将CDH中的hive和hbase相互整合使用
一、.hbase与hive的兼容版本:
hive0.90与hbase0.92是兼容的,早期的hive版本与hbase0.89/0.90兼容,不需要自己编译。
hive1.x与hbase0.98.x或则更低版本是兼容的,不需要自己编译。
hive2.x与hbase1.x及比hbase1.x更高版本兼容,不需要自己编译。
hive 1.x 与 hbase 1.x整合时,需要自己编译
二、.hbase与hive的整合过程:
1.修改 hive 的conf目录下 hive-site.xml文件
<property>
<name>hive.zookeeper.quorum</name>
<value>node1,node2,node3</value>
</property>
<property>
<name>hive.server2.enable.doAs</name>
<value>false</value>
</property>
1.可通过Hive -> 操作 -> 下载客户端配置 的方式查看hive-site.xml文件内容,可得知 hive.zookeeper.quorum 配置的内容,默认配置即为 node1,node2,node3 即可。
2.可得知 hive.server2.enable.doAs 默认为 true,推荐修改为false,否则在使用官方推荐的hiveserver2/beeline的方式操作时,在利用HQL语句创建HBase时可能会出现异常。
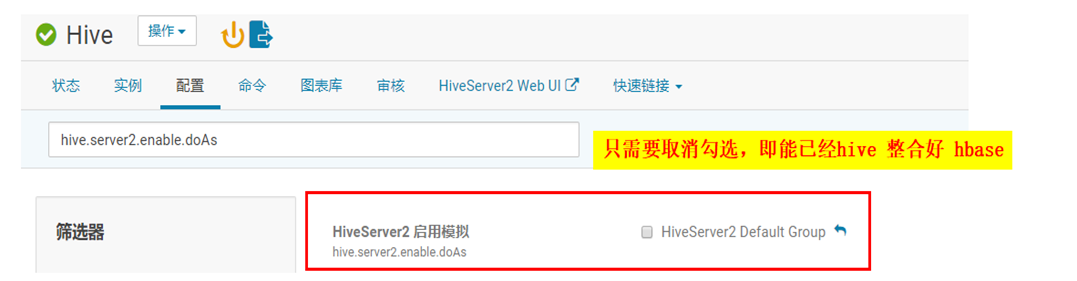
3.可通过Hive -> 配置 -> 搜索栏中搜索 hive.server2.enable.doAs ,默认为勾选,取消勾选即可,即能修改配置为 false。
再当我们通过Hive -> 操作 -> 下载客户端配置 的方式查看hive-site.xml文件内容,即可查看到hive.server2.enable.doAs已为false
2.重启 hive、hbase
3.使用命令 beeline -u jdbc:hive2://node1:10000 -n root 进行连接
4.HIVE执行创建表语句:hbase表 映射 hive表,写入的数据存储在 hbase表中,"hbase.mapred.output.outputtable"可指定数据写入到hbase表中
1.create database rimengshe;
2.use rimengshe;
3.创建hive表的同时也会创建出hbase表
# Hive中的表名test_tb;key字段映射hbase表中的rowkey;value字段映射cf1列簇下的val字段
CREATE TABLE ushio(key int, value string)
# 指定存储处理器
STORED BY 'org.apache.hadoop.hive.hbase.HBaseStorageHandler'
# 声明列簇,列名
WITH SERDEPROPERTIES ("hbase.columns.mapping" = ":key,cf1:val")
# hbase.table.name声明HBase表名,为可选属性默认与Hive的表名相同
# hbase.mapred.output.outputtable指定插入数据时写入的表,如果以后需要往该表插入数据就需要指定该值
TBLPROPERTIES ("hbase.table.name" = "ushio", "hbase.mapred.output.outputtable" = "ushio");
3.hbase表中添加数据:put '表名','rowkey值','列簇名:列名','列值'
put 'ushio','98','cf1:val','val_98'
put 'ushio','99','cf1:val','val_99'
put 'ushio','100','cf1:val','val_100'
4.hive表中添加数据:(会运行yarn)INSERT INTO table_name (field1, field2,...fieldN ) VALUES (value1, value2,...valueN );
insert into ushio values(2,'ushio');
5.hbase表 查询表中的所有数据:scan '表名'
scan 'ushio'
6.hive表 查询表中的所有数据:
select * from ushio;
将CDH中的hive和hbase相互整合使用的更多相关文章
- hive与hbase的整合
Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供完整的sql查询功能,可以将sql语句转换为MapReduce任务进行运行.其优点学习成本低,可以通过类S ...
- Hive与Hbase关系整合
近期工作用到了Hive与Hbase的关系整合,虽然从网上参考了很多的资料,但是大多数讲的都不是很细,于是决定将这块知识点好好总结一下供大家分享,共同掌握! 本篇文章在具体介绍Hive与Hbase整合之 ...
- Hadoop Hive与Hbase关系 整合
用hbase做数据库,但因为hbase没有类sql查询方式,所以操作和计算数据很不方便,于是整合hive,让hive支撑在hbase数据库层面 的 hql查询.hive也即 做数据仓库 1. 基于Ha ...
- Hadoop Hive与Hbase整合+thrift
Hadoop Hive与Hbase整合+thrift 1. 简介 Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供完整的sql查询功能,可以将sql语句 ...
- 数据导入(一):Hive On HBase
Hive集成HBase可以有效利用HBase数据库的存储特性,如行更新和列索引等.在集成的过程中注意维持HBase jar包的一致性.Hive与HBase的整合功能的实现是利用两者本身对外的API接口 ...
- 集成Hive和HBase
1. MapReduce 用MapReduce将数据从本地文件系统导入到HBase的表中, 比如从HBase中读取一些原始数据后使用MapReduce做数据分析. 结合计算型框架进行计算统计查看HBa ...
- hive和hbase整合的原因和原理
为什么要进行hive和hbase的整合? hive是高延迟.结构化和面向分析的: hbase是低延迟.非结构化和面向编程的. Hive集成Hbase就是为了使用hbase的一些特性.或者说是中和它们的 ...
- 大数据工具篇之Hive与HBase整合完整教程
大数据工具篇之Hive与HBase整合完整教程 一.引言 最近的一次培训,用户特意提到Hadoop环境下HDFS中存储的文件如何才能导入到HBase,关于这部分基于HBase Java API的写入方 ...
- 十、Hadoop学习笔记————Hive与Hbase以及RDBMS(关系型数据库)的关系
Hive目的是为了简化MapReduce编程 实际应用中,Hive与Hbase不经常链接
随机推荐
- C#代码实现IoC(控制反转)设计,以及我对IoC的理解
一. 什么是IoC 当在A类中要使用B类的时候,我们一般都是采用new的方式来实例化B类,这样一来这两个类就有很强的依赖关系,不符合低耦合的设计思想.这时候我们可以通过一个中间容器来实例化对象,需要的 ...
- 利用window对象下内置的子对象实现网页的刷新
这里我们用到的window对象下内置的子对象有: 1.history对象:包含浏览器访问过的url.我们可以利用它的history.go(num);属性实现页面的刷新: h ...
- 在 react 项目里如何配合immutable在redux中使用
一.reducer文件的处理 先安装 immutable 与 redux-immutable yarn add immutable redux-immutable 我们可能会在很多地方定义子树,这就需 ...
- 安装Python及各种包/库——没有网络的电脑上
我们做项目时可能会遇到,一些电脑只能联内网或者无法联网,这种情况怎样在电脑上安装Python及各种第三方包/库呢? 1.首先,在有网络的电脑上在python官网下载好python安装包,地址:http ...
- 【第一篇】spring boot 快速入门
1.开发环境 开发工具:IDEA2018.2.1 JDK:1.9 Maven : 3.3.9 操作系统:window 7 / window 10 2.项目结构 3.详细步骤 3.1 使用IDEA新建M ...
- 关于hashCode方法的作用
想要明白hashCode的作用,你必须要先知道Java中的集合. 总的来说,Java中的集合(Collection)有两类,一类是List,再有一类是Set. 你知道它们的区别吗?前者集合内的元素是有 ...
- bzoj 4025 二分图 lct
题目传送门 题解: 首先关于二分图的性质, 就是没有奇环边. 题目其实就是让你判断每个时段之内有没有奇环. 其次 lct 只能维护树,(反正对于我这种菜鸟选手只会维护树), 那么对于一棵树来说, 填上 ...
- Atcoder E - Meaningful Mean(线段树+思维)
题目链接:http://arc075.contest.atcoder.jp/tasks/arc075_c 题意:问数组a有多少子区间平均值为k 题解:一开始考虑过dp,但是显然不可行,其实将每一个数都 ...
- 线段树模板 hdu 1166 敌兵布阵
敌兵布阵 Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 65536/32768 K (Java/Others)Total Submis ...
- Pytorch读取,加载图像数据(一)
在学习Pytorch的时候,先学会如何正确创建或者加载数据,至关重要. 有了数据,很多函数,操作的效果就变得很直观. 本文主要用其他库读取图像文件(学会这个,你就可以在之后的学习中,将一些效果直观化) ...