Java线程池ThreadPoolExecutor初略探索
在操作系统中,线程是一个非常重要的资源,频繁创建和销毁大量线程会大大降低系统性能。Java线程池原理类似于数据库连接池,目的就是帮助我们实现线程复用,减少频繁创建和销毁线程
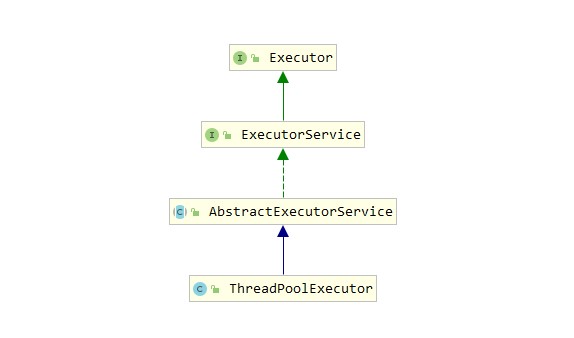
ThreadPoolExecutor
ThreadPoolExecutor是线程池的核心类。首先看一下如何创建一个ThreadPoolExecutor。下面是ThreadPoolExecutor常用的一个构造方法:
构造方法

public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler) {
if (corePoolSize < 0 ||
maximumPoolSize <= 0 ||
maximumPoolSize < corePoolSize ||
keepAliveTime < 0)
throw new IllegalArgumentException();
if (workQueue == null || threadFactory == null || handler == null)
throw new NullPointerException();
this.acc = System.getSecurityManager() == null ?
null :
AccessController.getContext();
this.corePoolSize = corePoolSize;
this.maximumPoolSize = maximumPoolSize;
this.workQueue = workQueue;
this.keepAliveTime = unit.toNanos(keepAliveTime);
this.threadFactory = threadFactory;
this.handler = handler;
}
使用案例
/**
* 阻塞的线程池
*/
private ThreadPoolExecutor executor = new ThreadPoolExecutor(
0, // corePoolSize:线程池维护线程的最少数量
4, // maximumPoolSize:线程池维护线程的最大数量
10000, // keepAliveTime:线程池维护线程所允许的空闲时间
TimeUnit.MILLISECONDS, // unite:线程池维护线程所允许的空闲时间的单位
new LinkedBlockingQueue<>(200), // workQueue:线程池所使用的缓冲队列
new CallerBlockedPolicy() // handler:线程池对拒绝任务的处理策略,自定义拓展
);
构造方法参数说明
- corePoolSize:核心线程数量,当有新任务在
execute()方法提交时,会执行以下判断:- 如果运行的线程少于
corePoolSize,则创建新线程来处理任务,即使线程池中的其他线程是空闲的; - 如果线程池中的线程数量大于等于
corePoolSize且小于maximumPoolSize,则只有当workQueue满时才创建新的线程去处理任务; - 如果设置的
corePoolSize和maximumPoolSize相同,则创建的线程池的大小是固定的,这时如果有新任务提交,若workQueue未满,则将请求放入workQueue中,等待有空闲的线程去从workQueue中取任务并处理; - 如果运行的线程数量大于等于maximumPoolSize,这时如果workQueue已经满了,则通过handler所指定的策略来处理任务;
所以,任务提交时,判断的顺序为 corePoolSize –> workQueue –> maximumPoolSize。
- 如果运行的线程少于
- maximumPoolSize:最大线程数量;
- workQueue:等待队列,当任务提交时,如果线程池中的线程数量大于等于
corePoolSize的时候,把该任务封装成一个Worker对象放入等待队列; - workQueue:保存等待执行的任务的阻塞队列,当提交一个新的任务到线程池以后, 线程池会根据当前线程池中正在运行着的线程的数量来决定对该任务的处理方式,主要有以下几种处理方式:
- 直接切换:这种方式常用的队列是
SynchronousQueue,但现在还没有研究过该队列,这里暂时还没法介绍; - 使用无界队列:一般使用基于链表的阻塞队列
LinkedBlockingQueue。如果使用这种方式,那么线程池中能够创建的最大线程数就是corePoolSize,而maximumPoolSize就不会起作用了(后面也会说到)。当线程池中所有的核心线程都是RUNNING状态时,这时一个新的任务提交就会放入等待队列中。 - 使用有界队列:一般使用
ArrayBlockingQueue。使用该方式可以将线程池的最大线程数量限制为maximumPoolSize,这样能够降低资源的消耗,但同时这种方式也使得线程池对线程的调度变得更困难,因为线程池和队列的容量都是有限的值,所以要想使线程池处理任务的吞吐率达到一个相对合理的范围,又想使线程调度相对简单,并且还要尽可能的降低线程池对资源的消耗,就需要合理的设置这两个数量。- 如果要想降低系统资源的消耗(包括CPU的使用率,操作系统资源的消耗,上下文环境切换的开销等), 可以设置较大的队列容量和较小的线程池容量, 但这样也会降低线程处理任务的吞吐量。
- 如果提交的任务经常发生阻塞,那么可以考虑通过调用
setMaximumPoolSize()方法来重新设定线程池的容量。 - 如果队列的容量设置的较小,通常需要将线程池的容量设置大一点,这样CPU的使用率会相对的高一些。但如果线程池的容量设置的过大,则在提交的任务数量太多的情况下,并发量会增加,那么线程之间的调度就是一个要考虑的问题,因为这样反而有可能降低处理任务的吞吐量。
- 直接切换:这种方式常用的队列是
- keepAliveTime:线程池维护线程所允许的空闲时间。当线程池中的线程数量大于
corePoolSize的时候,如果这时没有新的任务提交,核心线程外的线程不会立即销毁,而是会等待,直到等待的时间超过了keepAliveTime; - threadFactory:它是ThreadFactory类型的变量,用来创建新线程。默认使用
Executors.defaultThreadFactory()来创建线程。使用默认的- - - - ThreadFactory来创建线程时,会使新创建的线程具有相同的NORM_PRIORITY优先级并且是非守护线程,同时也设置了线程的名称。 - handler:它是
RejectedExecutionHandler类型的变量,表示线程池的饱和策略。如果阻塞队列满了并且没有空闲的线程,这时如果继续提交任务,就需要采取一种策略处理该任务。线程池提供了4种策略:- AbortPolicy:直接抛出异常,这是默认策略;
- CallerRunsPolicy:用调用者所在的线程来执行任务;
- DiscardOldestPolicy:丢弃阻塞队列中靠最前的任务,并执行当前任务;
- DiscardPolicy:直接丢弃任务;
线程池的监控
通过线程池提供的参数进行监控。线程池里有一些属性在监控线程池的时候可以使用
- getTaskCount:线程池已经执行的和未执行的任务总数;
- getCompletedTaskCount:线程池已完成的任务数量,该值小于等于taskCount;
- getLargestPoolSize:线程池曾经创建过的最大线程数量。通过这个数据可以知道线程池是否满过,也就是达到了 maximumPoolSize;
- getPoolSize:线程池当前的线程数量;
- getActiveCount:当前线程池中正在执行任务的线程数量。
总结一下线程池添加任务的整个流程:
- 线程池刚刚创建是,线程数量为0;
- 执行execute添加新的任务时会在线程池创建一个新的线程;
- 当线程数量达到corePoolSize时,再添加新任务则会将任务放到workQueue队列;
- 当队列已满放不下新的任务,再添加新任务则会继续创建新线程,但线程数量不超过maximumPoolSize;
- 当线程数量达到maximumPoolSize时,再添加新任务则会抛出异常。
Java线程池ThreadPoolExecutor初略探索的更多相关文章
- Java线程池ThreadPoolExecutor使用和分析(三) - 终止线程池原理
相关文章目录: Java线程池ThreadPoolExecutor使用和分析(一) Java线程池ThreadPoolExecutor使用和分析(二) - execute()原理 Java线程池Thr ...
- Java线程池ThreadPoolExecutor使用和分析(二) - execute()原理
相关文章目录: Java线程池ThreadPoolExecutor使用和分析(一) Java线程池ThreadPoolExecutor使用和分析(二) - execute()原理 Java线程池Thr ...
- Java线程池ThreadPoolExecutor使用和分析(一)
相关文章目录: Java线程池ThreadPoolExecutor使用和分析(一) Java线程池ThreadPoolExecutor使用和分析(二) - execute()原理 Java线程池Thr ...
- Java线程池ThreadPoolExecutor类源码分析
前面我们在java线程池ThreadPoolExecutor类使用详解中对ThreadPoolExector线程池类的使用进行了详细阐述,这篇文章我们对其具体的源码进行一下分析和总结: 首先我们看下T ...
- java线程池ThreadPoolExecutor使用简介
一.简介线程池类为 java.util.concurrent.ThreadPoolExecutor,常用构造方法为:ThreadPoolExecutor(int corePoolSize, int m ...
- Java 线程池(ThreadPoolExecutor)原理分析与使用
在我们的开发中"池"的概念并不罕见,有数据库连接池.线程池.对象池.常量池等等.下面我们主要针对线程池来一步一步揭开线程池的面纱. 使用线程池的好处 1.降低资源消耗 可以重复利用 ...
- Java 线程池(ThreadPoolExecutor)原理解析
在我们的开发中“池”的概念并不罕见,有数据库连接池.线程池.对象池.常量池等等.下面我们主要针对线程池来一步一步揭开线程池的面纱. 有关java线程技术文章还可以推荐阅读:<关于java多线程w ...
- Java线程池(ThreadPoolExecutor)原理分析与使用
在我们的开发中"池"的概念并不罕见,有数据库连接池.线程池.对象池.常量池等等.下面我们主要针对线程池来一步一步揭开线程池的面纱. 使用线程池的好处 1.降低资源消耗 可以重复利用 ...
- 转:JAVA线程池ThreadPoolExecutor与阻塞队列BlockingQueue
从Java5开始,Java提供了自己的线程池.每次只执行指定数量的线程,java.util.concurrent.ThreadPoolExecutor 就是这样的线程池.以下是我的学习过程. 首先是构 ...
随机推荐
- phpexcel 导出方法
Vendor("PHPExcel.PHPExcel"); Vendor("PHPExcel.PHPExcel.IOFactory"); Vendor(" ...
- [ASP.NET Core 3框架揭秘] 跨平台开发体验: Windows [上篇]
微软在千禧年推出 .NET战略,并在两年后推出第一个版本的.NET Framework和IDE(Visual Studio.NET 2002,后来改名为Visual Studio),如果你是一个资深的 ...
- 白话HTTPS加密机制
在讲主题之前,我们先来区分两个概念:签名和加密有什么区别? 我们从字面意思看: 签名就是一个人对文件签署自己的名字,证明这个文件是我写的或者我认可的,所以只要别人看到我的签名,认识我字迹的人就知道这个 ...
- Fast Earth - 文本 绘制,如何实现三维空间中绘制屏幕大小的文字?
如题:先上一张图,在说是如何实现的 实现上图效果,有如下三种方式: 1. 屏幕坐标绘制点要素,即将经纬度坐标转换成屏幕坐标方式绘制,大多数GIS系统都是采用这种方式: 优点:实现方式简单,效果较好 缺 ...
- centos7 安装 docker
一.概念 1.Docker引擎 (docker engine) 也称docker daemon,也称为docker服务,只要启动服务,就可以通过docker client发送相关docker命名,与d ...
- scalikejdbc 学习笔记(3)
重用connection: package com.citi.scalikejdbc import scalikejdbc._ import scalikejdbc.config._ object C ...
- 使用golang插入mysql性能提升经验
前言 golang可以轻易制造高并发,在某些场景很合适,比如爬虫的时候可以爬的更加高效.但是对应某些场景,如文件读写,数据库访问等IO为瓶颈的场合,就没有什么优势了. 前提基础 1.golang数据库 ...
- HTTP中get和post
HTTP中get和post的区别 GET - 从指定的资源请求数据. POST - 向指定的资源提交要被处理的数据 GET POST 后退/刷新 无害的 数据会被重新提交 书签 可收藏为书签 不可收藏 ...
- drf框架中分页组件
drf框架中分页组件 普通分页(最常用) 自定制分页类 pagination.py from rest_framework.pagination import PageNumberPagination ...
- plSql使用流程
1. 下载PLSQL developer.instantclient_11_2, 下载地址:https://pan.baidu.com/s/1_MjmIT4nUzsQ7Hi8MCrs1A, 备注:此安 ...