HDFS读流程
客户端先与NameNode通信,获取block位置信息,之后线性地先取第一个块,然后接二连三地获取,取回一个块时会进行MD5验证,验证通过后会使read顺利进行完,当最终读完所有的block块之后,拼起来就是一个完整的源文件,数据本地化读取是分布式计算中计算向数据移动的一大特征,block块有偏移量和位置信息,HDFS分布式文件系统优化了读取性能,客户端会根据block的信息来分辨这些副本中,哪些副本距离客户端自身最近,那么本地、同机架、以及其他DataNode会是一个由近及远的排序,后面我们再分析MapReduce源代码的时候,会再进行分析这一优化特性。请先记住HDFS读流程的两个重要特性:
(1) block信息的MD5验证
(2) 读取block时距离优先顺序的优化。
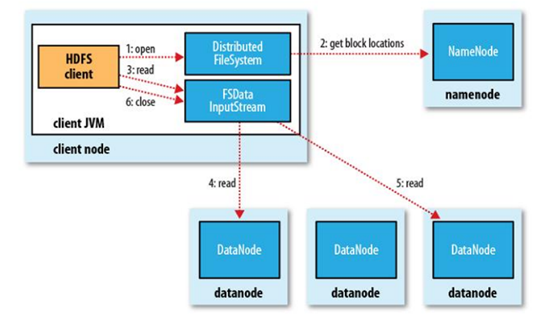
图1.8 HDFS读流程来自《Hadoop:The Definitive Guide》一书
读取文件的具体方式如下:
1. 从Hadoop URL读取数据
要从Hadoop文件系统中读取文件,最简单的方法是使用java.net.URl对象打开数据流,从中读取文件。但是,如何让java程序能够识别Hadoop的hdfs URL呢?这里采用的方法是通过调用java.net.URL对象的setURLStreamHandlerFactory方法,方法中传入FsUrlStreamHandlerFactory的一个实例,就可以让java程序可以识别hadoop的hdfs URL。每个java虚拟机只能调用一次这个setURLStreamHandlerFactory方法,因此通常将其卸载静态方法中。
示例程序:在hdfs中存在着/install.log,
public class test {
static {
URL.setURLStreamHandlerFactory(new FsUrlStreamHandlerFactory());
}
@Test
public void readByUrl() {
InputStream in = null;
try {
in = new URL("hdfs://node1:9000/install.log").openStream();
} catch (IOException e) {
}finally{
IOUtils.closeStream(in);
}
}
}
连不上集群。需要将core-site和hdfs-site放入到src目录下。
2.通过FileSysem API读取数据
正如前一小节所解释,有时不可能在应用程序中设置URLStreamhandlerFactory实例,这种情况下,需要用到FileSystem API来打开一个文件的输入流。Hadoop文件系统中通过Hadoop Path对象来代表文件。FileSystem是一个通用的文件系统API,这个类第一步是检索我们需要使用的文件系统实例,这里是HDFS。利用FileSystem.get()获取FilsSystem实例。Configuration对象封装了客户端或服务器的配置,一般讲hdfs的配置文件(将core-site.xml和hdft-site.xml放到项目的src目录下,configuration实例化的时候就会自动获取)。具体代码如下。
示例程序:在hdfs中存在着/install.log,
@Test
public void readByFileSystem() throws Exception{
String Url = "hdfs://node1:9000/install.log";
//FileSystem fs = FileSystem.get(URI.create(Url), conf);
Configuration conf = new Configuration();
FileSystem fs = FileSystem.get(conf);
InputStream in = null;
in = fs.open(new Path(Url));
IOUtils.copyBytes(in, System.out, 4096,true);
}
HDFS读流程的更多相关文章
- 大数据系列文章-Hadoop的HDFS读写流程(二)
在介绍HDFS读写流程时,先介绍下Block副本放置策略. Block副本放置策略 第一个副本:放置在上传文件的DataNode:如果是集群外提交,则随机挑选一台磁盘不太满,CPU不太忙的节点. 第二 ...
- 【转】HDFS读写流程
概述开始之前先看看其基本属性,HDFS(Hadoop Distributed File System)是GFS的开源实现. 特点如下: 能够运行在廉价机器上,硬件出错常态,需要具备高容错性流式数据访问 ...
- Hadoop之HDFS读写流程
hadoophdfs 1. HDFS写流程 2. HDFS写流程 1. HDFS写流程 HDFS写流程 副本存放策略: 上传的数据块后,触发一个新的线程,进行存放. 第一个副本:与client最近的机 ...
- HDFS读写流程(转载)
概述开始之前先看看其基本属性,HDFS(Hadoop Distributed File System)是GFS的开源实现.特点如下: 能够运行在廉价机器上,硬件出错常态,需要具备高容错性 ...
- RPC简介与hdfs读过程与写过程简介
1.RPC简介 Remote Procedure Call 远程过程调用协议 RPC——远程过程调用协议,它是一种通过网络从远程计算机程序上请求服务,而不需要了解底层网络技术的协议.RPC协议假定某些 ...
- 超详细的HDFS读写流程详解(最容易理解的方式)
HDFS采用的是master/slaves这种主从的结构模型管理数据,这种结构模型主要由四个部分组成,分别是Client(客户端).Namenode(名称节点).Datanode(数据节点)和Seco ...
- Raid1源代码分析--读流程(重新整理)
五.Raid1读流程分析 两个月前,刚刚接触raid1,就阅读了raid1读流程的代码,那个时候写了一篇博客.现在回过头看看,那篇的错误很多,并且很多地方没有表述清楚.所以还是决定重新写一篇以更正之前 ...
- Raid1源代码分析--读流程
这篇博文不足之处较多,重新整理了一下,链接:http://www.cnblogs.com/fangpei/p/3890873.html 我阅读的代码的linux内核版本是2.6.32.61.刚进实验室 ...
- HDFS读写流程learning
有许多对流程进行描述的博客,但是感觉还是应当学习一遍代码,不然总感觉怪怪的,https://blog.csdn.net/popsuper1982/article/details/51615285,首先 ...
随机推荐
- 运维笔记--linux下忘记mysql root密码
补充链接:Windows下忘记密码处理: https://www.cnblogs.com/hellojesson/p/5972950.html 场景描述: Linux环境下忘记 root 密码, 1. ...
- (2)PyCharm开发Flash项目之蓝图构建
下面通过在PyCharm开发工具中创建一个简单的Flask项目来体会一下Flask的蓝图构建(Blueprint). 何谓蓝图:在Flask中蓝图就在大型应用中,将不同功能的模块(module)分开管 ...
- Sword C语言原子操作
/* gcc内置原子操作 */ #include <stdio.h> /* 知识补充: gcc 4.1.2版本之后,对X86或X86_64支持内置原子操作.即不需要引入第三方库(如pthr ...
- [LeetCode] 535. Encode and Decode TinyURL 编码和解码短网址
Note: This is a companion problem to the System Design problem: Design TinyURL. TinyURL is a URL sho ...
- QualityCenter(QC)—测试管理工具
简介 Quality Center是一个基于Web的测试管理工具,可以组织和管理应用程序测试流程的所有阶段,包括制定测试需求.计划测试.执行测试和跟踪缺陷.此外,通过Quality Center还可以 ...
- 从一个案例窥探ORACLE的PASSWORD_VERSIONS
1.环境说明 ORACLE 客户端版本 11.2.0.1 ORACLE 服务端版本 12.2.0.1 2.异常现象 客户端(下文也称为Cp)访问服务端(Sp),报了一个错误: Figure 1 以错误 ...
- eNSP上配置RIPv2的认证
实验拓扑图如下 首先我们对各个路由器及终端PC进行基本ip设置 然后我们在路由器上设置RIPv2协议 并添加要通告的网段 然后我们查看路由表查看路由器已经学到的路由 接下来我们用R3模拟攻击者 通过 ...
- Qt deletelater函数分析(2)
夫唯不争,故天下莫能与之争 -- 老子 在C++中,delete 和 new 必须 配对使用,Qt作为C++的库,显然是不会违背C++原则.但是,qt有自己的内存管理,有时候虽然使用了new, ...
- excel文件导出和导入
pom.xml添加依赖 @RestController @RequestMapping(value = "/excel") public class ExpImpExcelCont ...
- 《Redis Mysql 双写一致性问题》
一:序 - 最近在对数据做缓存时候,会涉及到如何保证 数据库/Redis 一致性问题. - 刚好今天来总结下 一致性问题 产生的问题,和可能存在的解决方案. 二:(更新策略)- 先更新数据库,后更新 ...