Master和worker模式
让和hadoop的设计思想是一样的,Master负责分配任务和获取任务的结果,worker是真正处理业务逻辑的。
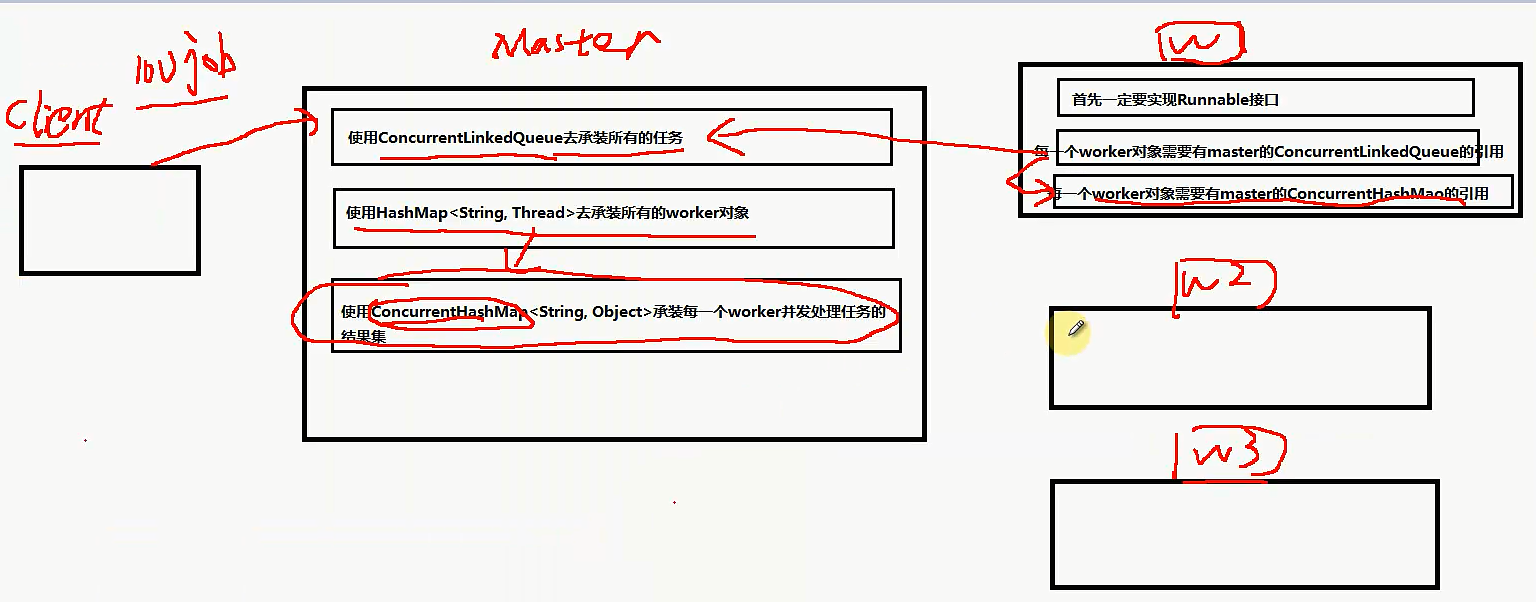
使用ConcurrentLikedQueue去承载所有的任务,因为会有多个worker会并发修改这个队列。
public class Task {
private int id;
private int price ;
public int getId() {
return id;
}
public void setId(int id) {
this.id = id;
}
public int getPrice() {
return price;
}
public void setPrice(int price) {
this.price = price;
}
}
public class Master {
//1 有一个盛放任务的容器
private ConcurrentLinkedQueue<Task> workQueue = new ConcurrentLinkedQueue<Task>();
//2 需要有一个盛放worker的集合
private HashMap<String, Thread> workers = new HashMap<String, Thread>();
//3 需要有一个盛放每一个worker执行任务的结果集合
private ConcurrentHashMap<String, Object> resultMap = new ConcurrentHashMap<String, Object>();
//4 构造方法
public Master(Worker worker , int workerCount){
worker.setWorkQueue(this.workQueue);
worker.setResultMap(this.resultMap);
for(int i = 0; i < workerCount; i ++){
this.workers.put(Integer.toString(i), new Thread(worker));
}
}
//5 需要一个提交任务的方法
public void submit(Task task){
this.workQueue.add(task);
}
//6 需要有一个执行的方法,启动所有的worker方法去执行任务
public void execute(){
for(Map.Entry<String, Thread> me : workers.entrySet()){
me.getValue().start();
}
}
//7 判断是否运行结束的方法
public boolean isComplete() {
for(Map.Entry<String, Thread> me : workers.entrySet()){
if(me.getValue().getState() != Thread.State.TERMINATED){
return false;
}
}
return true;
}
//8 计算结果方法
public int getResult() {
int priceResult = 0;
for(Map.Entry<String, Object> me : resultMap.entrySet()){
priceResult += (Integer)me.getValue();
}
return priceResult;
}
}
public class Worker implements Runnable {
private ConcurrentLinkedQueue<Task> workQueue;
private ConcurrentHashMap<String, Object> resultMap;
public void setWorkQueue(ConcurrentLinkedQueue<Task> workQueue) {
this.workQueue = workQueue;
}
public void setResultMap(ConcurrentHashMap<String, Object> resultMap) {
this.resultMap = resultMap;
}
@Override
public void run() {
while(true){
Task input = this.workQueue.poll();
if(input == null) break;
Object output = handle(input);
this.resultMap.put(Integer.toString(input.getId()), output);
}
}
private Object handle(Task input) {
Object output = null;
try {
//处理任务的耗时。。 比如说进行操作数据库。。。
Thread.sleep(500);
output = input.getPrice();
} catch (InterruptedException e) {
e.printStackTrace();
}
return output;
}
}
public class Main {
public static void main(String[] args) {
Master master = new Master(new Worker(), 20);
Random r = new Random();
for(int i = 1; i <= 100; i++){
Task t = new Task();
t.setId(i);
t.setPrice(r.nextInt(1000));
master.submit(t);
}
master.execute();
long start = System.currentTimeMillis();
while(true){
if(master.isComplete()){
long end = System.currentTimeMillis() - start;
int priceResult = master.getResult();
System.out.println("最终结果:" + priceResult + ", 执行时间:" + end);
break;
}
}
}
}
Master和worker模式的更多相关文章
- Spark技术内幕:Client,Master和Worker 通信源码解析
http://blog.csdn.net/anzhsoft/article/details/30802603 Spark的Cluster Manager可以有几种部署模式: Standlone Mes ...
- Spark技术内幕:Client,Master和Worker 通信源代码解析
Spark的Cluster Manager能够有几种部署模式: Standlone Mesos YARN EC2 Local 在向集群提交计算任务后,系统的运算模型就是Driver Program定义 ...
- Apache的prefork模式和worker模式(转)
prefork模式这个多路处理模块(MPM)实现了一个非线程型的.预派生的web服务器,它的工作方式类似于Apache 1.3.它适合于没有线程安全库,需要避免线程兼容性问题的系统.它是要求将每个请求 ...
- Apache的prefork模式和worker模式
prefork模式这个多路处理模块(MPM)实现了一个非线程型的.预派生的web服务器,它的工作方式类似于Apache 1.3.它适合于没有线程安全库,需要避免线程兼容性问题的系统.它是要求将每个请求 ...
- Spark中master与worker的进程RPC通信实现
1.构建master的actor package SparkRPC import akka.actor.{Actor, ActorSystem, Props}import com.typesafe.c ...
- Spark分析之Master、Worker以及Application三者之间如何建立连接
Master.preStart(){ webUi.bind() context.system.scheduler.schedule( millis, WORKER_TIMEOUT millis, se ...
- [PHP] apache在worker模式配置fastcgi使用php-fpm
1.准备: dpkg -L apache2查看所有安装的apache2的应用 a2query -M查看apache2使用的模式 httpd -l旧版本查看当前apache模式 2.查看apache的进 ...
- redis配置master-slave模式
由于云服务器存在闪断现象,项目线上会存在基于redis的功能在闪断时段内出现异常,所以redis需要做master-slave模式.直接上代码: 原单机redis,RedisConnectionFac ...
- Ubuntu下配置Apache的Worker模式
其实Apache本身的并发能力是足够强大的,但是Ubuntu默认安装的是Prefork模式下的Apache.所以导致很多人后面盲目的去 安装lighttpd或者nginx一类替代软件.但是这类软件有一 ...
随机推荐
- springcloud之Hystrix
1.Hystrix出现的背景 从上面看来,Hystrix避免了雪崩效益,对于失败的服务可以快速失败. 2.为了解决雪崩效应的解决方案: (1)超时机制 (2)断路器模式Hystrix 3.Hystri ...
- UML类图与类间六种关系表示
UML类图与类间六种关系表示 1.类与类图 类封装了数据和行为,是面向对象的重要组成部分,它是具有相同属性,操作,关系的对象集合的总称. 类图是使用频率最高的UML图之一. 类图用于描述系统中所包含的 ...
- 静态常量整数成员在class内部直接初始化
#include <vector> #include <deque> #include <algorithm> #include <iostream> ...
- Rsync实现文件同步的算法(转载)
Rsync文件同步的核心算法 文章出处:http://coolshell.cn/articles/7425.html#more-7425 rsync是unix/linux下同步文件的一个高效算法,它能 ...
- NO.2day 操作系统基础
操作系统基础 1.为什么要有操作系统 操作系统为用户程序提供一个更好.更简单.更清晰的计算机模型,并管理刚才提到的所有设备(磁盘.内存.显示器.打印机等).程序员无法把所有的硬件操作细节都了解到,管理 ...
- Java泛型底层源码解析-ArrayList,LinkedList,HashSet和HashMap
声明:以下源代码使用的都是基于JDK1.8_112版本 1. ArrayList源码解析 <1. 集合中存放的依然是对象的引用而不是对象本身,且无法放置原生数据类型,我们需要使用原生数据类型的包 ...
- python中高阶函数与装饰器(2)
函数返回值为内置函数名: def sum(*args): def sum_in(): ax = 0 for n in args: ax = ax ...
- JVM体系结构和工作方式
JVM能够跨计算机体系结构来执行Java字节码,主要是由于JVM屏蔽了与各个计算机平台相关的软件或者是硬件之间的差异,使得与平台相关的耦合统一由JVM提供者来实现. 何为JVM ...
- 豪迈开料锯MDB文件分析
豪迈CuteRite(简称CR)优化板件后会生成SAW文件.MDB文件,SAW文件用于开料机开料,MDB文件中保存了有限的优化结果记录. 因为CR软件可以根据配置生成不同结构的mdb文件,所以以下内容 ...
- bayer, yuv, RGB转换方法
因为我的STVxxx USB camera输出格式是bayer格式,手头上只有YUVTOOLS这个查看工具,没法验证STVxxx在开发板上是否正常工作. 网上找了很久也没找到格式转换工具,最后放弃了, ...