SKLearn数据集API(一)
注:本文是人工智能研究网的学习笔记
数据集一览
| 类型 | 获取方式 |
|---|---|
| 自带的小数据集 | sklearn.datasets.load_ |
| 在线下载的数据集 | sklearn.datasets.fetch_ |
| 计算机生成的数据集 | sklearn.datasets.make_ |
| svmlight/libsvm格式的数据集 | sklearn.datasets.load_svmlight_file(...) |
| mldata.org在线下载数据集 | sklearn.datasets.fetch_mldata(...) |
自带的小数据集
返回的是bunch对象,是字典类型
| 名称 | 数据包 |
|---|---|
| 鸢尾花数据集 | load_iris() |
| 乳腺癌数据集 | load_breast_cancer() |
| 手写数字数据集 | load_digits() |
| 糖尿病数据集 | load_diabetes() |
| 波士顿房价数据集 | load_boston() |
| 体能训练数据集 | load_linnerud() |
| 图像数据集 | load_sample_image(name) |
鸢尾花数据集
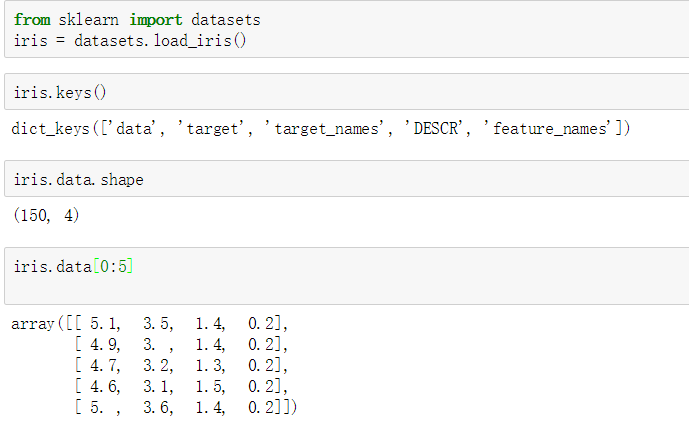
下面使用花萼长度单个特征来划分查看,这是探索性分析,当我们不知道该使用那些特征的时候,就这样查看一下。
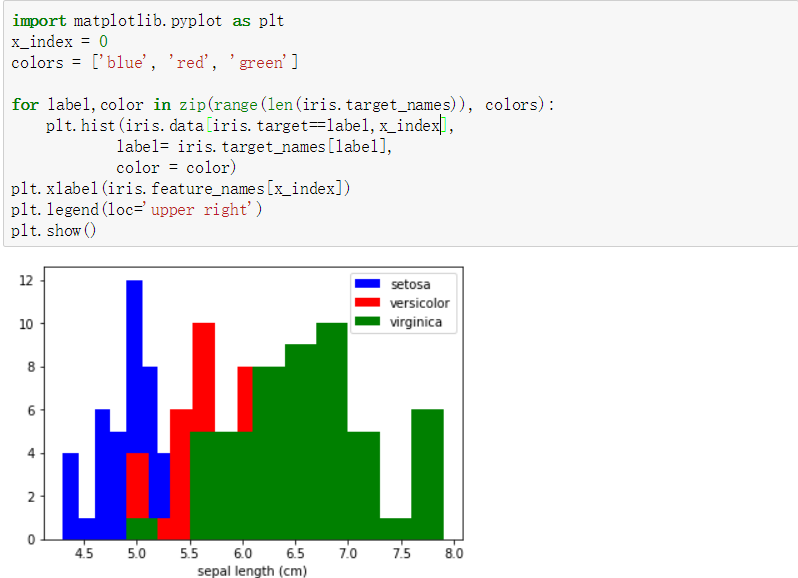
下面使用两个特征来划分查看
手写数字数据集

图像数据集

在线下载的数据集
使用datasets.get_data_home()函数获取下载目录
| 类型 | 获取方式 |
|---|---|
| 20类新闻文本数据集 | fetch_20newsgroups() / fetch_20newsgroups_vectorized() |
| 野外带标记人脸数据集 | fetch_lfw_people() / fetch_lfw_pairs() |
| Olivetti人脸数据集 | fetch_olivetti_faces() |
| rcvl多标签数据集 | fetch_rcvl() |
| 加利福尼亚房价数据集 | fetch_canlifornia_housing() |
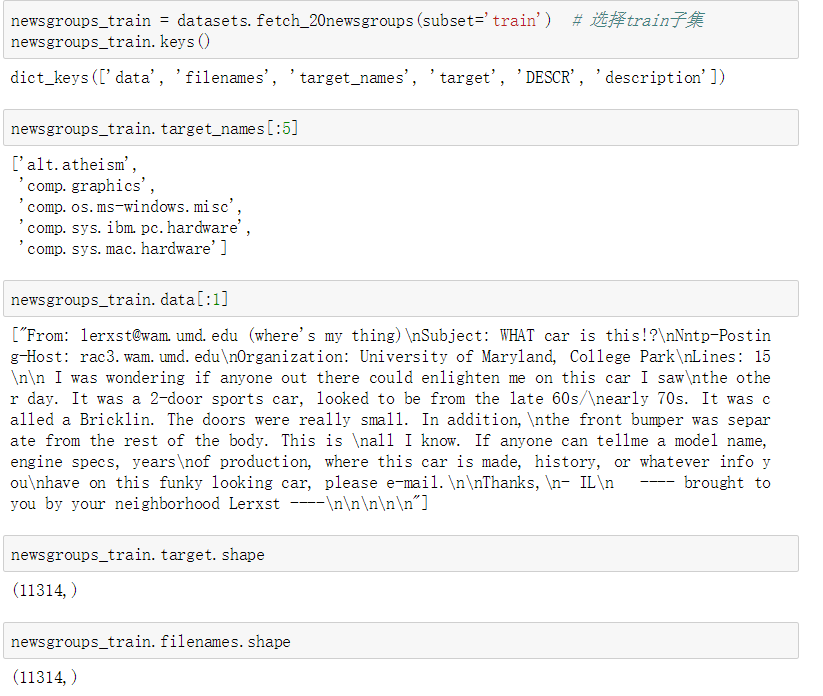
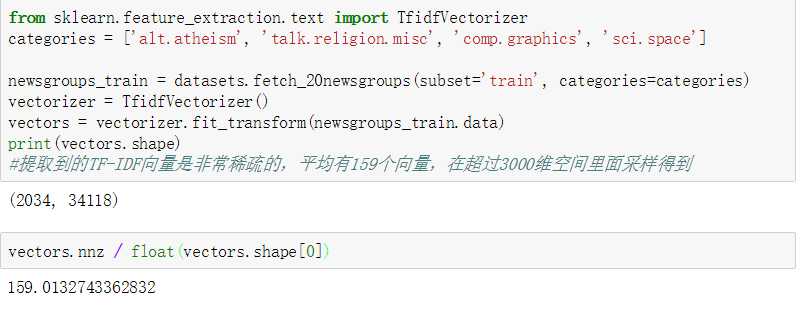
20类新闻文本数据集
包含了关于20个话题(topic)的18000条新闻报道,被分为两个子集: 训练集和测试集
| 函数 | 内容 |
|---|---|
| fetch_20newsgroups() | 原始的文本列表,该文本可以被输入到文本特征提取器sklearn.feature_extraction.text.CountVectorizer进一步处理得到特征向量 |
| fetch_20newsgroups_vectorized() | 返回一个直接可以使用的特征,无须在进行特征提取。 |
Olivetti人脸数据集
Olivetti人脸数据集是AT&T在1992-1994年手机的人脸数据集,包含了40个不同的目标,每个目标10张图片,某些目标的图像在不同的时间段采集,带有光照,面部表情(眼镜开闭,笑容),面部袭细节的各种变化,所有的人脸图像被正立的放在一个灰色的背景上。
每一张图像上有256个灰度级,用无符号8为来存。加载函数会将所有的图像转换成[0,1]区间上的浮点数,目标值target存放着0到39的数字代表人脸的类别标签。然而每个标签对应的人脸图像都只有10张,每张图像的分辨率是64*64。这个小数据集会更加适合来做无监督学习或者半监督学习。
SKLearn数据集API(一)的更多相关文章
- SKLearn数据集API(二)
注:本文是人工智能研究网的学习笔记 计算机生成的数据集 用于分类任务和聚类任务,这些函数产生样本特征向量矩阵以及对应的类别标签集合. 数据集 简介 make_blobs 多类单标签数据集,为每个类分配 ...
- 【学习笔记】sklearn数据集与估计器
数据集划分 机器学习一般的数据集会划分为两个部分: 训练数据:用于训练,构建模型 测试数据:在模型检验时使用,用于评估模型是否有效 训练数据和测试数据常用的比例一般为:70%: 30%, 80%: 2 ...
- sklearn——数据集调用及应用
忙了许久,总算是又想起这边还没写完呢. 那今天就写写sklearn库的一部分简单内容吧,包括数据集调用,聚类,轮廓系数等等. 自带数据集API 数据集函数 中文翻译 任务类型 数据规模 load_ ...
- Sklearn数据集与机器学习
sklearn数据集与机器学习组成 机器学习组成:模型.策略.优化 <统计机器学习>中指出:机器学习=模型+策略+算法.其实机器学习可以表示为:Learning= Representati ...
- 机器学习笔记(四)--sklearn数据集
sklearn数据集 (一)机器学习的一般数据集会划分为两个部分 训练数据:用于训练,构建模型. 测试数据:在模型检验时使用,用于评估模型是否有效. 划分数据的API:sklearn.model_se ...
- sklearn数据集
数据集划分: 机器学习一般的数据集会划分为两个部分 训练数据: 用于训练,构建模型 测试数据: 在模型检验时使用,用于评估模型是否有效 sklearn数据集划分API: 代码示例文末! scikit- ...
- sklearn python API
sklearn python API LinearRegression from sklearn.linear_model import LinearRegression # 线性回归 # modul ...
- sklearn数据集划分
sklearn数据集划分方法有如下方法: KFold,GroupKFold,StratifiedKFold,LeaveOneGroupOut,LeavePGroupsOut,LeaveOneOut,L ...
- 深度学习常用数据集 API(包括 Fashion MNIST)
基准数据集 深度学习中经常会使用一些基准数据集进行一些测试.其中 MNIST, Cifar 10, cifar100, Fashion-MNIST 数据集常常被人们拿来当作练手的数据集.为了方便,诸如 ...
随机推荐
- tmux终端工具
本文原始地址:http://www.cnblogs.com/chinas/p/7094172.html,转载请注明出处,谢谢!!! 1.介绍 tmux(终端复用工具):一个很有趣的工具,类似GNU S ...
- Linux基础-host文件解析
任务目标:为集群内的机器设定主机名,利用/etc/hosts文件来解析自己的集群中所有的主机名, 相应的集群的配置应该改成使用主机名的方式 使用 hostnamectl set-hostname 设定 ...
- dockerfile创建镜像及容器
第一步: 从王总git上:http://git.oursdata.com/wangyue/dockerfiles.git 进入下图的文件夹中 然后执行以下的说明执行步骤 第二步: 开发环境dock ...
- 状压dp(B - 炮兵阵地 POJ - 1185 )
题目链接:https://cn.vjudge.net/contest/276236#problem/B 题目大意:略 具体思路:和我的上一篇写状压dp的思路差不多,不过就是这个题相当于上一个题的升级 ...
- Linux机器如何在公司内网配置代理
一.通过上网认证 必须在图形界面下使用浏览器(如Firefox)完成上网认证过程. 请先确保本机已经可以正常访问公司内部网络. Firefox上配置代理: 1)打开Firefox首选项,[高级]-[网 ...
- RabbitMQ--work queues(二)
封装一个task到一个message,并发送到queue.consumer会去除task并执行这个task. 这里我们简化了操作,发送消息到队列中,consumer取出消息计算里面'.'号有几个就sl ...
- 神经网络中的激活函数tanh sigmoid RELU softplus softmatx
所谓激活函数,就是在神经网络的神经元上运行的函数,负责将神经元的输入映射到输出端.常见的激活函数包括Sigmoid.TanHyperbolic(tanh).ReLu. softplus以及softma ...
- kickstart配置LINUX无人值守选项--rootpw
linux kickstart rootpw密码可以使用明文,也可以使用加密过的值(密码为:IPPBXADMINROOT) 注意:在这里要使用加密过的值,否则安全性就太低了 rootpw --iscr ...
- SQL SERVER2008 镜像全攻略
--在非域控环境中创建数据库镜像, 我们必须使用证书来创建数据库镜像. 大致的步骤包括: --在为数据库镜像配置的每个服务器实例上执行下列步骤: --在 master 数据库中,创建数据库主密钥. - ...
- MySQL学习笔记:case when
一.MySQL case when的三种用法: 1.case 字段 when, 字段的具体值: select a.*, case sex when '1' then '男' else '女' end ...