requests获取响应时间(elapsed)与超时(timeout)、小数四舍五入
前言
requests发请求时,接口的响应时间,也是我们需要关注的一个点,如果响应时间太长,也是不合理的。
如果服务端没及时响应,也不能一直等着,可以设置一个timeout超时的时间
elapsed官方文档
elapsed里面几个方法介绍
total_seconds 总时长,单位秒 days 以天为单位 microseconds (>= 0 and less than 1 second) 获取微秒部分,大于0小于1秒 seconds Number of seconds (>= 0 and less than 1 day) 秒,大于0小于1天 max = datetime.timedelta(999999999, 86399, 999999) 最大时间 min = datetime.timedelta(-999999999) 最小时间 resolution = datetime.timedelta(0, 0, 1) 最小时间单位
获取响应时间
1.获取elapsed不同的返回值
import requests
r = requests.get("https://home.cnblogs.com/u/lixy-88428977/")
print("elapsed: %s" % r.elapsed)
print("total_seconds: %s" % r.elapsed.total_seconds())
print("microseconds: %s" % r.elapsed.microseconds)
print("seconds: %s" % r.elapsed.seconds)
print("days: %s" % r.elapsed.days)
print("max: %s" % r.elapsed.max)
print("min: %s" % r.elapsed.min)
print("resolution: %s" % r.elapsed.resolution)
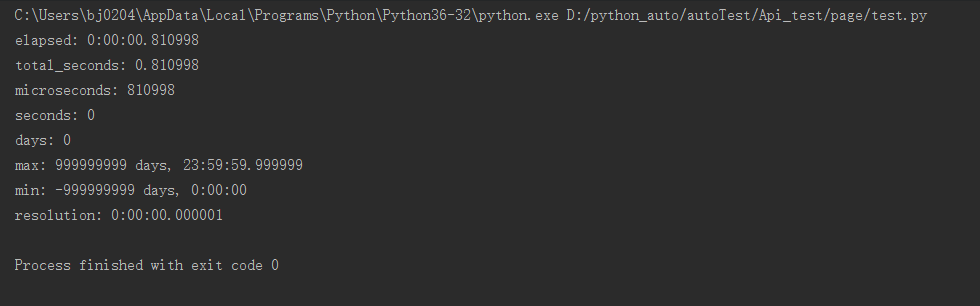
所以获取响应时间的正确姿势应该是:r.elapsed.total_seconds(),单位是s
timeout超时
1.如果一个请求响应时间比较长,不能一直等着,可以设置一个超时时间,让它抛出异常
2.如下请求,设置超时为0.5s,那么就会抛出这个异常:requests.exceptions.ConnectTimeout: HTTPConnectionPool
import requests
r = requests.get("https://home.cnblogs.com/u/lixy-88428977/", timeout=1)
print("elapsed: %s" % r.elapsed)
print("total_seconds: %s" % r.elapsed.total_seconds())
print("microseconds: %s" % r.elapsed.microseconds)

小数点后取2位(四舍五入)以及取2位(四舍五不入)的方法
一.小数点后取2位(四舍五入)的方法
方法一:round()函数
import requests
r = requests.get("https://home.cnblogs.com/u/lixy-88428977/", timeout=1)
time = r.elapsed.total_seconds()
print("原始数据: %s" % time)
print(round(time, 3))

方法二:’%.2f’ %f 方法
import requests
r = requests.get("https://home.cnblogs.com/u/lixy-88428977/", timeout=1)
time = r.elapsed.total_seconds()
print("原始数据: %s" % time)
print('%.2f' % time)

方法三:Decimal()函数
import requests
from decimal import Decimal r = requests.get("https://home.cnblogs.com/u/lixy-88428977/", timeout=1)
time = r.elapsed.total_seconds()
print("原始数据: %s" % time) a = Decimal(time).quantize(Decimal('0.00'))
print(a)

二.小数点后取2位(四舍五不入)的方法
import requests
def get_two_float(f_str, n):
f_str = str(f_str) # f_str = '{}'.format(f_str) 也可以转换为字符串
a, b, c = f_str.partition('.')
c = (c+""*n)[:n] # 如论传入的函数有几位小数,在字符串后面都添加n为小数0
return ".".join([a, c]) r = requests.get("https://home.cnblogs.com/u/lixy-88428977/", timeout=1)
time = r.elapsed.total_seconds()
print("原始数据: %s" % time) print(get_two_float(time, 2))

整理此篇文章,源于,接口自动化响应时间的获取,打印!
url = self.uri + "/json/crm/save.action"
data = self.s.post(url, data=self.testDody, verify=False)
Time = str(data.elapsed.total_seconds())
print(('响应时间: '+'%.2f'% float(Time) +'s' ))
作者:含笑半步颠√
博客链接:https://www.cnblogs.com/lixy-88428977
声明:本文为博主学习感悟总结,水平有限,如果不当,欢迎指正。如果您认为还不错,欢迎转载。转载与引用请注明作者及出处。
requests获取响应时间(elapsed)与超时(timeout)、小数四舍五入的更多相关文章
- requests获取响应时间(elapsed)与超时(timeout)
前言 requests发请求时,接口的响应时间,也是我们需要关注的一个点,如果响应时间太长,也是不合理的.如果服务端没及时响应,也不能一直等着,可以设置一个timeout超时的时间 关于request ...
- python接口自动化20-requests获取响应时间(elapsed)与超时(timeout) ok试了 获取响应时间的
前言 requests发请求时,接口的响应时间,也是我们需要关注的一个点,如果响应时间太长,也是不合理的.如果服务端没及时响应,也不能一直等着,可以设置一个timeout超时的时间 关于request ...
- python接口自动化20-requests获取响应时间(elapsed)与超时(timeout)
前言 requests发请求时,接口的响应时间,也是我们需要关注的一个点,如果响应时间太长,也是不合理的. 如果服务端没及时响应,也不能一直等着,可以设置一个timeout超时的时间 关于reques ...
- request的响应时间elapsed和超时timeout
前言:requests发请求时,接口的响应时间,也是我们需要关注的一个点,如果响应时间太长,也是不合理的 1.获取接口请求的响应时间 r.elapsed.total_seconds() import ...
- 爬虫 Http请求,urllib2获取数据,第三方库requests获取数据,BeautifulSoup处理数据,使用Chrome浏览器开发者工具显示检查网页源代码,json模块的dumps,loads,dump,load方法介绍
爬虫 Http请求,urllib2获取数据,第三方库requests获取数据,BeautifulSoup处理数据,使用Chrome浏览器开发者工具显示检查网页源代码,json模块的dumps,load ...
- axios超时timeout拦截
应用场景: 在网络请求中,可能不可避免的会遇到网络差或者请求超时的情况,这时候,如果你采用的技术是axios,那就可以通过设置拦截器捕获这个异常情况,并做出下一步处理. 代码实践: ① 设置拦截器,返 ...
- requests获取所有状态码
requests获取所有状态码 requests默认是不会获取301/302的状态码的.可以设置allow_redirects=False,这样就可以获取所有的状态码了 import requests ...
- python3爬虫-通过requests获取拉钩职位信息
import requests, json, time, tablib def send_ajax_request(data: dict): try: ajax_response = session. ...
- 解决requests获取源代码时中文乱码问题
用requests获取源代码时,如果是中文网页,就可能会出现乱码,下面我以中关村的网站为例: import requests url = 'http://desk.zol.com.cn/meinv/' ...
随机推荐
- riscv 汇编与反汇编
为了riscv指令集,我们需要汇编与反汇编工具来分析指令格式. 可以用下面的两个工具来汇编和反汇编,下载链接:https://pan.baidu.com/s/1eUbBlVc riscv-none-e ...
- 简单mvc---模拟Springmvc
1.注解篇 Auwowrited package org.aaron.mvc.annaotation; import java.lang.annotation.Documented; import j ...
- ARM开发板上查看动态库或者可执行程序的依赖关系
以ARM32开发板为例,在/lib下有一个名为ld-linux-armhf.so.3的可执行程序(在ARM64开发板上是/lib/ld-linux-aarch64.so.1),这个程序负责加载可执行程 ...
- 可变lambda, lambda使用mutable关键字
关于lambda的捕获和调用 C++ primer上对可变lambda举的例子如下: size_t v1=42; auto f=[v1] () mutable{return ++v1; }; v1=0 ...
- 使用pipenv管理虚拟环境
使用pipenv管理虚拟环境 安装 pip install pipenv 命令介绍 pipenv --help Usage: pipenv [OPTIONS] COMMAND [ARGS]... Op ...
- django 解析上传xls文件
1.解析上传数据 class DataUploadAPIView(APIView): # authentication_classes = (JSONWebTokenAuthentication, S ...
- hbase运行原理
HBase特点 1)海量存储 Hbase适合存储PB级别的海量数据,在PB级别的数据以及采用廉价PC存储的情况下,能在几十到百毫秒内返回数据.这与Hbase的极易扩展性息息相关.正式因为Hbase良好 ...
- MAC上配置idea环境时排查问题
现象:没有使用走公司maven仓库的setting.xml文件时,只有公司内部依赖 没有找到在idea的maven配置中指定 公司setting.xml后,所有的文件都提示找不到 解决办法:把公司se ...
- ABP JS调用接口 获取返回的数据
var _userService = abp.services.app.user; console.log(abp.services.app.user); _userService.getUserBy ...
- docker 部署 jenkins
建议使用的Docker映像是jenkinsci/blueocean image(来自 the Docker Hub repository). 该镜像包含当前的长期支持 (LTS) 的Jenkins版本 ...