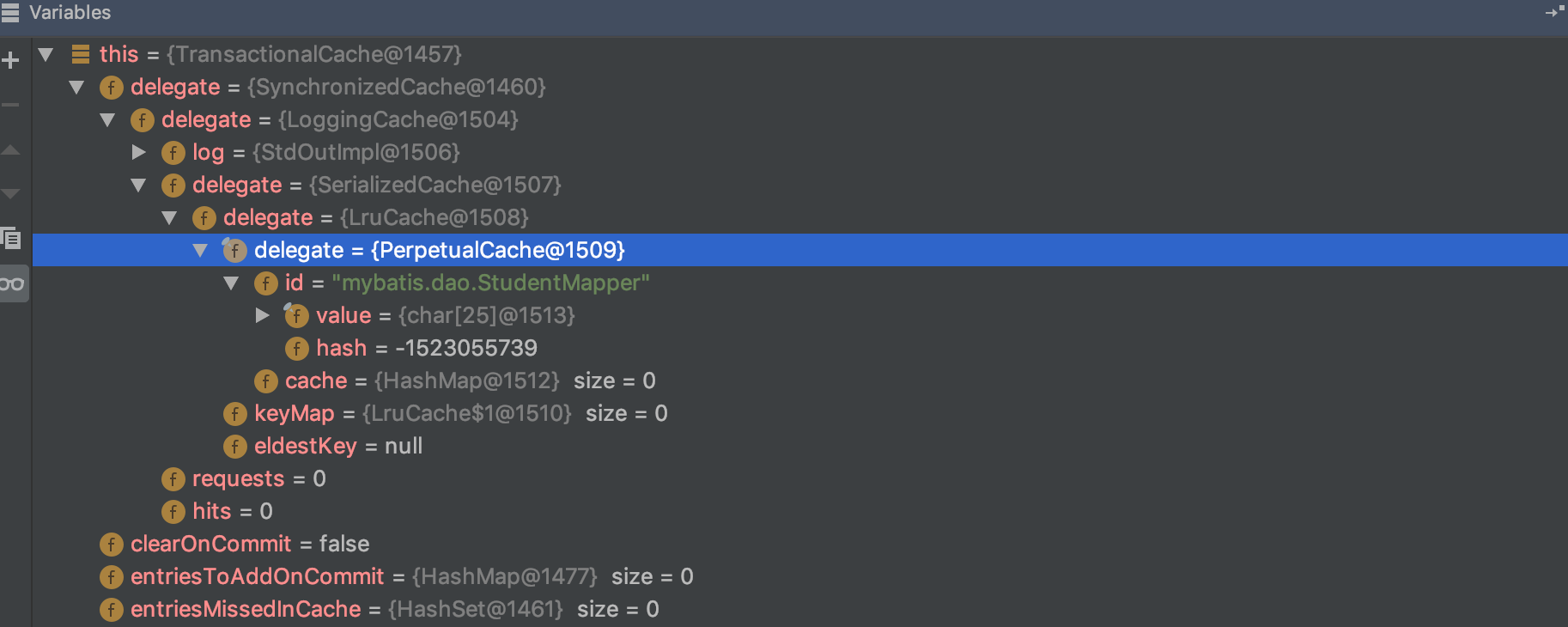
我们发现貌似实际存储的貌似是PerpetualCache,我们发现我们的错误了,重新来过,清楚断点,打开我们的PerpetualCache类,断点重新打在PerpetualCache类的get和put方法下。我们左侧的方法区,我们看到是这样的
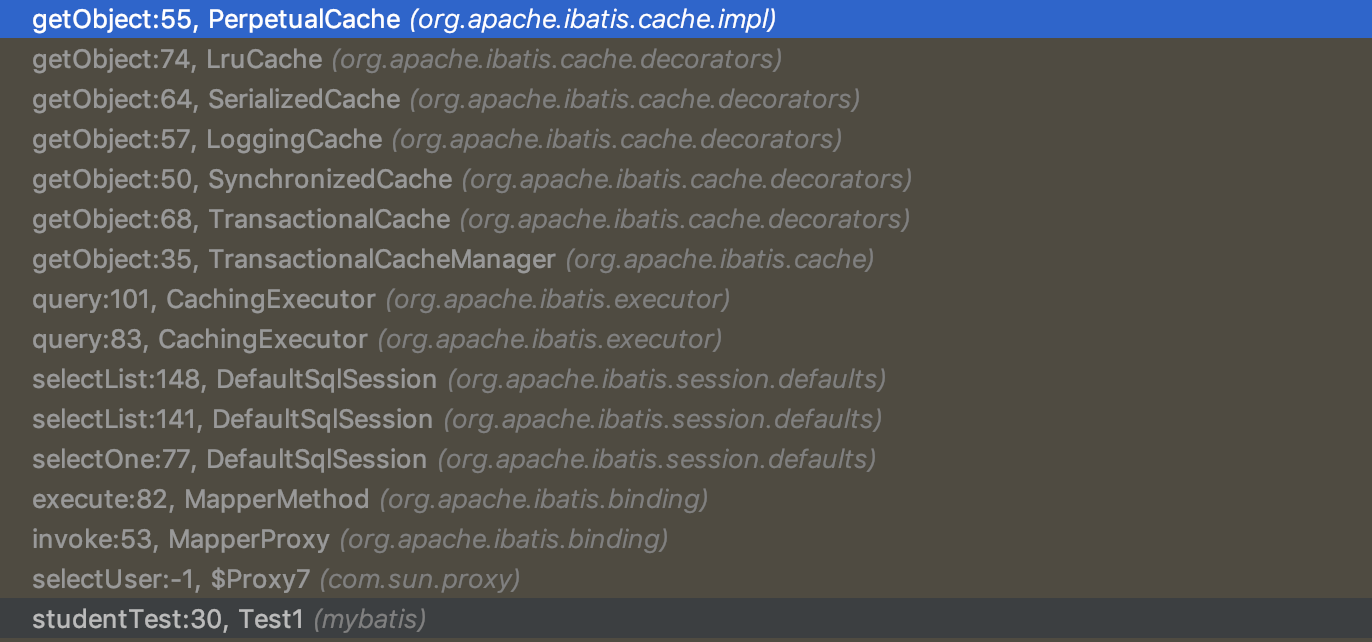
从Perpetualcahe一直查到TransactionalCache,我们来张图解释一下。
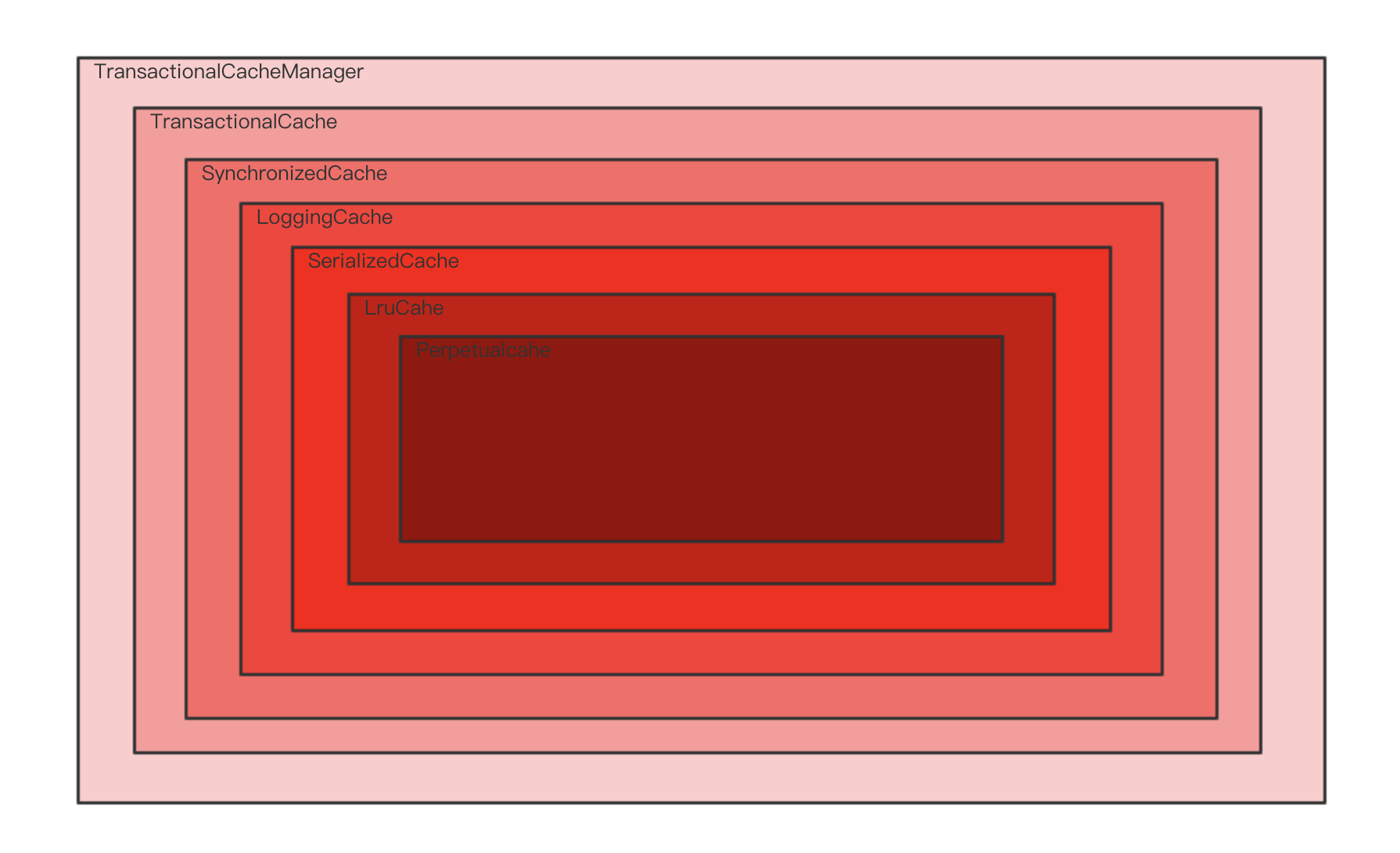
大致就是这样的,逐层去寻找的。这里就是一个装饰者模式。
我们还可以将断点打在CachingExecutor方法的query方法下来观察我们的二级缓存。这个方法在很早就先帮我们把Cache获取好了,且直接获取到SynchronizedCache层了。有兴趣的小伙伴可以自行测试一下,这里我就不再多说了,下次博客我们来具体深入的来看看Mybatis的执行流程,源码级。
感觉自己现在心中知道怎么去读源码,但是还是说不清楚,不能很好的表达出来,我再改进改进,可能还是看的不够深吧。。。
最进弄了一个公众号,小菜技术,欢迎大家的加入

java架构之路-(源码)mybatis的一二级缓存问题的更多相关文章
- Java生鲜电商平台-秒杀系统微服务架构设计与源码解析实战
Java生鲜电商平台-秒杀系统微服务架构设计与源码解析实战 Java生鲜电商平台- 什么是秒杀 通俗一点讲就是网络商家为促销等目的组织的网上限时抢购活动 比如说京东秒杀,就是一种定时定量秒杀,在规定 ...
- Java生鲜电商平台-电商会员体系系统的架构设计与源码解析
Java生鲜电商平台-电商会员体系系统的架构设计与源码解析 说明:Java生鲜电商平台中会员体系作为电商平台的基础设施,重要性不容忽视.我去年整理过生鲜电商中的会员系统,但是比较粗,现在做一个最好的整 ...
- Java生鲜电商平台-优惠券系统的架构设计与源码解析
Java生鲜电商平台-优惠券系统的架构设计与源码解析 电商后台:实例解读促销系统 电商后台系统包括商品管理系统.采购系统.仓储系统.订单系统.促销系统.维权系统.财务系统.会员系统.权限系统等,各系统 ...
- Java生鲜电商平台-促销系统的架构设计与源码解析
Java生鲜电商平台-促销系统的架构设计与源码解析 说明:本文重点讲解现在流行的促销方案以及源码解析,让大家对促销,纳新有一个深入的了解与学习过程. 促销系统是电商系统另外一个比较大,也是比较复杂的系 ...
- Activiti架构分析及源码详解
目录 Activiti架构分析及源码详解 引言 一.Activiti设计解析-架构&领域模型 1.1 架构 1.2 领域模型 二.Activiti设计解析-PVM执行树 2.1 核心理念 2. ...
- JAVA上百实例源码以及开源项目
简介 笔者当初为了学习JAVA,收集了很多经典源码,源码难易程度分为初级.中级.高级等,详情看源码列表,需要的可以直接下载! 这些源码反映了那时那景笔者对未来的盲目,对代码的热情.执着,对IT的憧憬. ...
- java多线程----线程池源码分析
http://www.cnblogs.com/skywang12345/p/3509954.html 线程池示例 在分析线程池之前,先看一个简单的线程池示例. 1 import java.util.c ...
- JAVA上百实例源码网站
JAVA源码包1JAVA源码包2JAVA源码包3JAVA源码包4 JAVA开源包1 JAVA开源包2 JAVA开源包3 JAVA开源包4 JAVA开源包5 JAVA开源包6 JAVA开源包7 JAVA ...
- Java并发指南10:Java 读写锁 ReentrantReadWriteLock 源码分析
Java 读写锁 ReentrantReadWriteLock 源码分析 转自:https://www.javadoop.com/post/reentrant-read-write-lock#toc5 ...
- 手把手带你阅读Mybatis源码(三)缓存篇
前言 大家好,这一篇文章是MyBatis系列的最后一篇文章,前面两篇文章:手把手带你阅读Mybatis源码(一)构造篇 和 手把手带你阅读Mybatis源码(二)执行篇,主要说明了MyBatis是如何 ...
随机推荐
- Markdown 基本语法(后面继续补充)
1.1 Markdown 基础语法 有序内容和无序内容 有序内容:输入1.然后按tab键 无序内容:输入' * ' 或 ' - ' 然后后按tab键 字体的样式 *** 内容 *** 加粗加斜(中间没 ...
- c# 三步递交模式调用同一个存储过程
主要用于批量的sql操作:第一步创建中间表,第二步多次写数据到中间表,第三步 提交执行 创建三步递交的存储过程: CREATE PROC usp_testsbdj@bz int=0,@name VAR ...
- cs231n---生成模型
1 生成模型的定义和分类 生成模型是一种无监督学习方法.其定义是给一堆由真实分布产生的训练数据,我们的模型从中学习,然后以近似于真实的分布来产生新样本. 生成模型分为显式和隐式的生成模型: 为什么生成 ...
- js及jquery常用代码
1.获取屏幕尺寸 document.documentElement.scrollWidth; document.documentElement.scrollHeight; $(window).widt ...
- 建立apk定时自动打包系统第一篇——Ant多渠道打包并指定打包目录和打包日期
团队开发时,每天都需要输出一个apk包给其它部门的同事测试验证.打包几乎是每天必须完成的功课.如果用IDE来输出apk,那速度是非常慢的,如果还需要有不同渠道的apk包,那程序猿都要疯了.当然也有用 ...
- 常用的python内置方法
all ( ) 循环参数,参数全为真就返回Ture any() 只要有一个 ...
- Android进阶之绘制-自定义View完全掌握(五)
在自定义类继承View实现自定义控件的过程中,我们还应该对一些自定义属性有所了解. 我们通过一个案例来学习一下. 新建一个android项目,然后我们创建一个类MyAttributeView继承Vie ...
- 900E关于导航站
--------------------------以下更新于20190826------------------------- 作用: 导航站为方便网址收藏之用,收录一些常用的网站,目前主要以本科常 ...
- 服务注册发现、配置中心集一体的 Spring Cloud Consul
前面讲了 Eureka 和 Spring Cloud Config,今天介绍一个全能选手 「Consul」.它是 HashiCorp 公司推出,用于提供服务发现和服务配置的工具.用 go 语言开发,具 ...
- ionic 技术要点
1.当遇到数据模型改变了,但是页面渲染的数据却没有改变的时候,尝试执行 $scope.$apply(): 2.时间的定义及监听: 定义事件 showNewMsg并从scope往下广播: $scope. ...