机器学习笔记(十)---- KNN(K Nearst Neighbor)
KNN是一种常见的监督学习算法,工作机制很好理解:给定测试样本,基于某种距离度量找出训练集中与其最靠近的k个训练样本,然后基于这k个“邻居”的信息来进行预测。总结一句话就是“近朱者赤,近墨者黑”。
KNN可用作分类也可用于回归,在分类任务中可使用“投票法”,即选择这k个样本中出现最多的类别标记作为测试结果;在回归任务中可使用“平均法”将这k个样本的标记平均值作为预测结果;还可以基于距离远近进行加权平均或加权投票,距离越近的样本权重越大。
KNN和之前介绍的监督学习算法有一个很大的不同,它没有前期的训练过程,是一种“懒惰学习”的算法,只有收到测试样本后,再和训练样本进行比较处理。
初学者容易把KNN和K-means搞混淆,虽然都有K,:-)但这是两种不同的算法,二者区别如下:
| KNN | K-Means | |
| 不同点 | 是一种分类算法,属于监督学习的范畴,训练数据是带有label的 | 是一种聚类算法,属于非监督学习的范畴,训练数据没有label,杂乱无章的 |
| 没有明显的训练过程,属于lazy learning | 有明确的训练过程 | |
| K的含义:与预测样本距离最近的K个样本 | K的含义:K是事前人工定好的参数,假设数据集可分为K个簇 | |
| 相同点 | 都用到了NN(nearst Neighbor)算法,一般用KD树来实现。 | |
--KNN算法基本原理
KNN算法简单的步骤如下:
(1)计算距离:给定测试对象,计算它与训练集中每个对象的距离,空间距离的计算方法有多种,有欧式距离、夹角余弦(多在文本分类中使用)等。
(2)找邻居:圈定距离最近的k个对象,作为测试对象的近邻。
(3)做分类:根据这k个近邻归属的主要类别,对测试对象进行分类。
下面通过一个简单的示例说明下KNN算法是怎么进行分类的:
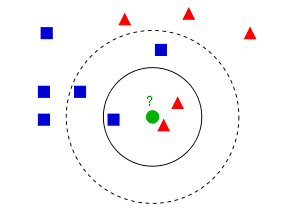
上图的蓝色方块和红色三角是已经打好label的数据,绿色圆圈是待分类的测试数据。
如果我们让K=3,那么上图实心圆圈中的两个三角和一个方块就是离测试数据最近的3个点,那么通过投票法则,测试数据会被分类为红色三角;
如果我们让K=5,那么上图虚线圆圈中的两个三角和三个方块就是离测试数据最近的5个点,通过投票法则,测试数据则会被分类为蓝色方块;
整个算法的原理是不是很简单?但实际上并没有那么简单,K如何选择?数据之间的距离怎么计算?
--K值的选择
如果K值太小,整体模型会变得复杂,容易发生过拟合,容易将一些噪声学习进来,二忽略数据的真实分布。
如果K值过大,模型会变得相对简单,可以减少学习的估计误差,但近似误差会变大,比如极端情况下K=N(N维训练样本数),则不论预测对象是什么,预测结果都将是训练集中最多的类型,这显然是一个过渡简化的模型,无法实际应用。
k值一般采用交叉验证或者Grid Search的方法确定。
--距离计算
提取数据的特征值,根据特征值组成一个n维实数向量空间(特征空间),然后计算向量之间的空间距离,如欧式距离、余弦相似度等。
对于数据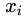 和
和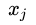 ,其特征空间为n维实数向量空间:
,其特征空间为n维实数向量空间: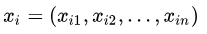 ,
,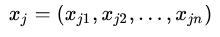
欧式距离计算公式为: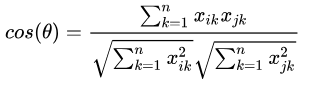
余弦相似度计算公式为: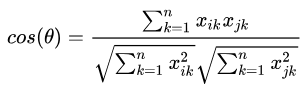
余弦相似度的值越接近1表示其越相似,接近0表示其差异越大。余弦相似度更多应用在文本类任务中。
--代码示例
依旧以sklearn中的cancer数据集为例,做一个通过30维特征判断是否患癌症的示例,示例中数据量很少,只有569条数据,每条数据各有30个特征数值。采用sklearn中的KNN分类器,除k外都采用默认参数,距离度量采用欧式距离 。通过交叉验证法来确定最佳的K值,从下图可见,K=14时,验证准确率最高。

__author__ = 'z00421185'
import pandas as pd
from sklearn import datasets
import matplotlib.pyplot as plt
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
from sklearn.neighbors import KNeighborsClassifier
breast_data = datasets.load_breast_cancer()
data = pd.DataFrame(datasets.load_breast_cancer().data)
data.columns = breast_data['feature_names']
data_np = breast_data['data']
target_np = breast_data['target']
print(data_np.shape)
x_train, x_test, y_train, y_test = train_test_split(data_np, target_np, test_size=0.3, random_state=0)
# 设定交叉验证k的范围,一般从1~样本数的开方
k_range = range(1, 24)
scores = []
for k in k_range:
knn = KNeighborsClassifier(k, metric='euclidean')
score = cross_val_score(knn, x_train, y_train, cv=10, scoring='accuracy')
scores.append(score.mean())
# 从折线图上看最佳K取值
plt.plot(k_range, scores)
plt.xlabel('K')
plt.ylabel('Accuracy')
plt.show()
model = KNeighborsClassifier(n_neighbors=13)
model.fit(x_train, y_train)
y_pred = model.predict(x_test)
print(accuracy_score(y_test, y_pred))
---------------------------------
0.9649122807017544作者:华为云专家 周捷
机器学习笔记(十)---- KNN(K Nearst Neighbor)的更多相关文章
- 机器学习笔记(5) KNN算法
这篇其实应该作为机器学习的第一篇笔记的,但是在刚开始学习的时候,我还没有用博客记录笔记的打算.所以也就想到哪写到哪了. 你在网上搜索机器学习系列文章的话,大部分都是以KNN(k nearest nei ...
- Machine Learning for hackers读书笔记(十)KNN:推荐系统
#一,自己写KNN df<-read.csv('G:\\dataguru\\ML_for_Hackers\\ML_for_Hackers-master\\10-Recommendations\\ ...
- K NEAREST NEIGHBOR 算法(knn)
K Nearest Neighbor算法又叫KNN算法,这个算法是机器学习里面一个比较经典的算法, 总体来说KNN算法是相对比较容易理解的算法.其中的K表示最接近自己的K个数据样本.KNN算法和K-M ...
- 机器学习(四) 分类算法--K近邻算法 KNN (上)
一.K近邻算法基础 KNN------- K近邻算法--------K-Nearest Neighbors 思想极度简单 应用数学知识少 (近乎为零) 效果好(缺点?) 可以解释机器学习算法使用过程中 ...
- 机器学习实战 之 KNN算法
现在 机器学习 这么火,小编也忍不住想学习一把.注意,小编是零基础哦. 所以,第一步,推荐买一本机器学习的书,我选的是Peter harrigton 的<机器学习实战>.这本书是基于pyt ...
- Python机器学习笔记:sklearn库的学习
网上有很多关于sklearn的学习教程,大部分都是简单的讲清楚某一方面,其实最好的教程就是官方文档. 官方文档地址:https://scikit-learn.org/stable/ (可是官方文档非常 ...
- Python机器学习笔记:不得不了解的机器学习面试知识点(1)
机器学习岗位的面试中通常会对一些常见的机器学习算法和思想进行提问,在平时的学习过程中可能对算法的理论,注意点,区别会有一定的认识,但是这些知识可能不系统,在回答的时候未必能在短时间内答出自己的认识,因 ...
- K Nearest Neighbor 算法
文章出处:http://coolshell.cn/articles/8052.html K Nearest Neighbor算法又叫KNN算法,这个算法是机器学习里面一个比较经典的算法, 总体来说KN ...
- Python机器学习笔记:不得不了解的机器学习知识点(2)
之前一篇笔记: Python机器学习笔记:不得不了解的机器学习知识点(1) 1,什么样的资料集不适合用深度学习? 数据集太小,数据样本不足时,深度学习相对其它机器学习算法,没有明显优势. 数据集没有局 ...
随机推荐
- 学习 Git
Git 简介 Git是目前比较流行的分布式版本控制系统之一,能够记录文件的每次修改,还实现了多人并行开发; Git 组成 工作区(写东西之地) 暂存区 本地仓库(.git) 远程仓库(.repro) ...
- 二叉查找树学习笔记(BST)
我土了....终于开始看平衡树了,以前因为害怕一直不敢看数据结构...浑浑噩噩跟同学落了1—2个数据结构没看....果然,我是最弱的 二叉查找树,遵守每个点的左儿子小于点小于右儿子. 于是,BST能够 ...
- 从代码的视角深入浅出理解DevOps
对于DevOps的理解大家众说纷纭,就连维基百科(Wikipedia)都没有给出一个统一的定义.一般的解释都是从字面上来理解,就是把开发(Development)和运维(Operations)整合到一 ...
- 开启docker中的mongodb认证授权
前言: 开启MongoDB服务后,默认是没有权限验证的.直接通过IP加端口就可以远程访问数据库,并对数据库进行任意操作.下面介绍一下如何开启docker中MongoDB的权限认证. 安装完MongoD ...
- nyoj 42-一笔画问题 (欧拉图 && 并查集)
42-一笔画问题 内存限制:64MB 时间限制:3000ms Special Judge: No accepted:10 submit:25 题目描述: zyc从小就比较喜欢玩一些小游戏,其中就包括画 ...
- Serlvet之cookie和session学习
HTTP 协议 Web通信需要一种语言,就像中国人讲中文,欧美说英文,Web使用的HTTP协议,也叫超文本协议. 使用HTTP协议的人分为两类:客户端和服务端.请求资源的角色是客户端,提供资源的是服务 ...
- 【前端知识体系-CSS相关】CSS工程化方案
1.如何解决CSS的模块化问题? 使用Less,Sass等CSS预处理器 使用PostCSS插件(postcss-import/precss) 使用webpack处理CSS(css-loader + ...
- Python常用模块之os.path
os.path.abspath(path) 输入相对路径,返回绝对路径 Python 3.7.0 (v3.7.0:1bf9cc5093, Jun 27 2018, 04:59:51) [MSC v.1 ...
- PostgreSQL空间数据库创建备份恢复(PostGIS vs ArcGIS)
梯子 PostGIS创建备份恢复ArcGIS创建备份恢复 PostGIS 创建 安装就不必介绍了,windows下使用安装工具Application Stack Builder,选择空间扩展PostG ...
- 领扣(LeetCode)转置矩阵 个人题解
给定一个矩阵 A, 返回 A 的转置矩阵. 矩阵的转置是指将矩阵的主对角线翻转,交换矩阵的行索引与列索引. 示例 1: 输入:[[1,2,3],[4,5,6],[7,8,9]] 输出:[[1,4,7] ...