Apache Flink - 架构和拓扑
Flink结构:

- flink cli 解析本地环境配置,启动
ApplicationMaster - 在
ApplicationMaster中启动JobManager - 在
ApplicationMaster中启动YarnFlinkResourceManager YarnFlinkResourceManager给JobManager发送注册信息YarnFlinkResourceManager注册成功后,JobManager给YarnFlinkResourceManager发送注册成功信息YarnFlinkResourceManage知道自己注册成功后像ResourceManager申请和TaskManager数量对等的 container- 在container中启动
TaskManager TaskManager将自己注册到JobManager中
接下来便是程序的提交和运行。
- flink cli 解析本地环境配置,启动
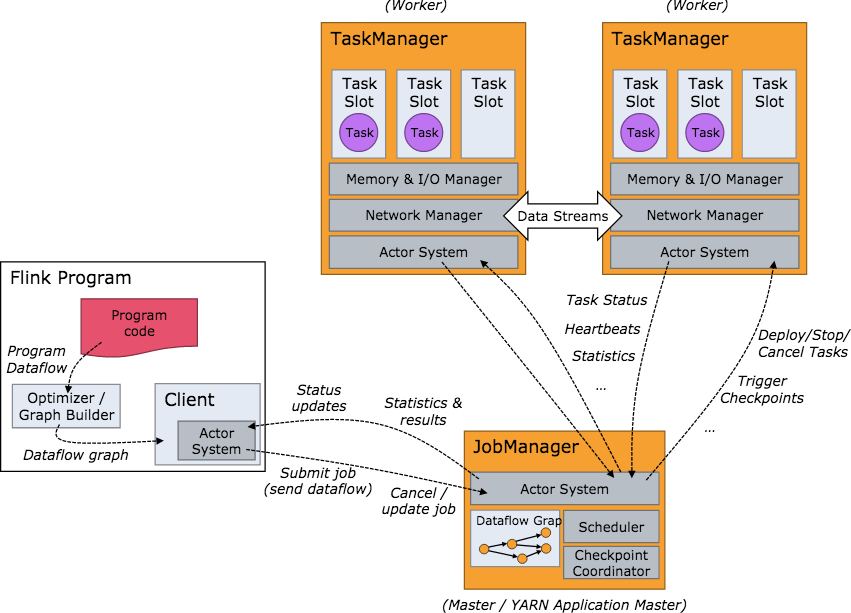
JobManager负责接收 flink 的作业,调度 task,收集 job 的状态、jar 包管理,checkpoint 的协调和发起,管理 TaskManagers。- 算子:flink 的一个 operator 代表一个最顶级的 API接口。对于streaming,在 DataStream 上做诸如 map/reduce/keyBy 等操作均会生成一个算子。
- TaskManager 在 Flink 中也被叫做一个 Instance,统一管理该物理节点上的所有Flink job的task运行,它的功能包括了task的启动销毁、内存管理、磁盘IO、网络传输管理等等。
- 下方是 Flink 集群启动后架构图:
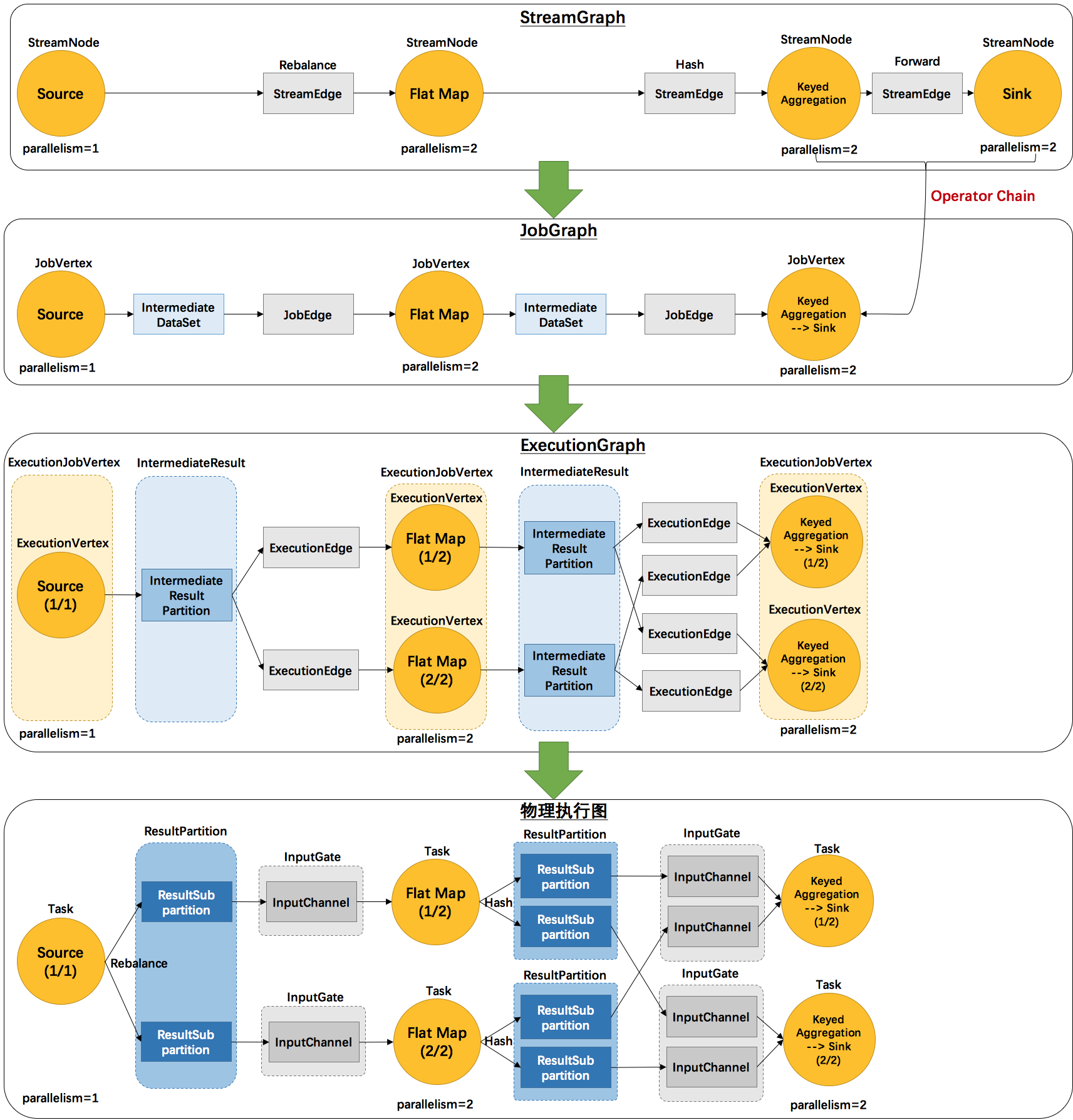
Graph:
- Flink 中的执行图可以分成四层:StreamGraph -> JobGraph -> ExecutionGraph -> 物理执行图。
- StreamGraph:是根据用户通过 Stream API 编写的代码生成的最初的图。用来表示程序的拓扑结构。
- JobGraph:StreamGraph经过优化后生成了 JobGraph,提交给 JobManager 的数据结构。主要的优化为,将多个符合条件的节点 chain 在一起作为一个节点,这样可以减少数据在节点之间流动所需要的序列化/反序列化/传输消耗。
- ExecutionGraph:JobManager 根据 JobGraph 生成ExecutionGraph。方便调度和监控和跟踪各个 tasks 的状态。ExecutionGraph是JobGraph的并行化版本,是调度层最核心的数据结构。
- 物理执行图:JobManager 根据 ExecutionGraph 对 Job 进行调度后,在各个TaskManager 上部署 Task 后形成的“图”,并不是一个具体的数据结构。
- 2个并发度(Source为1个并发度)的
SocketTextStreamWordCount四层执行图的演变过程:- StreamGraph:根据用户通过 Stream API 编写的代码生成的最初的图。
- StreamNode:用来代表 operator 的类,并具有所有相关的属性,如并发度、入边和出边等。
- StreamEdge:表示连接两个StreamNode的边。
- JobGraph:StreamGraph经过优化后生成了 JobGraph,提交给 JobManager 的数据结构。
- JobVertex:经过优化后符合条件的多个StreamNode可能会chain在一起生成一个JobVertex,即一个JobVertex包含一个或多个operator,JobVertex的输入是JobEdge,输出是IntermediateDataSet。
- IntermediateDataSet:表示JobVertex的输出,即经过operator处理产生的数据集。producer是JobVertex,consumer是JobEdge。
- JobEdge:代表了job graph中的一条数据传输通道。source 是 IntermediateDataSet,target 是 JobVertex。即数据通过JobEdge由IntermediateDataSet传递给目标JobVertex。
- ExecutionGraph:JobManager 根据 JobGraph 生成ExecutionGraph。ExecutionGraph是JobGraph的并行化版本,是调度层最核心的数据结构。
- ExecutionJobVertex:和JobGraph中的JobVertex一一对应。每一个ExecutionJobVertex都有和并发度一样多的 ExecutionVertex。
- ExecutionVertex:表示ExecutionJobVertex的其中一个并发子任务,输入是ExecutionEdge,输出是IntermediateResultPartition。
- IntermediateResult:和JobGraph中的IntermediateDataSet一一对应。一个IntermediateResult包含多个IntermediateResultPartition,其个数等于该operator的并发度。
- IntermediateResultPartition:表示ExecutionVertex的一个输出分区,producer是ExecutionVertex,consumer是若干个ExecutionEdge。
- ExecutionEdge:表示ExecutionVertex的输入,source是IntermediateResultPartition,target是ExecutionVertex。source和target都只能是一个。
- Execution:是执行一个 ExecutionVertex 的一次尝试。当发生故障或者数据需要重算的情况下 ExecutionVertex 可能会有多个 ExecutionAttemptID。一个 Execution 通过 ExecutionAttemptID 来唯一标识。JM和TM之间关于 task 的部署和 task status 的更新都是通过 ExecutionAttemptID 来确定消息接受者。
- 物理执行图:JobManager 根据 ExecutionGraph 对 Job 进行调度后,在各个TaskManager 上部署 Task 后形成的“图”,并不是一个具体的数据结构。
- Task:Execution被调度后在分配的 TaskManager 中启动对应的 Task。Task 包裹了具有用户执行逻辑的 operator。
- ResultPartition:代表由一个Task的生成的数据,和ExecutionGraph中的IntermediateResultPartition一一对应。
- ResultSubpartition:是ResultPartition的一个子分区。每个ResultPartition包含多个ResultSubpartition,其数目要由下游消费 Task 数和 DistributionPattern 来决定。
- InputGate:代表Task的输入封装,和JobGraph中JobEdge一一对应。每个InputGate消费了一个或多个的ResultPartition。
- InputChannel:每个InputGate会包含一个以上的InputChannel,和ExecutionGraph中的ExecutionEdge一一对应,也和ResultSubpartition一对一地相连,即一个InputChannel接收一个ResultSubpartition的输出。
- StreamGraph:根据用户通过 Stream API 编写的代码生成的最初的图。
Apache Flink - 架构和拓扑的更多相关文章
- Apache Flink系列(1)-概述
一.设计思想及介绍 基本思想:“一切数据都是流,批是流的特例” 1.Micro Batching 模式 在Micro-Batching模式的架构实现上就有一个自然流数据流入系统进行攒批的过程,这在一定 ...
- Apache Flink:特性、概念、组件栈、架构及原理分析
2016-04-30 22:24:39 Yanjun Apache Flink是一个面向分布式数据流处理和批量数据处理的开源计算平台,它能够基于同一个Flink运行时(Flink Runtim ...
- flink架构介绍
前言 flink作为基于流的大数据计算引擎,可以说在大数据领域的红人,下面对flink-1.7的架构进行逻辑上的分析并和spark做了一些关键点的对比. 架构 如图1,flink架构分为3个部分,cl ...
- Flink架构、原理与部署测试
Apache Flink是一个面向分布式数据流处理和批量数据处理的开源计算平台,它能够基于同一个Flink运行时,提供支持流处理和批处理两种类型应用的功能. 现有的开源计算方案,会把流处理和批处理作为 ...
- Apache Flink Quickstart
Apache Flink 是新一代的基于 Kappa 架构的流处理框架,近期底层部署结构基于 FLIP-6 做了大规模的调整,我们来看一下在新的版本(1.6-SNAPSHOT)下怎样从源码快速编译执行 ...
- 新一代大数据处理引擎 Apache Flink
https://www.ibm.com/developerworks/cn/opensource/os-cn-apache-flink/index.html 大数据计算引擎的发展 这几年大数据的飞速发 ...
- Apache Flink 介绍
原文地址:https://mp.weixin.qq.com/s?__biz=MzU2Njg5Nzk0NQ==&mid=2247483660&idx=1&sn=ecf01cfc8 ...
- Flink架构、原理与部署测试(转)
Apache Flink是一个面向分布式数据流处理和批量数据处理的开源计算平台,它能够基于同一个Flink运行时,提供支持流处理和批处理两种类型应用的功能. 现有的开源计算方案,会把流处理和批处理作为 ...
- 终于等到你!阿里正式向 Apache Flink 贡献 Blink 源码
摘要: 如同我们去年12月在 Flink Forward China 峰会所约,阿里巴巴内部 Flink 版本 Blink 将于 2019 年 1 月底正式开源.今天,我们终于等到了这一刻. 阿里妹导 ...
随机推荐
- 【转载】 C#中使用int.TryParse方法将字符串转换为整型Int类型
在C#编程过程中,将字符串string转换为整型int过程中,时常使用的转换方法为int.Parse方法,但int.Parse在无法转换的时候,会抛出程序异常,其实还有个int.TryParse方法可 ...
- Google 浏览器保存mht网页文件(单个网页)的方法(无需插件)
1.找到设置打开单个网页保存的地方 在google浏览器地址栏输入:chrome://flags”,回车 2.实现保存单个网页 打开你要保存的网页后,只需 Ctrl+s ,搞定!如下: 假设找到了一篇 ...
- 【OGG】OGG的下载和安装篇
[OGG]OGG的下载和安装篇 一.1 BLOG文档结构图 一.2 前言部分 一.2.1 导读 各位技术爱好者,看完本文后,你可以掌握如下的技能,也可以学到一些其它你所不知道的知识,~O(∩_∩ ...
- vue.js下移动端绑定click事件失效,pc端正常的问题
原因可能是 我在项目中使用到了 better-scroll,默认它会阻止 touch 事件.所以在配置中需要加上 click: true 即可. 例如: mounted () { this.scrol ...
- Linux操作系统的计划任务
Linux操作系统的计划任务 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.任务计划概述 Linux任务计划.周期性任务执行 未来的某时间点执行一次任务: at: 指定时间点, ...
- appium+python自动化63-使用Uiautomator2报错问题解决
前言 appium desktop V1.7.1版本使用命令行版本启动appium后,使用Uiautomator2定位toast信息报错:appium-uiautomator2-server-v0.3 ...
- python——使用xlwing库进行Excel操作
Excel是现在比不可少的数据处理软件,python有很多支持Excel操作的库,xlwing就是其中之一. xlwings的安装 xlwings库使用pip安装: 在控制台输入 pip instal ...
- spark-scala开发的第一个程序WordCount
package ***** import org.apache.spark.{SparkConf, SparkContext} object WordCount { def main(args: Ar ...
- linux中的alias命令详解
功能说明:设置指令的别名.语 法:alias[别名]=[指令名称]参 数 :若不加任何参数,则列出目前所有的别名设置.举 例 :ermao@lost-desktop:~$ alias ...
- django.db.models.fields.related_descriptors.RelatedObjectDoesNotExist: Course has no coursedetail.
错误描述: 一对一反向查询失败! 前提: Course和CourseDetail OneToOne 原因: Course数据和CourseDetail数据没有一一对应.