tensorflow数据加载、模型训练及预测
数据集
DNN 依赖于大量的数据。可以收集或生成数据,也可以使用可用的标准数据集。TensorFlow 支持三种主要的读取数据的方法,可以在不同的数据集中使用;本教程中用来训练建立模型的一些数据集介绍如下:
- MNIST:这是最大的手写数字(0~9)数据库。它由 60000 个示例的训练集和 10000 个示例的测试集组成。该数据集存放在 Yann LeCun 的主页(http://yann.lecun.com/exdb/mnist/)中。这个数据集已经包含在tensorflow.examples.tutorials.mnist 的 TensorFlow 库中。
- CIFAR10:这个数据集包含了 10 个类别的 60000 幅 32×32 彩色图像,每个类别有 6000 幅图像。其中训练集包含 50000 幅图像,测试数据集包含 10000 幅图像。数据集的 10 个类别分别是:飞机、汽车、鸟、猫、鹿、狗、青蛙、马、船和卡车。该数据由多伦多大学计算机科学系维护(https://www.cs.toronto.edu/kriz/cifar.html)。
- WORDNET:这是一个英文的词汇数据库。它包含名词、动词、副词和形容词,被归为一组认知同义词(Synset),即代表相同概念的词语,例如 shut 和 close,car 和 automobile 被分组为无序集合。它包含 155287 个单词,组织在 117659 个同义词集合中,总共 206941 个单词对。该数据集由普林斯顿大学维护(https://wordnet.princeton.edu/)。
- ImageNET:这是一个根据 WORDNET 层次组织的图像数据集(目前只有名词)。每个有意义的概念(synset)由多个单词或单词短语来描述。每个子空间平均由 1000 幅图像表示。目前共有 21841 个同义词,共有 14197122 幅图像。自 2010 年以来,每年举办一次 ImageNet 大规模视觉识别挑战赛(ILSVRC),将图像分类到 1000 个对象类别中。这项工作是由美国普林斯顿大学、斯坦福大学、A9 和谷歌赞助(http://www.image-net.org/)。
- YouTube-8M:这是一个由数百万 YouTube 视频组成的大型标签视频数据集。它有大约 700 万个 YouTube 视频网址,分为 4716 个小类,并分为 24 个大类。它还提供预处理支持和框架功能。数据集由 Google Research(https://research.google.com/youtube8m/)维护。
读取数据
在 TensorFlow 中可以通过三种方式读取数据:
- 通过feed_dict传递数据;
- 从文件中读取数据;
- 使用预加载的数据;
在本教程中都使用这三种方式来读取数据。
接下来,你将依次学习每种数据读取方式。
通过feed_dict传递数据
在这种情况下,运行每个步骤时都会使用 run() 或 eval() 函数调用中的 feed_dict 参数来提供数据。这是在占位符的帮助下完成的,这个方法允许传递 Numpy 数组数据。可以使用 TensorFlow 的以下代码:

这里,x 和 y 是占位符;使用它们,在 feed_dict 的帮助下传递包含 X 值的数组和包含 Y 值的数组。
从文件中读取
当数据集非常大时,使用此方法可以确保不是所有数据都立即占用内存(例如 60 GB的 YouTube-8m 数据集)。从文件读取的过程可以通过以下步骤完成:
- 使用字符串张量 ["file0","file1"] 或者 [("file%d"i)for in in range(2)] 的方式创建文件命名列表,或者使用
files=tf.train.match_filenames_once('*.JPG')函数创建。 - 文件名队列:创建一个队列来保存文件名,此时需要使用 tf.train.string_input_producer 函数:

这个函数还提供了一个选项来排列和设置批次的最大数量。整个文件名列表被添加到每个批次的队列中。如果选择了 shuffle=True,则在每个批次中都要重新排列文件名。
- Reader用于从文件名队列中读取文件。根据输入文件格式选择相应的阅读器。read方法是标识文件和记录(调试时有用)以及标量字符串值的关键字。例如,文件格式为.csv 时:

- Decoder:使用一个或多个解码器和转换操作来将值字符串解码为构成训练样本的张量:
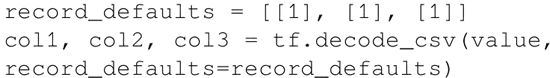
预加载的数据
当数据集很小时可以使用,可以在内存中完全加载。因此,可以将数据存储在常量或变量中。在使用变量时,需要将可训练标志设置为 False,以便训练时数据不会改变。预加载数据为 TensorFlow 常量时:

一般来说,数据被分为三部分:训练数据、验证数据和测试数据。
定义模型
建立描述网络结构的计算图。它涉及指定信息从一组神经元到另一组神经元的超参数、变量和占位符序列以及损失/错误函数。你将在本章后面的章节中了解更多有关计算图的内容。
训练/学习
在 DNN 中的学习通常基于梯度下降算法(后续章节将详细讨论),其目的是要找到训练变量(权重/偏置),将损失/错误函数最小化。这是通过初始化变量并使用 run() 来实现的:

评估模型
一旦网络被训练,通过 predict() 函数使用验证数据和测试数据来评估网络。这可以评价模型是否适合相应数据集,可以避免过拟合或欠拟合的问题。一旦模型取得让人满意的精度,就可以部署在生产环境中了。
拓展阅读
在 TensorFlow 1.3 中,增加了一个名为 TensorFlow Estimator 的新功能。 TensorFlow Estimator 使创建神经网络模型的任务变得更加容易,它是一个封装了训练、评估、预测和服务过程的更高层次的API。它提供了使用预先制作的估算器的选项,或者可以编写自己的定制估算器。通过预先制定的估算器,不再需要担心构建计算或创建会话,它会处理所有这些。
目前 TensorFlow Estimator 有 6 个预先制定的估算器。使用 TensorFlow 预制的 Estimator 的另一个优点是,它本身也可以在 TensorBoard 上创建可视化的摘要。
前面章节中,介绍了如何在 TensorFlow 中读取文件,本节将重点介绍如何从 CSV 文件中读取数据并在训练之前对数据进行预处理。
本节将采用哈里森和鲁宾菲尔德于 1978 年收集的波士顿房价数据集(http://lib.stat.cmu.edu/datasets/boston),该数据集包括 506 个样本场景,每个房屋含 14 个特征:
- CRIM:城镇人均犯罪率
- ZN:占地 25000 平方英尺(1 英尺=0.3048 米)以上的住宅用地比例
- INDUS:每个城镇的非零售商业用地比例
- CHAS:查尔斯河(Charles River)变量(若土地位于河流边界,则为 1;否则为 0)
- NOX:一氧化氮浓度(每千万)
- RM:每个寓所的平均房间数量
- AGE:1940 年以前建成的自住单元比例
- DIS:到 5 个波士顿就业中心的加权距离
- RAD:径向高速公路可达性指数
- TAX:每万美元的全价值物业税税率
- PTRATIO:镇小学老师比例
- B:1000(Bk-0.63)2,其中 Bk 是城镇黑人的比例
- LSTAT:低地位人口的百分比
- MEDV:1000 美元自有住房的中位值
TensorFlow读取csv文件过程
- 导入所需的模块并声明全局变量:

- 定义一个将文件名作为参数的函数,并返回大小等于 BATCH_SIZE 的张量:

- 定义 f_queue 和 reader 为文件名:

- 这里指定要使用的数据以防数据丢失。对 .csv 解码并选择需要的特征。例如,选择 RM、PTRATIO 和 LSTAT 特征:

- 定义参数来生成批并使用 tf.train.shuffle_batch() 来随机重新排列张量。该函数返回张量 feature_batch 和 label_batch:

- 这里定义了另一个函数在会话中生成批:

- 使用这两个函数得到批中的数据。这里,仅打印数据;在学习训练时,将在这里执行优化步骤:

TensorFlow csv数据预处理
用前面章节提到的 TensorFlow 控制操作和张量来对数据进行预处理。例如,对于波士顿房价的情况,大约有 16 个数据行的 MEDV 是 50.0。在大多数情况下,这些数据点包含缺失或删减的值,因此建议不要考虑用这些数据训练。可以使用下面的代码在训练数据集中删除它们:

这里定义了一个张量布尔条件,若 MEDV 等于 50.0 则为真。如果条件为真则可使用 TensorFlow tf.where() 操作赋为零值。
tensorflow数据加载、模型训练及预测的更多相关文章
- tensorflow学习笔记2:c++程序静态链接tensorflow库加载模型文件
首先需要搞定tensorflow c++库,搜了一遍没有找到现成的包,于是下载tensorflow的源码开始编译: tensorflow的contrib中有一个makefile项目,极大的简化的接下来 ...
- 深度学习原理与框架-猫狗图像识别-卷积神经网络(代码) 1.cv2.resize(图片压缩) 2..get_shape()[1:4].num_elements(获得最后三维度之和) 3.saver.save(训练参数的保存) 4.tf.train.import_meta_graph(加载模型结构) 5.saver.restore(训练参数载入)
1.cv2.resize(image, (image_size, image_size), 0, 0, cv2.INTER_LINEAR) 参数说明:image表示输入图片,image_size表示变 ...
- TensorFlow保存、加载模型参数 | 原理描述及踩坑经验总结
写在前面 我之前使用的LSTM计算单元是根据其前向传播的计算公式手动实现的,这两天想要和TensorFlow自带的tf.nn.rnn_cell.BasicLSTMCell()比较一下,看看哪个训练速度 ...
- 【4】TensorFlow光速入门-保存模型及加载模型并使用
本文地址:https://www.cnblogs.com/tujia/p/13862360.html 系列文章: [0]TensorFlow光速入门-序 [1]TensorFlow光速入门-tenso ...
- Pytorch文本分类(imdb数据集),含DataLoader数据加载,最优模型保存
用pytorch进行文本分类,数据集为keras内置的imdb影评数据(二分类),代码包含六个部分(详见代码) 使用环境: pytorch:1.1.0 cuda:10.0 gpu:RTX2070 (1 ...
- 132、TensorFlow加载模型
# The tf.train.Saver对象不仅保存变量到checkpoint文件 # 它也恢复变量,当你恢复变量的时候,你就不必须要提前初始化他们 # 列如如下的代码片段解释了如何去调用tf.tra ...
- coreml之通过URL加载模型
在xcode中使用mlmodel模型,之前说的最简单的方法是将模型拖进工程中即可,xcode会自动生成有关模型的前向预测接口,这种方式非常简单,但是更新模型就很不方便. 今天说下另外一种通过URL加载 ...
- MindSpore保存与加载模型
技术背景 近几年在机器学习和传统搜索算法的结合中,逐渐发展出了一种Search To Optimization的思维,旨在通过构造一个特定的机器学习模型,来替代传统算法中的搜索过程,进而加速经典图论等 ...
- 旷视MegEngine数据加载与处理
旷视MegEngine数据加载与处理 在网络训练与测试中,数据的加载和预处理往往会耗费大量的精力. MegEngine 提供了一系列接口来规范化这些处理工作. 利用 Dataset 封装一个数据集 数 ...
随机推荐
- ReentrantReadWriteLock可重入,锁升级,锁降级
public class ReentrantReadWriteLockTest { public static void main(String[] args) throws InterruptedE ...
- hibernate中many-to-one的not-found属性和@notfound注解
如果在Hibernate项目里面配了很多many-to-one的关联,即使后台在查询数据时已经作了健全性判断,但还是会经常抛出对象找不到异常:org.hibernate.ObjectNotFoundE ...
- PyCharm创建Django项目并连接mysql数据库
0. 安装Django pip install django 1. 新建项目 注:我的Pycharm为社区版,创建项目时,File->New Project- 显示为: 注意勾选内容. 如果 ...
- docker基础应用
环境: centos 7 docker 19.03.0-beta3 192.168.10.10 关于如何安装docker请参考:https://www.cnblogs.com/caesar-id/ ...
- 线程池---Day26
线程池思想概述 当我们要使用线程的时候就去创建一个线程时,虽然实现方便,但是会出现问题:如果并发的线程数量很多,并且每个线程都是执行一个时间很短的任务就结束了,这样频繁创建线程就会大大降低系统的效率, ...
- Windows下VS Code打开黑屏解决办法(这样真的行)
版权声明:本文为博主原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明.本文链接:https://blog.csdn.net/qq_42421611/article/d ...
- linux环境安装配置nginx
安装依赖 yum install gcc yum install pcre-devel yum install zlib zlib-devel yum install openssl openssl- ...
- nginx日志分割及备份
环境:centos7 nginx1.16.1 一.分割及备份的目的 nginx默认将日志信息写在一个文件中,时间一久日志文件中条目越来越多,文件越来越大,不方便查看,备份的时候也不需要备份重复的信息, ...
- Nginx 负载均衡实例redis
Nginx 负载均衡实例redis 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任.
- 【目录】Jmeter系列
为天地立心,为生民立命.为往圣继绝学,为万世开太平. ---<横渠四句>·张载 Jmeter(一)简介以及环境搭建 Jmeter(二)Jmeter目录介绍 Jmeter(三)Test-Pl ...