【转】HDFS读写流程
概述
开始之前先看看其基本属性,HDFS(Hadoop Distributed File System)是GFS的开源实现。
特点如下:
能够运行在廉价机器上,硬件出错常态,需要具备高容错性
流式数据访问,而不是随机读写
面向大规模数据集,能够进行批处理、能够横向扩展
简单一致性模型,假定文件是一次写入、多次读取
缺点:
不支持低延迟数据访问
不适合大量小文件存储(因为每条元数据占用空间是一定的)
不支持并发写入,一个文件只能有一个写入者
不支持文件随机修改,仅支持追加写入
HDFS中的block、packet、chunk
很多博文介绍HDFS读写流程上来就直接从文件分块开始,其实,要把读写过程细节搞明白前,你必须知道block、packet与chunk。下面分别讲述。
block
这个大家应该知道,文件上传前需要分块,这个块就是block,一般为128MB,当然你可以去改,不顾不推荐。因为块太小:寻址时间占比过高。块太大:Map任务数太少,作业执行速度变慢。它是最大的一个单位。
packet
packet是第二大的单位,它是client端向DataNode,或DataNode的PipLine之间传数据的基本单位,默认64KB。
chunk
chunk是最小的单位,它是client向DataNode,或DataNode的PipLine之间进行数据校验的基本单位,默认512Byte,因为用作校验,故每个chunk需要带有4Byte的校验位。所以实际每个chunk写入packet的大小为516Byte。由此可见真实数据与校验值数据的比值约为128 : 1。(即64*1024 / 512)
例如,在client端向DataNode传数据的时候,HDFSOutputStream会有一个chunk buff,写满一个chunk后,会计算校验和并写入当前的chunk。之后再把带有校验和的chunk写入packet,当一个packet写满后,packet会进入dataQueue队列,其他的DataNode就是从这个dataQueue获取client端上传的数据并存储的。同时一个DataNode成功存储一个packet后之后会返回一个ack packet,放入ack Queue中。
HDFS写流程
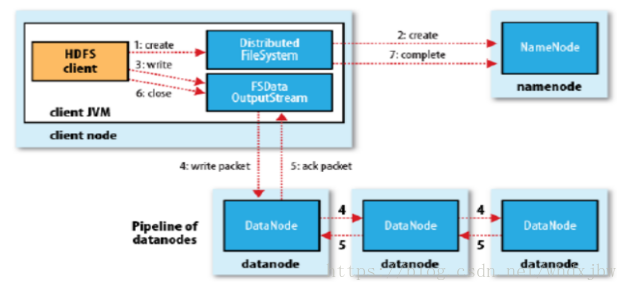
写详细步骤:
客户端向NameNode发出写文件请求。
检查是否已存在文件、检查权限。若通过检查,直接先将操作写入EditLog,并返回输出流对象。
(注:WAL,write ahead log,先写Log,再写内存,因为EditLog记录的是最新的HDFS客户端执行所有的写操作。如果后续真实写操作失败了,由于在真实写操作之前,操作就被写入EditLog中了,故EditLog中仍会有记录,我们不用担心后续client读不到相应的数据块,因为在第5步中DataNode收到块后会有一返回确认信息,若没写成功,发送端没收到确认信息,会一直重试,直到成功)
client端按128MB的块切分文件。
client将NameNode返回的分配的可写的DataNode列表和Data数据一同发送给最近的第一个DataNode节点,此后client端和NameNode分配的多个DataNode构成pipeline管道,client端向输出流对象中写数据。client每向第一个DataNode写入一个packet,这个packet便会直接在pipeline里传给第二个、第三个…DataNode。
(注:并不是写好一个块或一整个文件后才向后分发)
每个DataNode写完一个块后,会返回确认信息。
(注:并不是每写完一个packet后就返回确认信息,个人觉得因为packet中的每个chunk都携带校验信息,没必要每写一个就汇报一下,这样效率太慢。正确的做法是写完一个block块后,对校验信息进行汇总分析,就能得出是否有块写错的情况发生)
写完数据,关闭输输出流。
发送完成信号给NameNode。
(注:发送完成信号的时机取决于集群是强一致性还是最终一致性,强一致性则需要所有DataNode写完后才向NameNode汇报。最终一致性则其中任意一个DataNode写完后就能单独向NameNode汇报,HDFS一般情况下都是强调强一致性)
HDFS读流程

读相对于写,简单一些
读详细步骤:
client访问NameNode,查询元数据信息,获得这个文件的数据块位置列表,返回输入流对象。
就近挑选一台datanode服务器,请求建立输入流 。
DataNode向输入流中中写数据,以packet为单位来校验。
关闭输入流
读写过程,数据完整性如何保持?
通过校验和。因为每个chunk中都有一个校验位,一个个chunk构成packet,一个个packet最终形成block,故可在block上求校验和。
HDFS 的client端即实现了对 HDFS 文件内容的校验和 (checksum) 检查。当客户端创建一个新的HDFS文件时候,分块后会计算这个文件每个数据块的校验和,此校验和会以一个隐藏文件形式保存在同一个 HDFS 命名空间下。当client端从HDFS中读取文件内容后,它会检查分块时候计算出的校验和(隐藏文件里)和读取到的文件块中校验和是否匹配,如果不匹配,客户端可以选择从其他 Datanode 获取该数据块的副本。
HDFS中文件块目录结构具体格式如下:
${dfs.datanode.data.dir}/
├── current
│ ├── BP-526805057-127.0.0.1-1411980876842
│ │ └── current
│ │ ├── VERSION
│ │ ├── finalized
│ │ │ ├── blk_1073741825
│ │ │ ├── blk_1073741825_1001.meta
│ │ │ ├── blk_1073741826
│ │ │ └── blk_1073741826_1002.meta
│ │ └── rbw
│ └── VERSION
└── in_use.lock
in_use.lock表示DataNode正在对文件夹进行操作
rbw是“replica being written”的意思,该目录用于存储用户当前正在写入的数据。
Block元数据文件(*.meta)由一个包含版本、类型信息的头文件和一系列校验值组成。校验和也正是存在其中。
若有其他好的细节,欢迎大家补充交流!
---------------------
作者:bw_233
来源:CSDN
原文:https://blog.csdn.net/whdxjbw/article/details/81072207
版权声明:本文为博主原创文章,转载请附上博文链接!
【转】HDFS读写流程的更多相关文章
- 大数据系列文章-Hadoop的HDFS读写流程(二)
在介绍HDFS读写流程时,先介绍下Block副本放置策略. Block副本放置策略 第一个副本:放置在上传文件的DataNode:如果是集群外提交,则随机挑选一台磁盘不太满,CPU不太忙的节点. 第二 ...
- HDFS读写流程(转载)
概述开始之前先看看其基本属性,HDFS(Hadoop Distributed File System)是GFS的开源实现.特点如下: 能够运行在廉价机器上,硬件出错常态,需要具备高容错性 ...
- 超详细的HDFS读写流程详解(最容易理解的方式)
HDFS采用的是master/slaves这种主从的结构模型管理数据,这种结构模型主要由四个部分组成,分别是Client(客户端).Namenode(名称节点).Datanode(数据节点)和Seco ...
- Hadoop之HDFS读写流程
hadoophdfs 1. HDFS写流程 2. HDFS写流程 1. HDFS写流程 HDFS写流程 副本存放策略: 上传的数据块后,触发一个新的线程,进行存放. 第一个副本:与client最近的机 ...
- HDFS 读写流程-译
HDFS 文件读取流程 Client 端调用 DistributedFileSystem 对象的 open() 方法. 由 DistributedFileSystem 通过 RPC 向 NameNod ...
- HDFS 读写流程-英
HDFS 文件读取流程 The client opens the file it wishes to read by calling open() on the FileSystem object, ...
- HDFS读写流程(重点)
@ 目录 一.写数据流程 举例: 二.异常写流程 读数据流程 一.写数据流程 ①服务端启动HDFS中的NN和DN进程 ②客户端创建一个分布式文件系统客户端,由客户端向NN发送请求,请求上传文件 ③NN ...
- HDFS读写流程learning
有许多对流程进行描述的博客,但是感觉还是应当学习一遍代码,不然总感觉怪怪的,https://blog.csdn.net/popsuper1982/article/details/51615285,首先 ...
- HDFS读写流程
01.并行读取 02.逐个节点写入
随机推荐
- go之结构体
一.关于结构体 简述 1.go 语言的切片可以存储同一类型的数据,但是结构体可以为不同项定义不同的数据类型 2.结构体是有一系列具有相同类型或不同类型的数据构成的数据集合 3.因为go 没有类似于类的 ...
- jdbc 接口学习笔记
一.JDBC概念 JDBC(Java Data Base Connectivity,java数据库连接)是一种用于执行SQL语句的Java API,可以为多种关系型数据库提供统一访问,它由一组用Jav ...
- ruby --Paperclip::NotIdentifiedByImageMagickError
首先,如果遇到这个问题,Paperclip::NotIdentifiedByImageMagickError,先检查下环境变量是否配置了ImagicMagick的路径. cmd下path 查看,首先加 ...
- 树莓派-USB存储设备自动挂载
简单介绍实现命令行下USB存储设备自动挂载的方法,Linux gnome/kde窗口环境下有移动存储的管理程序,可以实现自动挂载移动存储设备,但是在命令行下 通常需要用mount命令手动挂载USB存储 ...
- 5.20rieds切换数据库
- 20小时掌握网站开发(免费精品htmlcss视频教程)
自己最近研发了一套新的htmlcss教程,并进行了授课实施,视频教程百度云下载链接如下: 视频及案例源码下载地址 本套教程视频需要安装屏幕录像专家软件才能观看,屏幕录像专家下载地址如下: 屏幕录像专家 ...
- java ---书写自己的名字
public class hello { public static void main(String[] args) { // TODO 自动生成的方法存根 System.out.println(& ...
- 三维重建:SLAM的粒度和工程化问题
百度百科的定义.此文引用了其他博客的一些图像,如有侵权,邮件联系删除. 申明一下,SLAM不是一个算法,而是一个工程. 在计算机视觉中, 三维重建是指根据单视图或者多视图的图像重建三维信息的过程. 由 ...
- 集合运算(UNION)
表的加法 集合运算:就是满足统一规则的记录进行的加减等四则运算. 通过集合运算可以得到两张表中记录的集合或者公共记录的集合,又或者其中某张表中记录的集合. 集合运算符:用来进行集合的运算符. UNIO ...
- 【转载】深入理解Java的接口和抽象类
深入理解Java的接口和抽象类 对于面向对象编程来说,抽象是它的一大特征之一.在Java中,可以通过两种形式来体现OOP的抽象:接口和抽象类.这两者有太多相似的地方,又有太多不同的地方.很多人在初学的 ...