【idea】scala&sbt+idea+spark使用过程中问题汇总(不定期更新)
本地模式问题系列:
问题一:会报如下很多NoClassDefFoundError的错误,原因缺少相关依赖包
Exception in thread "main" java.lang.NoClassDefFoundError: org/apache/hadoop/fs/FSDataInputStream
at org.apache.spark.SparkConf.loadFromSystemProperties(SparkConf.scala:76)
at org.apache.spark.SparkConf.<init>(SparkConf.scala:71)
at org.apache.spark.SparkConf.<init>(SparkConf.scala:58)
at com.hadoop.sparkPi$.main(sparkPi.scala:9)
at com.hadoop.sparkPi.main(sparkPi.scala)
Caused by: java.lang.ClassNotFoundException: org.apache.hadoop.fs.FSDataInputStream
at java.net.URLClassLoader.findClass(URLClassLoader.java:381)
at java.lang.ClassLoader.loadClass(ClassLoader.java:424)
at sun.misc.Launcher$AppClassLoader.loadClass(Launcher.java:335)
at java.lang.ClassLoader.loadClass(ClassLoader.java:357)
... 5 more
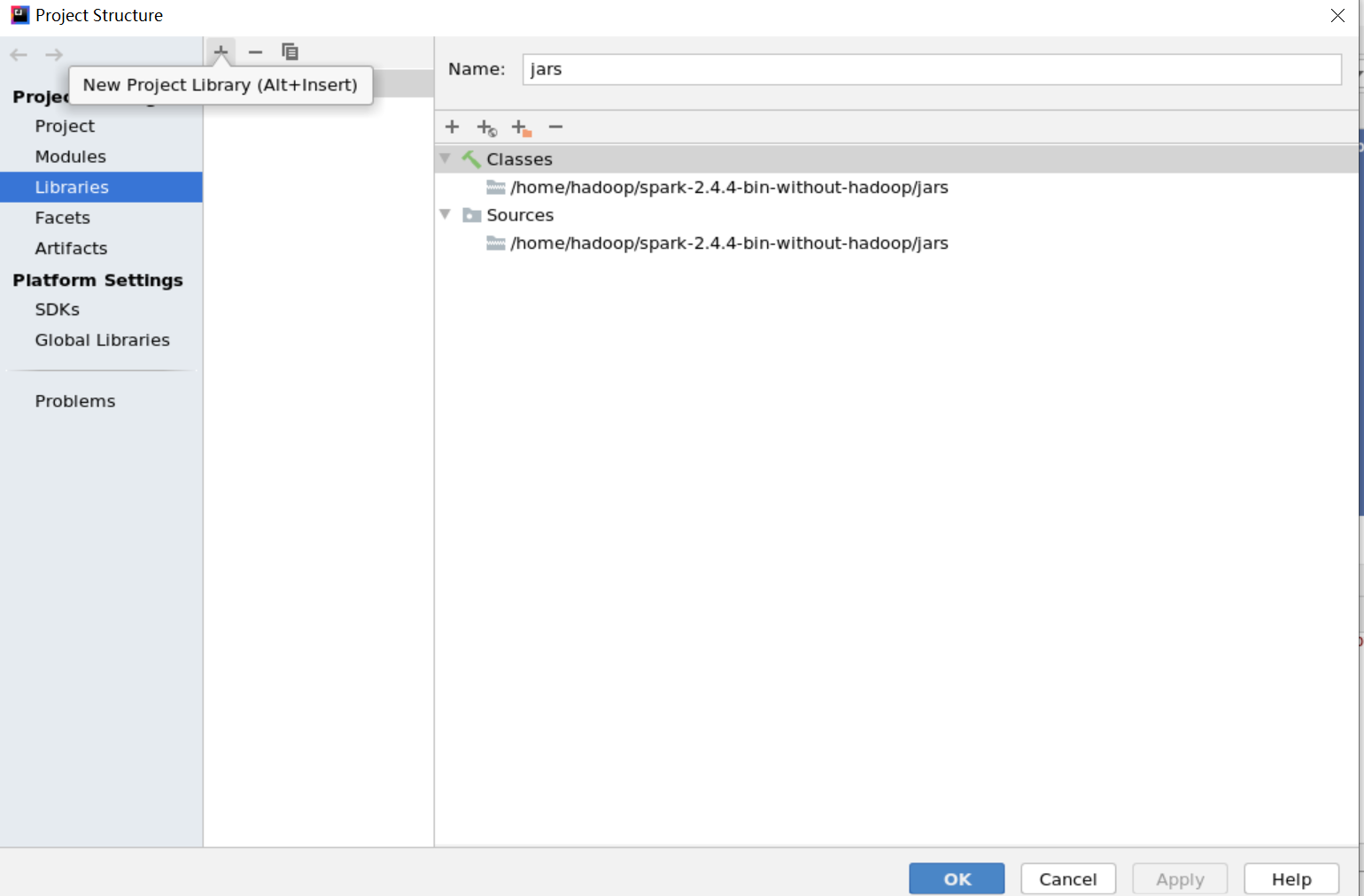
解决办法:下载相关缺少的依赖包,并在idea工程界面加入依赖包,路径为:file -- project structure -- libraries 中,点击左上角“+”符号添加依赖包的路径
问题二:Spark是非常依赖内存的计算框架,在虚拟环境下使用local模式时,实际上是使用多线程的形式模拟集群进行计算,因而对于计算机的内存有一定要求,这是典型的因为计算机内存不足而抛出的异常。
Exception in thread "main" java.lang.IllegalArgumentException: System memory 425197568 must be at least 471859200.
Please increase heap size using the --driver-memory option or spark.driver.memory in Spark configuration.
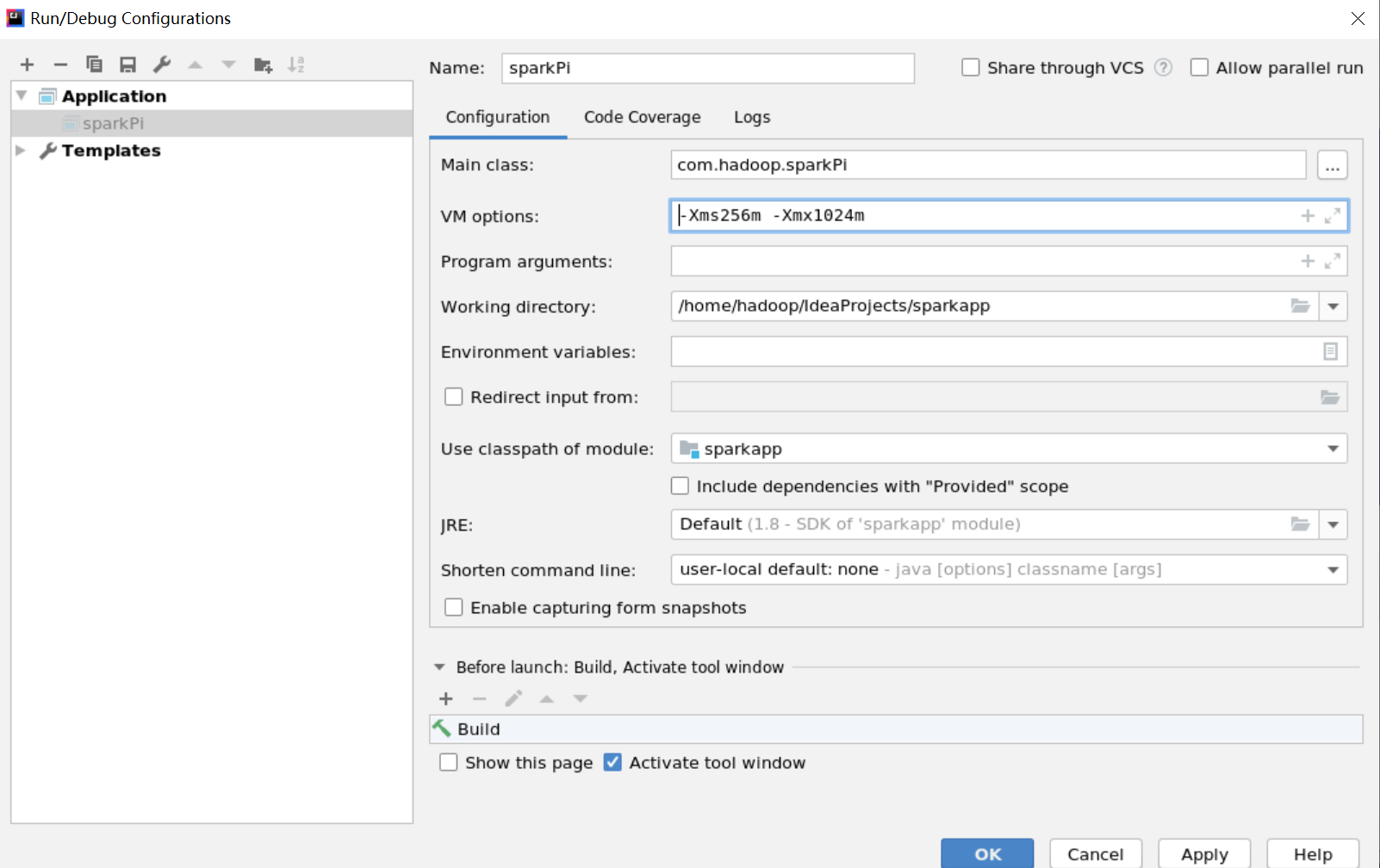
解决办法:修改代码或者设置-Xms256m -Xmx1024m
val conf = new SparkConf().setMaster("local").setAppName("sparkPi") //修改之前
val conf = new SparkConf().setMaster("local").setAppName("sparkPi").set("spark.testing.memory","2147480000") //修改之后
或
【idea】scala&sbt+idea+spark使用过程中问题汇总(不定期更新)的更多相关文章
- (转)CloudStack 安装及使用过程中常见问题汇总
CloudStack 安装及使用过程中常见问题汇总 在做工程项目中对CloudStack 安装及使用过程中常见的几个问题及如何解决做一个总结. 1.Windows XP虚拟 ...
- Windows系统安装MySQL详细教程和安装过程中问题汇总(命令安装),更新时间2021-12-8
安装包下载 下载地址:https://dev.mysql.com/downloads/mysql/ 点击下载之后,可以选择注册Oracle账号,也可以跳过直接下载. 下载完成后,选择一个磁盘内放置并解 ...
- Python ctypes 在 Python 2 和 Python 3 中的不同 // 使用ctypes过程中问题汇总
In Python 2.7, strings are byte-strings by default. In Python 3.x, they are unicode by default. Try ...
- Android 环境搭建资料及启动过程中问题汇总
一.环境搭建资料 推荐谷歌自己开发的Android Studio 工具可以从这个网址下载:http://tools.android-studio.org/,直接下载推荐的就行 二.安装 安装时最好指定 ...
- PHP开发过程中数组汇总 [ 持续更新系列 ]
开发过程中经常会使用到数组函数,故特地总结出来,自己熟悉,同时供大家参考!(实例部分会抽空尽快完成) 一.目录 array_merge(); 合并数组 array_keys(); array_filt ...
- sbt打包Scala写的Spark程序,打包正常,提交运行时提示找不到对应的类
sbt打包Scala写的Spark程序,打包正常,提交运行时提示找不到对应的类 详述 使用sbt对写的Spark程序打包,过程中没有问题 spark-submit提交jar包运行提示找不到对应的类 解 ...
- 什么是Spark(四)运算过程中的黑科技
Spark在运算过程中提供了一套完整的机制用来提高效率. 1. 用于收集信息的Accumulator,自带增量,用于spark全局收集数据:共享数据: 2. 用于提高传输速率的broadcast机制: ...
- Spark在Ubuntu中搭建开发环境
一.在Windows7中安装Ubuntu双系统 工具/原料 windows7 64位 ubuntu 16.04 32位 UltraISO最新版(用来将镜像文件烤到U盘中) 空U盘(若有文件,请先备 ...
- emacs+ensime+sbt打造spark源码阅读环境
欢迎转载,转载请注明出处,徽沪一郎. 概述 Scala越来越流行, Spark也愈来愈红火, 对spark的代码进行走读也成了一个很普遍的行为.不巧的是,当前java社区中很流行的ide如eclips ...
随机推荐
- [转]curl 命令模拟 HTTP GET/POST 请求
在 Linux 操作系统上对后端程序进行测试的时候,需要进行模拟连接或者书写测试脚本 curl 访问百度,通过GET方法请求 命令格式: curl protocol://address:port/ur ...
- vue---自定义指令的使用
在vue开发项目中,指令的使用场景也是比较多的,那么该如何定义使用呢? 找到 src / directive 下新建 gender 目录,下面新建 index.js 和 gender.js index ...
- Android dump命令查看某个apk是被谁安装的?
adb shell dumpsys package packages > packageAll.txt ORadb shell pm dump packages > package ...
- Python之schedule用法,类似linux下的crontab
# -*- coding: utf-8 -*- # author:baoshan import schedule import time def job(): print("I'm work ...
- FormsAuthentication使用指南,实现登录
一般情况下,在我们做访问权限管理的时候,会把用户的正确登录后的基本信息保存在Session中,以后用户每次请求页面或接口数据的时候,拿到Session中存储的用户基本信息,查看比较他有没有登录和能否访 ...
- [LeetCode] 168. Excel Sheet Column Title 求Excel表列名称
Given a positive integer, return its corresponding column title as appear in an Excel sheet. For exa ...
- ECS与EDAS什么意思?
1.ECS 英文:Elastic Compute Service 简称云服务器 2.EDAS英文:Enterprise Distributed Application Service 企业级分布 ...
- Github-Dorks与辅助工具
前言 Github搜索功能非常强大且有用,可用于在开源出来的Github仓库中搜索敏感数据.可以找到敏感的个人和/或组织信息(例如私钥,凭据,身份验证令牌等). 文中的github dork列表可以在 ...
- Consul ACL集群配置说明以及ACL Token的用法
在上一篇文章里面,我们讲了如何搭建带有Acl控制的Consul集群.这一篇文章主要讲述一下上一篇文章那一大串配置文件的含义. 1.配置说明#1.1 勘误上一篇文章关于机器规划方面,consul cli ...
- springboot整合log4j2遇到的一个坑
背景 项目中使用springboot,需要用log4j2做日志框架 问题 项目启动报错:Could not initialize Log4J2 logging from classpath:log4j ...