MapReduce实例2(自定义compare、partition)& shuffle机制
MapReduce实例2(自定义compare、partition)& shuffle机制
实例:统计流量
有一份流量数据,结构是:时间戳、手机号、...、上行流量、下行流量,需求是统计每个用户(手机号)的总上行、总下行以及总流量数值。
分析
由于希望的输出是一个 {手机号 上行流量 下行流量 总流量} 这样的结构,所以需要写个javabean把它们封装成一个类。
private String phoneNum;
private long upFlow;
private long downFlow;
private long sumFlow;
(以及一堆setter和getter函数)
为了初始化方便,写个带参的构造函数,但是在反序列化时,由于反射机制需要调用的是无参数的构造函数,所以必须再手动多加一个。
public FlowBean() {};
public FlowBean(String phoneNum, long upFlow, long downFlow) {
this.phoneNum = phoneNum;
this.upFlow = upFlow;
this.downFlow = downFlow;
this.sumFlow = upFlow + downFlow;
}
然后,分析整个MapReduce要怎么做。
mappper要做的事:按'\t'切分数据,然后输出的key是读到这行的phone number,value是这个javabean。
reducer要做的事:遍历拿到的所有javabean,取出上行流量和下行流量累加起来,输出的key还是从mapper传来的那个phone number,value是用总的上行和下行流量构造的一个新的javabean。
在runner中,相较上一次的demo这次代码是更规范的写法,不要直接在main里定义和描述job然后就瞎跑了,而是先重载写run类,然后在main里调用 ToolRunner.run 。
然后输入输出路径这里也写成动态的获取输入参数(args[0]、args[1])。
@Override
public int run(String[] args) throws Exception {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
job.setJarByClass(FlowSumRunner.class);
job.setMapperClass(FlowSumMapper.class);
job.setReducerClass(FlowSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(FlowBean.class);
FileInputFormat.setInputPaths(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
return job.waitForCompletion(true) ? 0 : 1;
}
public static void main(String[] args) throws Exception {
int res = ToolRunner.run(new Configuration(), new FlowSumRunner(), args);
System.exit(res);
}
MapReduce的流程就是这样了。
但是之前那个javabean还没完。由于该类是我们新构造的,而且作为MR程序中的数据一样的需要在各结点中传输,所以这时候只能自己去做序列化和反序列化的工作了(write():序列化、readFields():反序列化)。
//将对象数据序列化到流中
@Override
public void write(DataOutput out) throws IOException {
out.writeUTF(phoneNum);
out.writeLong(upFlow);
out.writeLong(downFlow);
out.writeLong(sumFlow);
}
//从数据流中反序列出对象的数据(必须跟序列化时的顺序保持一致)
@Override
public void readFields(DataInput in) throws IOException {
phoneNum = in.readUTF();
upFlow = in.readLong();
downFlow = in.readLong();
sumFlow = in.readLong();
}
并且,在context.write()的时候调用的是对象是toSrting()方法,如果没有给这个bean重载一下那么输出的会是对象ID而非我们需要的手机号、上下行流量那些。
public String toString() {
return " " + upFlow + "\t" + downFlow + "\t" + sumFlow;
}
加需求1:自定义排序
原本自带的默认排序方式是按照mapper输出的那个key的字典序递增的排。加个需求:输出不要按照默认的手机号递增排序,而是按照总流量从高到低排序。
分析
既然本身就是按key排序,那首先想到的是把FlowBean那个类作为key,然后在这个类里写个重载compareTo函数不就行了。这个函数的返回值是:如果比你大,返回1;如果比你小,返回-1;一样大,返回0。既然我们希望流量较大的排前面,因此:
@Override
public int compareTo(FlowBean o) {
return sumFlow > o.getSumFlow() ? -1 : 1;
}
mapper做什么:
mappper要做的事:按'\t'切分数据,然后输出的key就是new一个FlowBean,value就用空值(null的序列化类是NullWritable)。
reducer要做的事:什么都不做,直接输出就好了。key是从拿到的FlowBean对象中取得的phone number,value就是FlowBean对象。
(代码详见SortMR.java)
(这样做还能实现按手机号分组吗?这里略微存疑(。)
加需求2:分组输出到多个文件(多个reduce)
流量统计结果输出到多个文件,每个文件里的手机号都属于同一个省。
分析
默认的情况是全部分到一个reduce里面的原因:由HashPartition类中的getPartition()方法进行分组,返回组号。key.hashCode() % reducer个数
因此需要:
- 改造分区的逻辑,自定义一个partitioner
- 自定义reducer task的并发任务数
新写一个AreaPartitioner类,继承Partitioner类,重载getPartition()方法,用得到的key(手机号)的前三位去数据库查属于哪个省份。但由于数据很大,应当用离线处理的方式比如写个loadTableToAreaMap方法(),开个hashmap存起来。(在代码中为了方便就简单的push模拟一下)
@Override
public int getPartition(KEY key, VALUE value, int numPartiotions) {
//从Key中获取手机号,查询归属地字典,不同省份返回不同组号
return areaMap.get(key.toString().substring(0,3)) == null ? 5 : areaMap.get(key.toString().substring(0,3));
}
mapper和reducer的业务逻辑都与原始代码一模一样,不同之处只是在runner中需要对job进行一下设置。
//设置自定义的分组逻辑
job.setPartitionerClass(AreaPartitioner.class);
//设置reducer任务数(与partition中的分组数一致)
job.setNumReduceTasks(6);
reducer任务数必须大于partition中的分组数,或者设置为1。
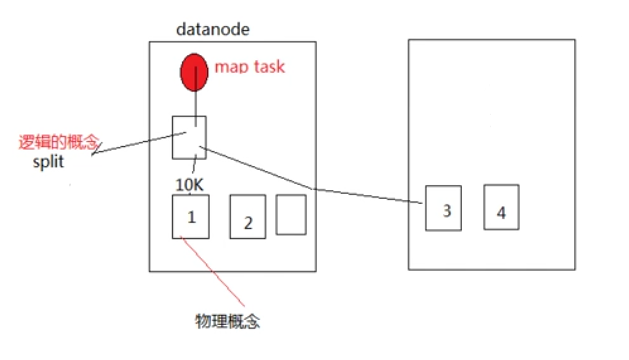
map task数量的决定机制 - split
- map task的并发数是由切片的数量决定的,有多少的切片就启动多少个map task
- 切片是一个逻辑的概念,指的是文件中数据的偏移量范围
- 切片的具体大小应根据所处理文件的大小来调整(比如小文件则一个split对应多个block,大文件则对应一个block)
MRAppMaster的任务监控调度机制(shuffle的过程)

补:MapReduce中combiner的使用
一个MapReduce的job,在map之后,reduce之前,会有一个数据聚集的过程,即map完的数据会按照key聚集在一起,会有一个shuffle的过程,然后再进入reduce。
在不同的节点上的map会将同一个key的数据传输到同一个节点上,而传输就会涉及到数据量、传输时间,combiner的作用就是在每个节点map完之后,将同一个节点上的数据,按照key输入combiner中,然后combiner可以将同一个key的数据合并或压缩,然后再传输出去。典型的例子就是wordCount程序, 数据分块之后,
1.进入map,分词,生成key/value对,map阶段结束之后,产生键值对类似这样:abc 1;aaa 1……
2.将同一个节点上的数据,按照key聚集起来,
3.输入到combiner中,进行数据聚集,输入的数据是:abc,1;abc,1 ;abc,1 ;abc,1,然后输出一条:abc,4
4.将combiner聚集完的数据传输出去,
5.进入reduce阶段:输入的数据是:abc,list(4);abc ,list( 3);abc ,list( 1),输出的数据是:abc , 8
6.将reduce输出的数据写入文件
至此,一个job结束
另附上数据格式转换:
map: (K1, V1) → list(K2,V2)
combine: (K2, list(V2)) → list(K3, V3)
reduce: (K3, list(V3)) → list(K4, V4)
不过在上面的例子里面,K1 K2 K3 K4都是abc,并没有改,实际代码中会有变化来源:牛客网
MapReduce实例2(自定义compare、partition)& shuffle机制的更多相关文章
- Hadoop(17)-MapReduce框架原理-MapReduce流程,Shuffle机制,Partition分区
MapReduce工作流程 1.准备待处理文件 2.job提交前生成一个处理规划 3.将切片信息job.split,配置信息job.xml和我们自己写的jar包交给yarn 4.yarn根据切片规划计 ...
- MapReduce框架原理--Shuffle机制
Shuffle机制 Mapreduce确保每个reducer的输入都是按键排序的.系统执行排序的过程(Map方法之后,Reduce方法之前的数据处理过程)称之为Shuffle. partition分区 ...
- MapReduce(五) mapreduce的shuffle机制 与 Yarn
一.shuffle机制 1.概述 (1)MapReduce 中, map 阶段处理的数据如何传递给 reduce 阶段,是 MapReduce 框架中最关键的一个流程,这个流程就叫 Shuffle:( ...
- Shuffle 机制
1. 概述 Map 方法之后,Reduce 方法之前的数据处理过程称之为 Shuffle. 2. Partition 分区 需求:要求将统计结果按照条件输出到不同文件中(分区).比如:将统计结果按照手 ...
- 一脸懵逼学习Hadoop中的MapReduce程序中自定义分组的实现
1:首先搞好实体类对象: write 是把每个对象序列化到输出流,readFields是把输入流字节反序列化,实现WritableComparable,Java值对象的比较:一般需要重写toStrin ...
- Hadoop_18_MapRduce 内部的shuffle机制
1.Mapreduce的shuffle机制: Mapreduce中,map阶段处理的数据如何传递给Reduce阶段,是mapreduce框架中最关键的一个流程,这个流程就叫shuffle 将mapta ...
- shuffle机制和TextInputFormat分片和读取分片数据(九)
shuffle机制 1:每个map有一个环形内存缓冲区,用于存储任务的输出.默认大小100MB(io.sort.mb属性),一旦达到阀值0.8(io.sort.spill.percent),一个后台线 ...
- 【Spark】Spark的Shuffle机制
MapReduce中的Shuffle 在MapReduce框架中,shuffle是连接Map和Reduce之间的桥梁,Map的输出要用到Reduce中必须经过shuffle这个环节,shuffle的性 ...
- 【Hadoop离线基础总结】MapReduce案例之自定义groupingComparator
MapReduce案例之自定义groupingComparator 求取Top 1的数据 需求 求出每一个订单中成交金额最大的一笔交易 订单id 商品id 成交金额 Order_0000005 Pdt ...
随机推荐
- Behave step matcher
behave 提供3中step匹配模式 'parse' 'cfparse' 基于parse的扩展, 支持cardinality field syntax? 're' 支持在step中定义正则表达式 ...
- 提高 ASP.NET Web 应用性能的 24 种方法和技巧(转载)
在这篇文章中,将介绍一些提高 ASP.NET Web 应用性能的方法和技巧.众所周知,解决性能问题是一项繁琐的工作,当出现性能问题,每个人都会归咎于编写代码的开发人员. 以下为译文 那性能问题到底该如 ...
- [javaSE] 集合框架(共性方法)
Collection接口的常用方法 add(),添加一个元素 addAll(),添加一组元素 clear(),清空 remove(),移除一个 removeAll(),移除一组 size(),元素个数 ...
- spring MethodInterceptor方法拦截
引用别的的:https://blog.csdn.net/u010739551/article/details/47754731 最近项目里加上了用户权限,有些操作需要登录,有些操作不需要,之前做项目做 ...
- 去把bilibili的返回顶点锚点扒了下来
今天闲来无事看着刷着bilibili对那锚点标记觊觎已久,下决心将其收为己用,遂动手. 个人主推Firefox+firebug查看网页代码.我用的是夜壶(nightly),就火狐的每日更新版(建议不用 ...
- 关于jquery的入门,简单的封装。
看过不同的博客,觉得以下的博客写的比较简洁明了,通俗易懂. 关于jquery博客:http://www.cnblogs.com/moqiutao/p/6523924.html 关于js:http:// ...
- spring boot 报错 Failed to read HTTP message
2008-12-13 15:06:03,930 WARN (DefaultHandlerExceptionResolver.java:384)- Failed to read HTTP message ...
- 控制台直接执行sql语句
mysql -h127.0.0.1 -P3306 -uroot -paaccccccc databasename -e "select * from RegInfo where Plat ! ...
- Vue2入门路线及资源
前言:最近在学习Vue,感觉对vue+vuex+vue-router算是小小地入门了.想起前期最苦恼也是最费时的事,就是在每个阶段找到合适当前水平的资源或者demo,所以本文我根据我自己的体验,整理了 ...
- FineReport软件
# FineReport常见问题与解答 ### FineReport是什么?FineReport,企业级web报表工具,中国报表软件知名品牌.借助于FineReport的无码理念,用户可以轻松的构建出 ...