Redis学习---Redis操作之有序集合
有序集合,在集合的基础上,为每元素排序;元素的排序需要根据另外一个值来进行比较,所以,对于有序集合,每一个元素有两个值,即:值和分数,分数专门用来做排序。
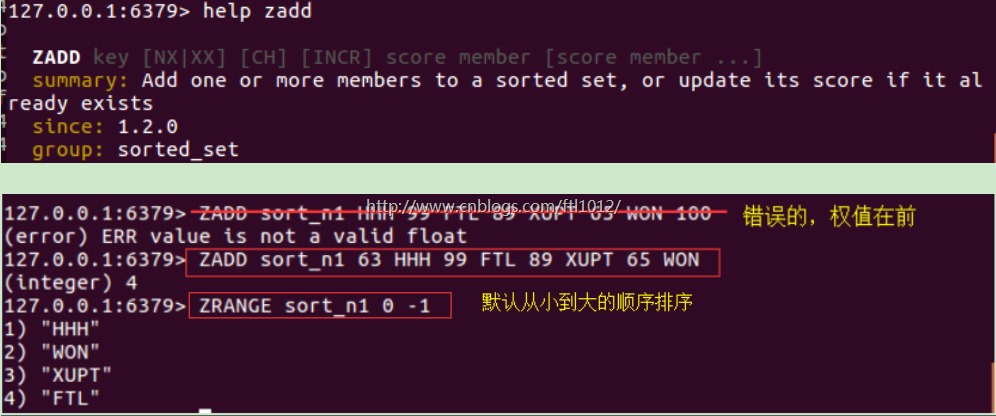
zadd(name, *args, **kwargs)
#在name对应的有序集合中添加元素
--------------------------------------------------------------------------------------------------------------------------------------
zcard(name)
# 获取name对应的有序集合元素的数量

--------------------------------------------------------------------------------------------------------------------------------------
zcount(name, min, max)
# 获取name对应的有序集合中分数 在 [min,max] 之间的个数
--------------------------------------------------------------------------------------------------------------------------------------
zincrby(name, value, amount)
# 自增name对应的有序集合的 name 对应的分数
--------------------------------------------------------------------------------------------------------------------------------------
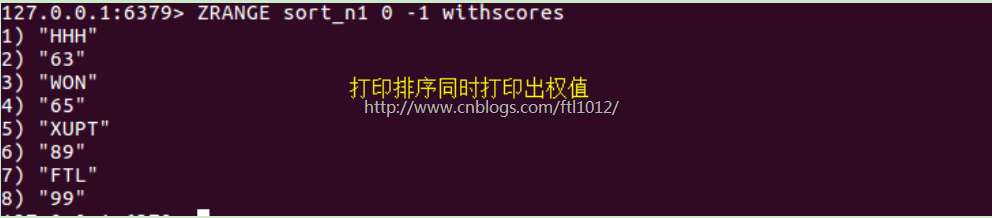
r.zrange( name, start, end, desc=False, withscores=False, score_cast_func=float)
# 按照索引范围获取name对应的有序集合的元素
# 参数:
# name,redis的name
# start,有序集合索引起始位置(非分数)
# end,有序集合索引结束位置(非分数)
# desc,排序规则,默认按照分数从小到大排序
# withscores,是否获取元素的分数,默认只获取元素的值
# score_cast_func,对分数进行数据转换的函数
# 更多:
# 从大到小排序
# zrevrange(name, start, end, withscores=False, score_cast_func=float) # 按照分数范围获取name对应的有序集合的元素
# zrangebyscore(name, min, max, start=None, num=None, withscores=False, score_cast_func=float)
# 从大到小排序
# zrevrangebyscore(name, max, min, start=None, num=None, withscores=False, score_cast_func=float)
--------------------------------------------------------------------------------------------------------------------------------------
zrank(name, value)
# 获取某个值在 name对应的有序集合中的排行(从 0 开始) # 更多: # zrevrank(name, value),从大到小排序

--------------------------------------------------------------------------------------------------------------------------------------
zrem(name, values)
# 删除name对应的有序集合中值是values的成员 # 如:zrem('zz', ['s1', 's2'])
--------------------------------------------------------------------------------------------------------------------------------------
zremrangebyrank(name, min, max)
# 根据排行范围删除

--------------------------------------------------------------------------------------------------------------------------------------
zremrangebyscore(name, min, max)
# 根据分数范围删除
--------------------------------------------------------------------------------------------------------------------------------------
zscore(name, value)
# 获取name对应有序集合中 value 对应的分数

--------------------------------------------------------------------------------------------------------------------------------------
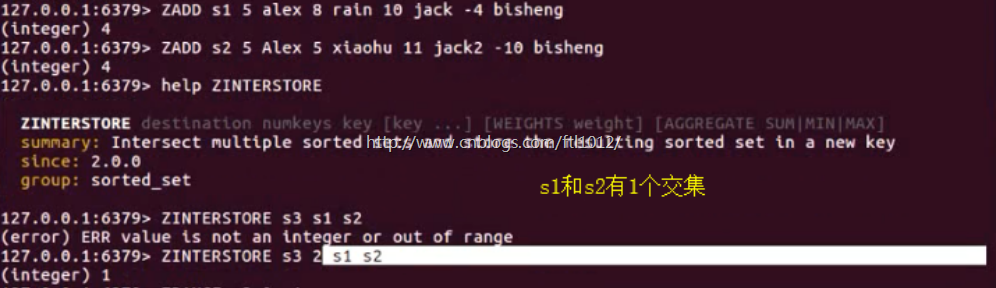
zinterstore(dest, keys, aggregate=None)
# 获取两个有序集合的交集,如果遇到相同值不同分数,则按照aggregate进行操作
# aggregate的值为: SUM MIN MAX
--------------------------------------------------------------------------------------------------------------------------------------
zscan(name, cursor=0, match=None, count=None, score_cast_func=float)
zscan_iter(name, match=None, count=None,score_cast_func=float)
# 同字符串相似,相较于字符串新增score_cast_func,用来对分数进行操作
Redis学习---Redis操作之有序集合的更多相关文章
- redis:order set有序集合类型的操作(有序集合)
1. order set有序集合类型的操作(有序集合) 有序集合是在无序集合的基础上加了一个排序的依据,这个排序依据叫score,因此声明一个集合为有序集合的时候要加上score(作为排序的依据) 1 ...
- Redis数据类型使用场景及有序集合SortedSet底层实现详解
Redis常用数据类型有字符串String.字典dict.列表List.集合Set.有序集合SortedSet,本文将简单介绍各数据类型及其使用场景,并重点剖析有序集合SortedSet的实现. Li ...
- Redis学习---Redis操作之Python连接
PyCharm下的Redis连接 连接方式: 1. 操作模式 redis-py提供两个类Redis和StrictRedis用于实现Redis的命令,StrictRedis用于实现大部分官方的命令,并使 ...
- Redis学习——Redis持久化之AOF备份方式保存数据
新技术的出现一定是在老技术的基础之上,并且完善了老技术的某一些不足的地方,新技术和老技术就如同JAVA中的继承关系.子类(新技术)比父类(老技术)更加的强大! 在前面介绍了Redis学习--Redis ...
- python对redis的常用操作 下 (无序集合,有序集合)
无序集合: 首先介绍增加,删除和获得所有元素的方法.我将会用第二部分来讨论集合的特殊操作: In [136]: x.sadd("challenge", 1,2,3,4,5,6,7, ...
- lunix下的redis数据库操作——zset有序集合
创建:(有序集合存在一个权重的概念) zadd zset 1 a 2 b 3 c 4 d 5 e 6 f 7 g # 输出: # 1) "a" # 2) "b" ...
- Redis命令拾遗五(有序集合)
本文版权归博客园和作者吴双本人共同所有,博客园蜗牛NoSql系列分享 http://www.cnblogs.com/tdws/tag/NoSql/ Sorted Set 有序集合—Sorted Set ...
- Redis学习---Redis操作之Set
Set操作,Set集合就是不允许重复的列表 sadd(name,values) name对应的集合中添加元素 --------------------------------------------- ...
- Redis学习——Redis事务
Redis和传统的关系型数据库一样,因为具有持久化的功能,所以也有事务的功能! 有关事务相关的概念和介绍,这里就不做介绍. 在学习Redis的事务之前,首先抛出一个面试的问题. 面试官:请问Redis ...
随机推荐
- 任务三十七:UI组件之浮出层
任务三十七:UI组件之浮出层 面向人群: 有一定JavaScript基础 难度: 低 重要说明 百度前端技术学院的课程任务是由百度前端工程师专为对前端不同掌握程度的同学设计.我们尽力保证课程内容的质量 ...
- JS中的编码,解码类型及说明
使用ajax向后台提交的时候 由于参数中含有# 默认会被截断 只保留#之前的字符 json格式的字符串则不会被请求到后台的action 可以使用encodeURIComponent在前台进行编码, ...
- hdu 1885
Key Task Time Limit: 3000/1000 MS (Java/Others) Memory Limit: 32768/32768 K (Java/Others)Total Su ...
- MS SQL Server数据库在线管理工具
MS SQL Server数据库以其优异的性能,被广泛使用,特别是政务,医疗行业.但是远程维护挺不方便的,目前有一款基于WEB的工具TreeSoft数据库管理系统. 免安装,直接解压就可以用了.直接通 ...
- Hive Metastore 连接报错
背景 项目中需要通过一些自定义的组件来操控hive的元数据,于是使用了remote方式来存储hive元数据,使用一个服务后台作为gateway,由它来控制hive元数据. 现象 在windows上连接 ...
- .NET中的异步编程
开篇 异步编程是程序设计的重点也是难点,还记得在刚开始接触.net的时候,看的是一本c#的Winform实例教程,上面大部分都是教我们如何使用Winform的控件以及操作数据库的实例,那时候做的基本都 ...
- border-radius 移动之伤
border-radius我相信对于老一辈的前端们有着特殊的感情,在经历了没有圆角的蛮荒时代,到如今 CSS3 遍地开花,我们还是很幸福的. 然而即使到了三星大脸流行时代,border-radius在 ...
- marquee 标签的使用介绍
marquee 实现滚动效果(创建滚动的文本字幕) 1.marquee 支持的属性: (1).behavior设置滚动方式: <marquee behavior="alternate& ...
- 前台提交数据(表单数据、Json数据及上传文件)的类型
MIME (Multipurpose Internet Mail Extensions) 是描述内容类型的互联网标准.Clients use this content type or media ty ...
- ubuntu下使用g++编译时默认支持C++11 配置方法
1.只需要在源文件程序中加上如下一行代码: #pragma GCC diagnostic error "-std=c++11" 此时源文件代码如下: #pragma GCC dia ...