Storm 系列(二)—— Storm 核心概念详解
一、Storm核心概念
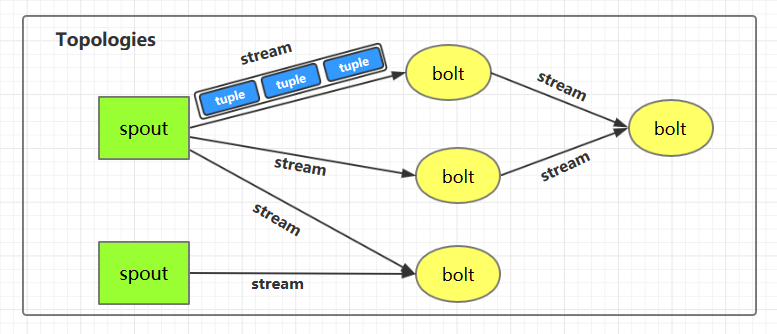
1.1 Topologies(拓扑)
一个完整的 Storm 流处理程序被称为 Storm topology(拓扑)。它是一个是由 Spouts 和 Bolts 通过 Stream 连接起来的有向无环图,Storm 会保持每个提交到集群的 topology 持续地运行,从而处理源源不断的数据流,直到你将主动其杀死 (kill) 为止。
1.2 Streams(流)
Stream 是 Storm 中的核心概念。一个 Stream 是一个无界的、以分布式方式并行创建和处理的 Tuple 序列。Tuple 可以包含大多数基本类型以及自定义类型的数据。简单来说,Tuple 就是流数据的实际载体,而 Stream 就是一系列 Tuple。
1.3 Spouts
Spouts 是流数据的源头,一个 Spout 可以向不止一个 Streams 中发送数据。Spout 通常分为可靠和不可靠两种:可靠的 Spout 能够在失败时重新发送 Tuple, 不可靠的 Spout 一旦把 Tuple 发送出去就置之不理了。
1.4 Bolts
Bolts 是流数据的处理单元,它可以从一个或者多个 Streams 中接收数据,处理完成后再发射到新的 Streams 中。Bolts 可以执行过滤 (filtering),聚合 (aggregations),连接 (joins) 等操作,并能与文件系统或数据库进行交互。
1.5 Stream groupings(分组策略)
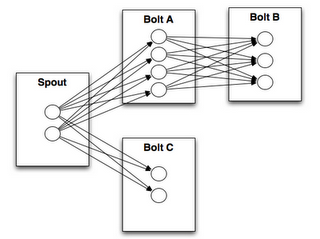
spouts 和 bolts 在集群上执行任务时,是由多个 Task 并行执行 (如上图,每一个圆圈代表一个 Task)。当一个 Tuple 需要从 Bolt A 发送给 Bolt B 执行的时候,程序如何知道应该发送给 Bolt B 的哪一个 Task 执行呢?
这是由 Stream groupings 分组策略来决定的,Storm 中一共有如下 8 个内置的 Stream Grouping。当然你也可以通过实现 CustomStreamGrouping 接口来实现自定义 Stream 分组策略。
Shuffle grouping
Tuples 随机的分发到每个 Bolt 的每个 Task 上,每个 Bolt 获取到等量的 Tuples。
Fields grouping
Streams 通过 grouping 指定的字段 (field) 来分组。假设通过
user-id字段进行分区,那么具有相同user-id的 Tuples 就会发送到同一个 Task。Partial Key grouping
Streams 通过 grouping 中指定的字段 (field) 来分组,与
Fields Grouping相似。但是对于两个下游的 Bolt 来说是负载均衡的,可以在输入数据不平均的情况下提供更好的优化。All grouping
Streams 会被所有的 Bolt 的 Tasks 进行复制。由于存在数据重复处理,所以需要谨慎使用。
Global grouping
整个 Streams 会进入 Bolt 的其中一个 Task,通常会进入 id 最小的 Task。
None grouping
当前 None grouping 和 Shuffle grouping 等价,都是进行随机分发。
Direct grouping
Direct grouping 只能被用于 direct streams 。使用这种方式需要由 Tuple 的生产者直接指定由哪个 Task 进行处理。
Local or shuffle grouping
如果目标 Bolt 有 Tasks 和当前 Bolt 的 Tasks 处在同一个 Worker 进程中,那么则优先将 Tuple Shuffled 到处于同一个进程的目标 Bolt 的 Tasks 上,这样可以最大限度地减少网络传输。否则,就和普通的
Shuffle Grouping行为一致。
二、Storm架构详解
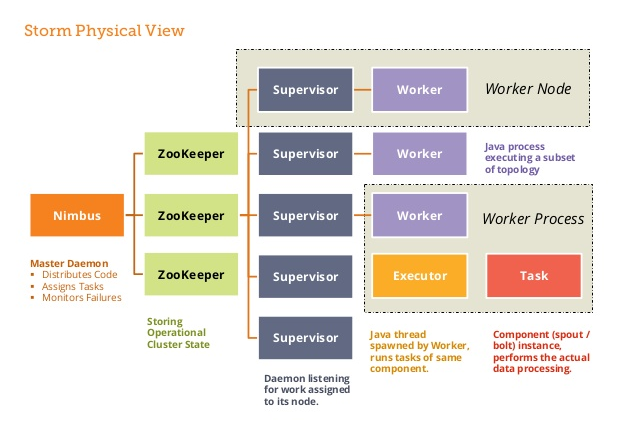
2.1 Nimbus进程
也叫做 Master Node,是 Storm 集群工作的全局指挥官。主要功能如下:
- 通过 Thrift 接口,监听并接收 Client 提交的 Topology;
- 根据集群 Workers 的资源情况,将 Client 提交的 Topology 进行任务分配,分配结果写入 Zookeeper;
- 通过 Thrift 接口,监听 Supervisor 的下载 Topology 代码的请求,并提供下载 ;
- 通过 Thrift 接口,监听 UI 对统计信息的读取,从 Zookeeper 上读取统计信息,返回给 UI;
- 若进程退出后,立即在本机重启,则不影响集群运行。
2.2 Supervisor进程
也叫做 Worker Node , 是 Storm 集群的资源管理者,按需启动 Worker 进程。主要功能如下:
- 定时从 Zookeeper 检查是否有新 Topology 代码未下载到本地 ,并定时删除旧 Topology 代码 ;
- 根据 Nimbus 的任务分配计划,在本机按需启动 1 个或多个 Worker 进程,并监控所有的 Worker 进程的情况;
- 若进程退出,立即在本机重启,则不影响集群运行。
2.3 zookeeper的作用
Nimbus 和 Supervisor 进程都被设计为快速失败(遇到任何意外情况时进程自毁)和无状态(所有状态保存在 Zookeeper 或磁盘上)。 这样设计的好处就是如果它们的进程被意外销毁,那么在重新启动后,就只需要从 Zookeeper 上获取之前的状态数据即可,并不会造成任何数据丢失。
2.4 Worker进程
Storm 集群的任务构造者 ,构造 Spoult 或 Bolt 的 Task 实例,启动 Executor 线程。主要功能如下:
- 根据 Zookeeper 上分配的 Task,在本进程中启动 1 个或多个 Executor 线程,将构造好的 Task 实例交给 Executor 去运行;
- 向 Zookeeper 写入心跳 ;
- 维持传输队列,发送 Tuple 到其他的 Worker ;
- 若进程退出,立即在本机重启,则不影响集群运行。
2.5 Executor线程
Storm 集群的任务执行者 ,循环执行 Task 代码。主要功能如下:
- 执行 1 个或多个 Task;
- 执行 Acker 机制,负责发送 Task 处理状态给对应 Spout 所在的 worker。
2.6 并行度

1 个 Worker 进程执行的是 1 个 Topology 的子集,不会出现 1 个 Worker 为多个 Topology 服务的情况,因此 1 个运行中的 Topology 就是由集群中多台物理机上的多个 Worker 进程组成的。1 个 Worker 进程会启动 1 个或多个 Executor 线程来执行 1 个 Topology 的 Component(组件,即 Spout 或 Bolt)。
Executor 是 1 个被 Worker 进程启动的单独线程。每个 Executor 会运行 1 个 Component 中的一个或者多个 Task。
Task 是组成 Component 的代码单元。Topology 启动后,1 个 Component 的 Task 数目是固定不变的,但该 Component 使用的 Executor 线程数可以动态调整(例如:1 个 Executor 线程可以执行该 Component 的 1 个或多个 Task 实例)。这意味着,对于 1 个 Component 来说,#threads<=#tasks(线程数小于等于 Task 数目)这样的情况是存在的。默认情况下 Task 的数目等于 Executor 线程数,即 1 个 Executor 线程只运行 1 个 Task。
总结如下:
- 一个运行中的 Topology 由集群中的多个 Worker 进程组成的;
- 在默认情况下,每个 Worker 进程默认启动一个 Executor 线程;
- 在默认情况下,每个 Executor 默认启动一个 Task 线程;
- Task 是组成 Component 的代码单元。
参考资料
更多大数据系列文章可以参见 GitHub 开源项目: 大数据入门指南
Storm 系列(二)—— Storm 核心概念详解的更多相关文章
- Velocity魔法堂系列二:VTL语法详解
一.前言 Velocity作为历史悠久的模板引擎不单单可以替代JSP作为Java Web的服务端网页模板引擎,而且可以作为普通文本的模板引擎来增强服务端程序文本处理能力.而且Velocity被移植到不 ...
- Zookeeper系列二:分布式架构详解、分布式技术详解、分布式事务
一.分布式架构详解 1.分布式发展历程 1.1 单点集中式 特点:App.DB.FileServer都部署在一台机器上.并且访问请求量较少 1.2 应用服务和数据服务拆分 特点:App.DB.Fi ...
- Storm 学习之路(二)—— Storm核心概念详解
一.Storm核心概念 1.1 Topologies(拓扑) 一个完整的Storm流处理程序被称为Storm topology(拓扑).它是一个是由Spouts 和Bolts通过Stream连接起来的 ...
- ZooKeeper 系列(一)—— ZooKeeper核心概念详解
一.Zookeeper简介 二.Zookeeper设计目标 三.核心概念 3.1 集群角色 3.2 会话 3.3 数据节点 3.4 节点 ...
- Solr系列二:solr-部署详解(solr两种部署模式介绍、独立服务器模式详解、SolrCloud分布式集群模式详解)
一.solr两种部署模式介绍 Standalone Server 独立服务器模式:适用于数据规模不大的场景 SolrCloud 分布式集群模式:适用于数据规模大,高可靠.高可用.高并发的场景 二.独 ...
- Maven系列二setting.xml 配置详解
文件存放位置 全局配置: ${M2_HOME}/conf/settings.xml 用户配置: ${user.home}/.m2/settings.xml note:用户配置优先于全局配置.${use ...
- Maven 专题(六):Maven核心概念详解(二)
5 仓库 5.1 分类 [1]本地仓库:为当前本机电脑上的所有 Maven 工程服务.[2]远程仓库: (1)私服:架设在当前局域网环境下,为当前局域网范围内的所有 Maven 工程服务 ...
- Maven 专题(五):Maven核心概念详解(一)
**Maven 的核心程序中仅仅定义了抽象的生命周期,而具体的操作则是由 Maven 的插件来完成的.**可是 Maven 的插件并不包含在 Maven 的核心程序中,在首次使用时需要联网下载. 下载 ...
- Java 虚拟机系列二:垃圾收集机制详解,动图帮你理解
前言 上篇文章已经给大家介绍了 JVM 的架构和运行时数据区 (内存区域),本篇文章将给大家介绍 JVM 的重点内容--垃圾收集.众所周知,相比 C / C++ 等语言,Java 可以省去手动管理内存 ...
随机推荐
- junit的Test不能使用,报错信息:Test is not an annotation type
在使用junit的Test做测试时,注解@Test报错”Test is not an annotation type”,发现是因为测试类的类名命名为了Test,所以导致错误. 测试类类名不能直接命名为 ...
- 最短代码实现包含100个key的字典,且每个value值不同
最短代码实现包含100个key的字典,且每个value值不同 {x:x*2 for x in range(100)}
- web设计_5_自由的框式组件
1. CSS3 border-radius 圆角矩形框 圆角矩形框组件是页面布局中常常用到的,利用CSS3的border-radius可非常方便的创建. 并且在横向纵向上面都有很好的扩展性和灵活性. ...
- Python中的inf与nan
Python中可以用如下方式表示正负无穷 >>> float('inf') # 正无穷,inf不区分大小写,float('InF')一样可以. inf >>> fl ...
- 再记一次经典Net程序的逆向过程
1.前言 上次发完,有网友问了一个问题:如果不绕过编译,而是直接编译怎么办? 记一次Net软件逆向的过程:https://www.cnblogs.com/dotnetcrazy/p/10142315. ...
- Ubuntu 执行chmod -R 777 / 挽救方法
mgj怎么会有堪比rm -rf /*这样神奇的命令,本想着把当前目录下的权限改为777,没想到把整个/目录下全设成777了,直觉告诉我好像哪里有些不对劲,好在一顿xjb折腾最终弄好了,应该没啥大问题, ...
- <<Modern CMake>> 翻译 2.4 项目目录结构
<<Modern CMake>> 翻译 2.4 项目目录结构 本节内容有点跑题.但我认为这是一个很好的方法. 我将告诉你如何规划项目的目录. 这是基于惯例,但将帮助您: 轻松阅 ...
- js中slice和splice的区别
言简意赅,直接上货. slice():该方法会返回一个新的数组,强调:新数组,并不会影响原来的数组.先来看看语法咋说:arrayObject.slice(start,end).其中,start必需,e ...
- Powered by .NET Core 进展:用 docker-compose 验证高并发问题嫌疑犯 docker swarm
相关博文: [故障公告]发布 .NET Core 版博客站点引起大量 500 错误 [网站公告].NET Core 版博客站点第二次发布尝试 暴风雨中的 online : .NET Core 版博客站 ...
- 一文了解:Redis的AOF持久化
Redis的AOF持久化 每当Redis-Server接收到写数据时,就把命令以文本形式追加到AOF文件里,当重启Redis服务时,AOF文件里的命令会被重新执行一次,重新恢复数据.当AOF过大时将重 ...