Apache Flink - 架构和拓扑
Flink结构:

- flink cli 解析本地环境配置,启动
ApplicationMaster - 在
ApplicationMaster中启动JobManager - 在
ApplicationMaster中启动YarnFlinkResourceManager YarnFlinkResourceManager给JobManager发送注册信息YarnFlinkResourceManager注册成功后,JobManager给YarnFlinkResourceManager发送注册成功信息YarnFlinkResourceManage知道自己注册成功后像ResourceManager申请和TaskManager数量对等的 container- 在container中启动
TaskManager TaskManager将自己注册到JobManager中
接下来便是程序的提交和运行。
- flink cli 解析本地环境配置,启动
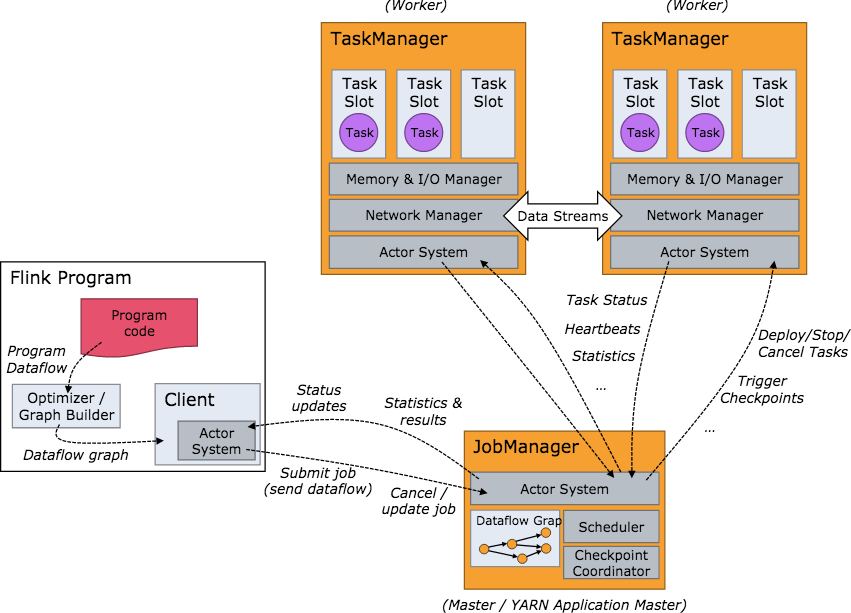
JobManager负责接收 flink 的作业,调度 task,收集 job 的状态、jar 包管理,checkpoint 的协调和发起,管理 TaskManagers。- 算子:flink 的一个 operator 代表一个最顶级的 API接口。对于streaming,在 DataStream 上做诸如 map/reduce/keyBy 等操作均会生成一个算子。
- TaskManager 在 Flink 中也被叫做一个 Instance,统一管理该物理节点上的所有Flink job的task运行,它的功能包括了task的启动销毁、内存管理、磁盘IO、网络传输管理等等。
- 下方是 Flink 集群启动后架构图:
Graph:
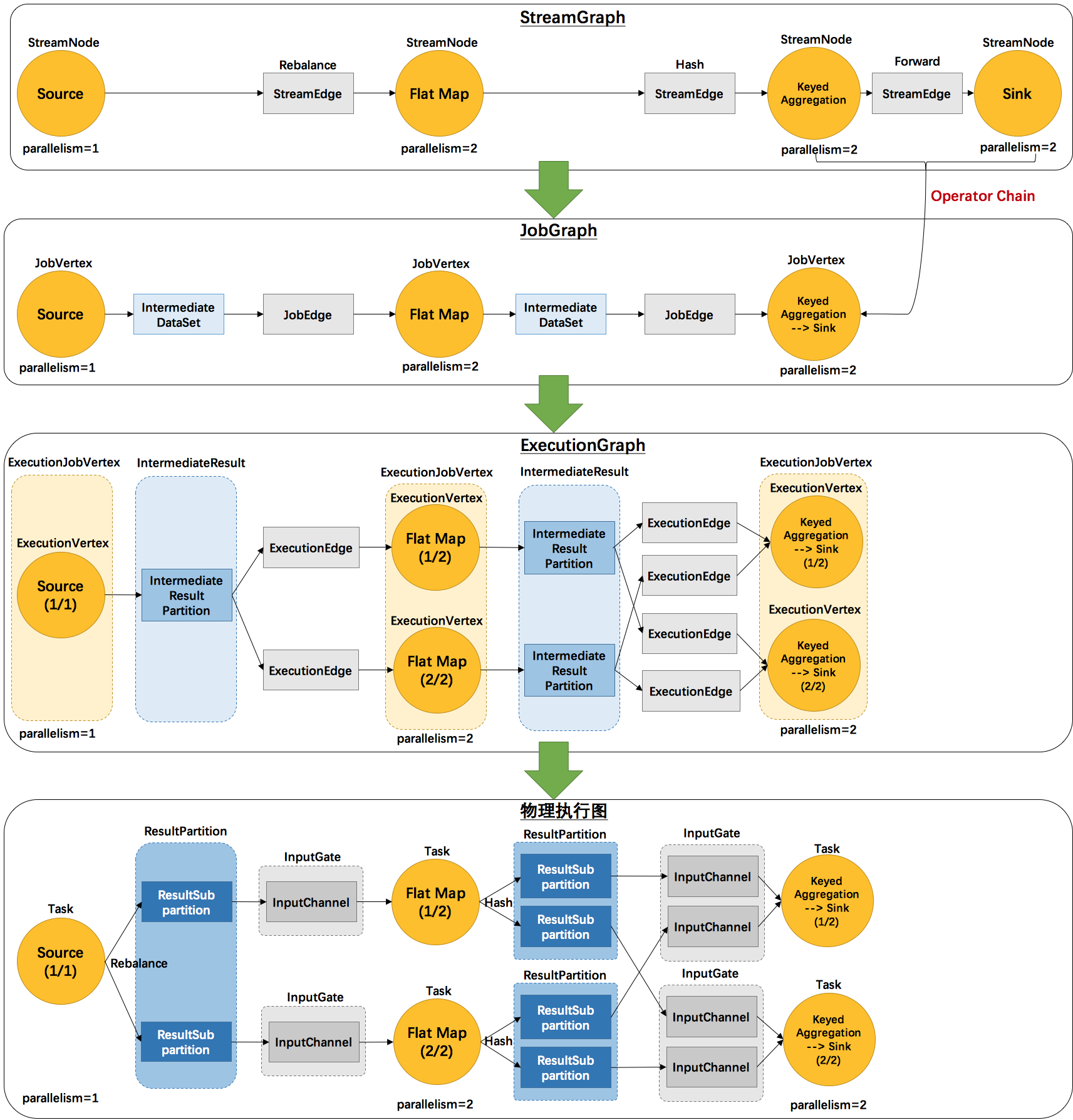
- Flink 中的执行图可以分成四层:StreamGraph -> JobGraph -> ExecutionGraph -> 物理执行图。
- StreamGraph:是根据用户通过 Stream API 编写的代码生成的最初的图。用来表示程序的拓扑结构。
- JobGraph:StreamGraph经过优化后生成了 JobGraph,提交给 JobManager 的数据结构。主要的优化为,将多个符合条件的节点 chain 在一起作为一个节点,这样可以减少数据在节点之间流动所需要的序列化/反序列化/传输消耗。
- ExecutionGraph:JobManager 根据 JobGraph 生成ExecutionGraph。方便调度和监控和跟踪各个 tasks 的状态。ExecutionGraph是JobGraph的并行化版本,是调度层最核心的数据结构。
- 物理执行图:JobManager 根据 ExecutionGraph 对 Job 进行调度后,在各个TaskManager 上部署 Task 后形成的“图”,并不是一个具体的数据结构。
- 2个并发度(Source为1个并发度)的
SocketTextStreamWordCount四层执行图的演变过程:- StreamGraph:根据用户通过 Stream API 编写的代码生成的最初的图。
- StreamNode:用来代表 operator 的类,并具有所有相关的属性,如并发度、入边和出边等。
- StreamEdge:表示连接两个StreamNode的边。
- JobGraph:StreamGraph经过优化后生成了 JobGraph,提交给 JobManager 的数据结构。
- JobVertex:经过优化后符合条件的多个StreamNode可能会chain在一起生成一个JobVertex,即一个JobVertex包含一个或多个operator,JobVertex的输入是JobEdge,输出是IntermediateDataSet。
- IntermediateDataSet:表示JobVertex的输出,即经过operator处理产生的数据集。producer是JobVertex,consumer是JobEdge。
- JobEdge:代表了job graph中的一条数据传输通道。source 是 IntermediateDataSet,target 是 JobVertex。即数据通过JobEdge由IntermediateDataSet传递给目标JobVertex。
- ExecutionGraph:JobManager 根据 JobGraph 生成ExecutionGraph。ExecutionGraph是JobGraph的并行化版本,是调度层最核心的数据结构。
- ExecutionJobVertex:和JobGraph中的JobVertex一一对应。每一个ExecutionJobVertex都有和并发度一样多的 ExecutionVertex。
- ExecutionVertex:表示ExecutionJobVertex的其中一个并发子任务,输入是ExecutionEdge,输出是IntermediateResultPartition。
- IntermediateResult:和JobGraph中的IntermediateDataSet一一对应。一个IntermediateResult包含多个IntermediateResultPartition,其个数等于该operator的并发度。
- IntermediateResultPartition:表示ExecutionVertex的一个输出分区,producer是ExecutionVertex,consumer是若干个ExecutionEdge。
- ExecutionEdge:表示ExecutionVertex的输入,source是IntermediateResultPartition,target是ExecutionVertex。source和target都只能是一个。
- Execution:是执行一个 ExecutionVertex 的一次尝试。当发生故障或者数据需要重算的情况下 ExecutionVertex 可能会有多个 ExecutionAttemptID。一个 Execution 通过 ExecutionAttemptID 来唯一标识。JM和TM之间关于 task 的部署和 task status 的更新都是通过 ExecutionAttemptID 来确定消息接受者。
- 物理执行图:JobManager 根据 ExecutionGraph 对 Job 进行调度后,在各个TaskManager 上部署 Task 后形成的“图”,并不是一个具体的数据结构。
- Task:Execution被调度后在分配的 TaskManager 中启动对应的 Task。Task 包裹了具有用户执行逻辑的 operator。
- ResultPartition:代表由一个Task的生成的数据,和ExecutionGraph中的IntermediateResultPartition一一对应。
- ResultSubpartition:是ResultPartition的一个子分区。每个ResultPartition包含多个ResultSubpartition,其数目要由下游消费 Task 数和 DistributionPattern 来决定。
- InputGate:代表Task的输入封装,和JobGraph中JobEdge一一对应。每个InputGate消费了一个或多个的ResultPartition。
- InputChannel:每个InputGate会包含一个以上的InputChannel,和ExecutionGraph中的ExecutionEdge一一对应,也和ResultSubpartition一对一地相连,即一个InputChannel接收一个ResultSubpartition的输出。
- StreamGraph:根据用户通过 Stream API 编写的代码生成的最初的图。
Apache Flink - 架构和拓扑的更多相关文章
- Apache Flink系列(1)-概述
一.设计思想及介绍 基本思想:“一切数据都是流,批是流的特例” 1.Micro Batching 模式 在Micro-Batching模式的架构实现上就有一个自然流数据流入系统进行攒批的过程,这在一定 ...
- Apache Flink:特性、概念、组件栈、架构及原理分析
2016-04-30 22:24:39 Yanjun Apache Flink是一个面向分布式数据流处理和批量数据处理的开源计算平台,它能够基于同一个Flink运行时(Flink Runtim ...
- flink架构介绍
前言 flink作为基于流的大数据计算引擎,可以说在大数据领域的红人,下面对flink-1.7的架构进行逻辑上的分析并和spark做了一些关键点的对比. 架构 如图1,flink架构分为3个部分,cl ...
- Flink架构、原理与部署测试
Apache Flink是一个面向分布式数据流处理和批量数据处理的开源计算平台,它能够基于同一个Flink运行时,提供支持流处理和批处理两种类型应用的功能. 现有的开源计算方案,会把流处理和批处理作为 ...
- Apache Flink Quickstart
Apache Flink 是新一代的基于 Kappa 架构的流处理框架,近期底层部署结构基于 FLIP-6 做了大规模的调整,我们来看一下在新的版本(1.6-SNAPSHOT)下怎样从源码快速编译执行 ...
- 新一代大数据处理引擎 Apache Flink
https://www.ibm.com/developerworks/cn/opensource/os-cn-apache-flink/index.html 大数据计算引擎的发展 这几年大数据的飞速发 ...
- Apache Flink 介绍
原文地址:https://mp.weixin.qq.com/s?__biz=MzU2Njg5Nzk0NQ==&mid=2247483660&idx=1&sn=ecf01cfc8 ...
- Flink架构、原理与部署测试(转)
Apache Flink是一个面向分布式数据流处理和批量数据处理的开源计算平台,它能够基于同一个Flink运行时,提供支持流处理和批处理两种类型应用的功能. 现有的开源计算方案,会把流处理和批处理作为 ...
- 终于等到你!阿里正式向 Apache Flink 贡献 Blink 源码
摘要: 如同我们去年12月在 Flink Forward China 峰会所约,阿里巴巴内部 Flink 版本 Blink 将于 2019 年 1 月底正式开源.今天,我们终于等到了这一刻. 阿里妹导 ...
随机推荐
- js-Date对象(九)
一.Date对象的创建1.new Date()[创建当前时间对象]eg: var date = new Date(); console.log(date); //Thu Jul 18 2019 18: ...
- tcp、udp协议栈
tcp struct tcphdr { __be16 source; //源端口 __be16 dest; //目的端口 __be32 seq; //序列号 __be32 ack_seq; //确认号 ...
- WPF 依赖属性前言
WPF 依赖属性前言 在.net中,我们可以属性来获取或设置字段的值,不需要在编写额外的get和set方法,但这有一个前提,那就是需要在对象中拥有一个字段,才能在此字段的基础上获取或设置字段的值, ...
- MySQL修炼之路三
1. SQL查询 1. 执行顺序 3. select ... 聚合函数 from 表名 1. where ... 2. group by ... 4. having ... 5. order by . ...
- bat文件中运行python脚本方法
在脚本中使用start命令: @echo off start python xxx.py 注: start命令:启动单独的“命令提示符”窗口来运行指定程序或命令.如果在没有参数的情况下使用,start ...
- C程序中的内存分布
一个典型的C程序存储分区包含以下几类: Text段 已初始化数据段 未初始化数据段 栈 堆 进程运行时的典型内存布局 1. Text段 Text段通常也称为代码段,由可执行指令构成,是程序在目标文件或 ...
- Mysql中innodb和myisam
innodb和myisam两种存储引擎的区别 1.事务和外键 1)InnoDB具有事务,支持4个事务隔离级别,回滚,崩溃修复能力和多版本并发的事务安全,包括ACID.如果应用中需要执行大量的INSER ...
- Apache服务器http强制转https(ubuntu系统)
Apache服务器http强制转https 修改网站根目录下的.htaccess文件 验证
- 【Miscalculation UVALive - 6833 】【模拟】
题目分析 题目讲的是给你一个串,里面是加法.乘法混合运算(个人赛中误看成是加减乘除混合运算),有两种算法,一种是乘法优先运算,另一种是依次从左向右运算(不管它是否乘在前还是加在前). 个人赛中试着模拟 ...
- windows下面,PHP如何启动一些扩展功能
我今天在试这个时,发现php有些默认设置,是需要人为介入修改的. 比如,当我们在安装一个软件,而这个软件需要启用php一些扩展功能. 那么,按一般套路,将php.ini文件里的相关行的注释去掉即可. ...