在Ubuntu上搭建Hadoop群集
前面我搭建的Hadoop都是单机伪分布式的,并不能真正感受到Hadoop的最大特点,分布式存储和分布式计算。所以我打算在虚拟机中同时开启3台机器,实现分布式的Hadoop群集。
1.准备3台Ubuntu Server
1.1复制出3台虚拟机
我们可以用之前编译和安装好Hadoop的虚拟机作为原始版本,在VirtualBox中复制三台新的虚拟机出来,也可以完全重新安装一台全新的Ubuntu Server,然后在VirtualBox中复制出2台,就变成了3台虚拟机。
1.2修改主机名
主机名保存在/etc/hostname文件中,我们可以运行
sudo vi /etc/hostname
命令,然后为三台机器起不同的名字,这里我们就分别起名:
master
slave01
slave02
1.3修改为固定IP
Ubuntu的IP地址保存到/etc/network/interfaces文件中,我们需要为3台虚拟机分别改为固定的IP,这里我的环境是在192.168.100.*网段,所以我打算为master改为192.168.100.40,操作如下:
sudo vi /etc/network/interfaces
然后可以看到每个网卡的配置,我这里网卡名是叫enp0s3,所以我改对应的内容为:
# The primary network interface
auto enp0s3
iface enp0s3 inet static
address 192.168.100.40
gateway 192.168.100.1
netmask 255.255.255.0
对slave01改为192.168.100.41,slave02改为192.168.100.42。
1.4修改Hosts
由于三台虚拟机是使用的默认的DNS,所以我们需要增加hosts记录,才能直接用名字相互访问。hosts文件和Windows的Hosts文件一样,就是一个域名和ip的对应表。
编辑hosts文件:
sudo vi /etc/hosts
增加三条记录:
192.168.100.40 master
192.168.100.41 slave01
192.168.100.42 slave02
1.5重启
这一切修改完毕后我们重启一下三台机器,然后可以试着各自ping master,ping slave01 ping slave02看能不能通。按照上面的几步操作,应该是没有问题的。
1.6新建用户和组
这一步不是必须的,就采用安装系统后的默认用户也是可以的。
sudo addgroup hadoop
sudo adduser --ingroup hadoop hduser
为了方便,我们还可以把hduser添加到sudo这个group中,那么以后我们在hduser下就可以运行sudo xxx了。
sudo adduser hduser sudo
切换到hduser:
su – hduser
1.7配置无密码访问SSH
在三台机器上首先安装好SSH
sudo apt-get install ssh
然后运行
ssh-keygen
默认路径,无密码,会在当前用户的文件夹中产生一个.ssh文件夹。
接下来我们先处理master这台机器的访问。我们进入这个文件夹,
cd .ssh
然后允许无密码访问,执行:
cp id_rsa.pub authorized_keys
然后要把slave01和slave02的公钥传给master,进入slave01
scp ~/.ssh/id_rsa.pub hduser@master:/home/hduser/.ssh/id_rsa.pub.slave01
然后在slave02上也是:
scp ~/.ssh/id_rsa.pub hduser@master:/home/hduser/.ssh/id_rsa.pub.slave02
将 slave01 和 slave02的公钥信息追加到 master 的 authorized_keys文件中,切换到master机器上,执行:
cat id_rsa.pub.slave01 >> authorized_keys
cat id_rsa.pub.slave02 >> authorized_keys
现在authorized_keys就有3台机器的公钥,可以无密码访问任意机器。只需要将authorized_keys复制到slave01和slave02即可。在master上执行:
scp authorized_keys hduser@slave01:/home/hduser/.ssh/authorized_keys
scp authorized_keys hduser@slave02:/home/hduser/.ssh/authorized_keys
最后我们可以测试一下,在master上运行
ssh slave01
如果没有提示输入用户名密码,而是直接进入,就说明我们配置成功了。
同样的方式测试其他机器的无密码ssh访问。
2.安装相关软件和环境
如果是直接基于我们上一次安装的单机Hadoop做的虚拟机,那么这一步就可以跳过了,如果是全新的虚拟机,那么就需要做如下操作:
2.1配置apt source,安装JDK
sudo vi /etc/apt/sources.list
打开后把里面的us改为cn,如果已经是cn的,就不用再改了。然后运行:
sudo apt-get update
sudo apt-get install default-jdk
2.2下载并解压Hadoop
去Hadoop官网,找到最新稳定版的Hadoop下载地址,然后下载。当然如果是X64的Ubuntu,我建议还是本地编译Hadoop,具体编译过程参见这篇文章。
wget http://www.apache.org/dyn/closer.cgi/hadoop/common/hadoop-2.7.3/hadoop-2.7.3.tar.gz
下载完毕后然后是解压
tar xvzf hadoop-2.7.3.tar.gz
最后将解压后的Hadoop转移到正式的目录下,这里我们打算使用/usr/local/hadoop目录,所以运行命令:
sudo mv hadoop-2.7.3 /usr/local/hadoop
3.配置Hadoop
3.1配置环境变量
编辑.bashrc或者/etc/profile文件,增加如下内容:
# Java Env
export JAVA_HOME=/usr/lib/jvm/java-7-openjdk-amd64
export JRE_HOME=$JAVA_HOME/jre
export CLASSPATH=.:$JAVA_HOME/lib/tools.jar:$JAVA_HOME/lib/dt.jar:$JRE_HOME/lib
export PATH=$PATH:$JAVA_HOME/bin:$JRE_HOME/bin
# Hadoop Env
export HADOOP_HOME=/usr/local/hadoop
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
3.2进入Hadoop的配置文件夹:
cd /usr/local/hadoop/etc/hadoop
(1)修改hadoop-env.sh
增加如下配置:
export JAVA_HOME=/usr/lib/jvm/java-7-openjdk-amd64
export HADOOP_PREFIX=/usr/local/hadoop
(2)修改core-site.xml
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hduser/temp</value>
<description>A base for other temporary directories.</description>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
</configuration>
这里我们指定了一个临时文件夹的路径,这个路径必须存在,而且有权限访问,所以我们在hduser下创建一个temp目录。
(3)hdfs-site.xml
设置HDFS复制的数量
<configuration>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
</configuration>
(4)mapred-site.xml
这里可以设置MapReduce的框架是YARN:
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
(5)配置YARN环境变量,打开yarn-env.sh
里面有很多行,找到JAVA_HOME,设置:
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64
(6)配置yarn-site.xml
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
</configuration>
(7)最后打开slaves文件,设置有哪些slave节点。
由于我们设置了3份备份,把master即是Name Node又是Data Node,所以我们需要设置三行:
master
slave01
slave02
3.3配置slave01和slave02
在slave01和slave02上做前面3.1 3.2相同的设置。
一模一样的配置,这里不再累述。
4.启动Hadoop
回到Master节点,我们需要先运行
hdfs namenode –format
格式化NameNode。
然后执行
start-all.sh
这里Master会启动自己的服务,同时也会启动slave01和slave02上的对应服务。
启动完毕后我们在master上运行jps看看有哪些进程,这是我运行的结果:
2194 SecondaryNameNode
2021 DataNode
1879 NameNode
3656 Jps
2396 ResourceManager
2541 NodeManager
切换到slave01,运行jps,可以看到如下结果:
1897 NodeManager
2444 Jps
1790 DataNode
切换到slave02也是一样的有这些服务。
那么说明我们的服务网都已经启动成功了。
现在我们在浏览器中访问:
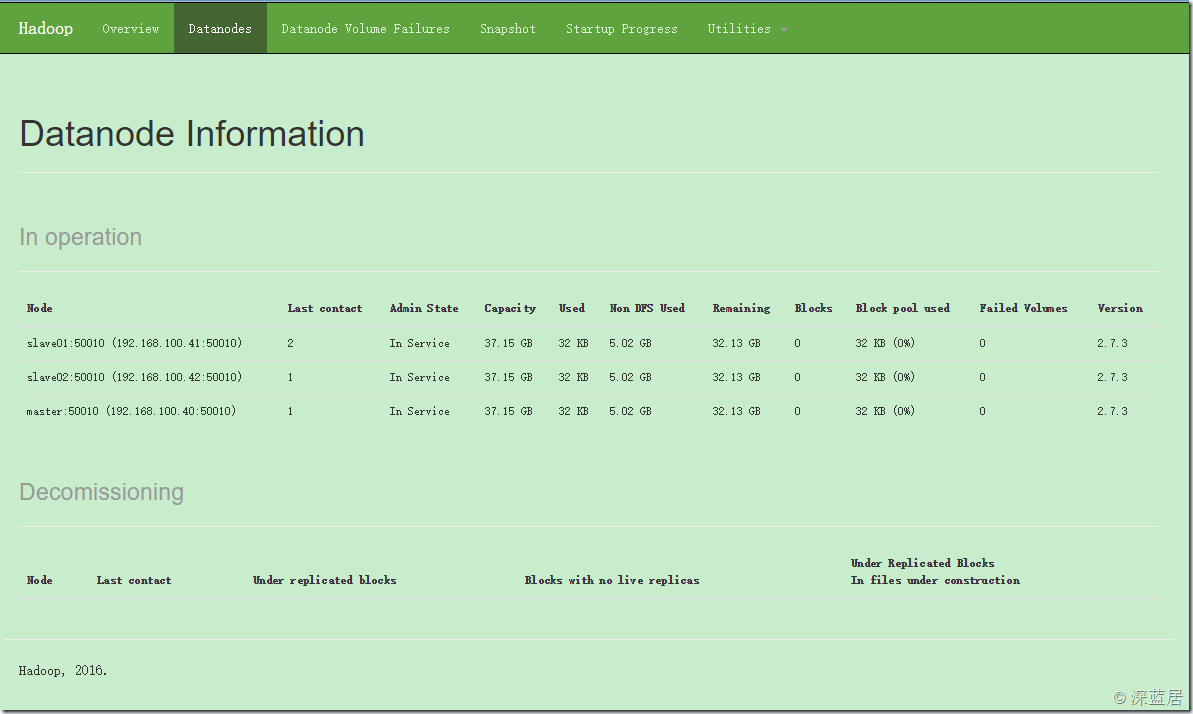
应该可以看到Hadoop服务已经启动,切换到Datanodes可以看到我们启动的3台数据节点:
在Ubuntu上搭建Hadoop群集的更多相关文章
- Ubuntu上搭建Hadoop环境(单机模式+伪分布模式)
首先要了解一下Hadoop的运行模式: 单机模式(standalone) 单机模式是Hadoop的默认模式.当首次解压Hadoop的源码包时,Hadoop无法了解硬件安装环境,便保守地选 ...
- Ubuntu上搭建Hadoop环境(单机模式+伪分布模式) (转载)
Hadoop在处理海量数据分析方面具有独天优势.今天花了在自己的Linux上搭建了伪分布模式,期间经历很多曲折,现在将经验总结如下. 首先,了解Hadoop的三种安装模式: 1. 单机模式. 单机模式 ...
- Ubuntu上搭建Hadoop环境(单机模式+伪分布模式)【转】
[转自:]http://blog.csdn.net/hitwengqi/article/details/8008203 最近一直在自学Hadoop,今天花点时间搭建一个开发环境,并整理成文. 首先要了 ...
- 在 Ubuntu 上搭建 Hadoop 分布式集群 Eclipse 开发环境
一直在忙Android FrameWork,终于闲了一点,利用空余时间研究了一下Hadoop,并且在自己和同事的电脑上搭建了分布式集群,现在更新一下blog,分享自己的成果. 一 .环境 1.操作系统 ...
- Ubuntu上搭建Watir-Webdriver与Cucumber环境
本文主要演示如何在Ubuntu上搭建Watir-Webdriver与Cucumber环境,用于自动化测试. 1. Ubuntu环境 A. 安装 因为我的工作机是Windows,所以采用虚拟机的方式使用 ...
- Ubuntu上搭建Git服务器
下面我们就看看,如何在Ubuntu上搭建Git服务器.我们使用VMware虚拟机安装两台Ubantu系统,分别命名为gitServer和gitClient_01. 1.安装OpenSSH并配置SSH无 ...
- 在ubuntu上搭建交叉编译环境---arm-none-eabi-gcc
最近要开始搞新项目,基于arm的高通方案的项目. 那么,如何在ubuntu上搭建这个编译环境呢? 1.找到相关的安装包:http://download.csdn.net/download/storea ...
- 在Ubuntu上搭建kindle gtk开发环境
某个角度上说,kindle很类似android,同样的Linux内核,同样的Java用户层.不过kindle更注重简单.节能.稳定.Amazon一向认为,功能过多会分散人们阅读时候的注意力. Kind ...
- Ubuntu上搭建GPU服务器
1.安装显卡驱动 2.安装CUDA 3.安装cuDNN 下载: 根据显卡类型以及操作系统,选定CUDA版本和语言设置,下载对应的显卡驱动. 驱动下载地址 安装 $ sudo ./NVIDIA-Linu ...
随机推荐
- SQLServer:什么是主键(PK)和外键(FK)?
一.主键与外键 1.主键是用来唯一地标识一行数据.主键列必须包含唯一的值,且不能包含空值(null). 2.主键可以建立在每张二维表中单列或者多列上. 3.一张二维表上的外键可以引用另一张二维表上对应 ...
- angular2系列教程(四)Attribute directives
今天我们要讲的是ng2的Attribute directives.顾名思义,就是操作dom属性的指令.这算是指令的第二课了,因为上节课的components实质也是指令. 例子
- Handler系列之使用
作为一个Android开发者,我们肯定熟悉并使用过Handler机制.最常用的使用场景是"在子线程更新ui",实际上我们知道上面的说话是错误的.因为Android中只有主线程才能更 ...
- spring帝国-开篇
spring简介: spring是一个开源框架,spring是于2003 年兴起的一个轻量级的Java 开发框架,由Rod Johnson 在其著作Expert One-On-One J2EE Dev ...
- web前端性能调优
最近2个月一直在做手机端和电视端开发,开发的过程遇到过各种坑.弄到快元旦了,终于把上线了.2个月干下来满满的的辛苦,没有那么忙了自己准备把前端的性能调优总结以下,以方便以后自己再次使用到的时候得于得心 ...
- 再谈React.js实现原生js拖拽效果
前几天写的那个拖拽,自己留下的疑问...这次在热心博友的提示下又修正了一些小小的bug,也加了拖拽的边缘检测部分...就再聊聊拖拽吧 一.不要直接操作dom元素 react中使用了虚拟dom的概念,目 ...
- 【Python五篇慢慢弹(5)】类的继承案例解析,python相关知识延伸
类的继承案例解析,python相关知识延伸 作者:白宁超 2016年10月10日22:36:57 摘要:继<快速上手学python>一文之后,笔者又将python官方文档认真学习下.官方给 ...
- 学习SpringMVC——你们要的REST风格的CRUD来了
来来来,让一下,客官,您要的REST清蒸CRUD来了,火候刚刚好,不油不腻,请慢用~~~ 如果说前面是准备调料,洗菜,切菜,摆盘,那么今天就来完整的上道菜,主要说的是基于REST风格实现数据的增删改查 ...
- 原创:去繁存简,回归本源:微信小程序公开课信息分析《一》
以前我开过一些帖子,我们内部也做过一些讨论,我们从张小龙的碎屏图中 ,发现了重要讯息: 1:微信支付将成为重要场景: 2:这些应用与春节关系不小,很多应用在春节时,有重要的场景开启可能性: 3:春节是 ...
- 【分布式】Zookeeper数据与存储
一.前言 前面分析了Zookeeper对请求的处理,本篇博文接着分析Zookeeper中如何对底层数据进行存储,数据存储被分为内存数据存储于磁盘数据存储. 二.数据与存储 2.1 内存数据 Zooke ...