scrapy中css选择器初识
由于最近做图片爬取项目,涉及到网页中图片信息的选择,所以边做边学了点皮毛,有自己的心得
百度图库是ajax加载的,所以解析json数据即可
hjsons = json.loads(response.body)
img_datas = hjsons['data']
if hjsons:
for data in img_datas:
try:
item = Bd_Item()
#print(data['fromPageTitleEnc'])
#print(data['thumbURL'])
item['img_url'] = data['thumbURL']
item['img_title'] = data['fromPageTitleEnc']
item['width'] = data['width']
item['height'] = data['height']
yield item
except:
pass
千图网抠图是分页加载
http://588ku.com/sucai/0-default-0-0-yueliang-0-1/
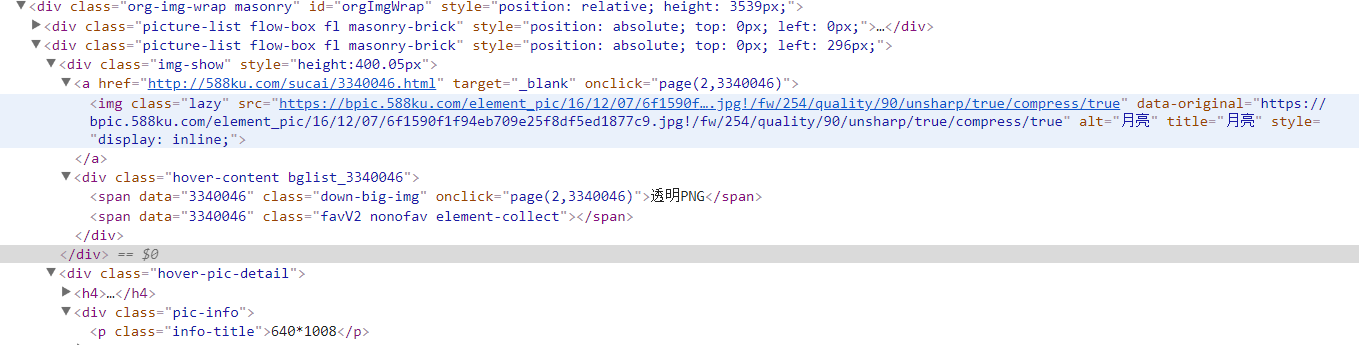
qt_imgs = response.css('.org-img-wrap .picture-list')
for qt_img in qt_imgs:
try:
item = Qt_Item()
img_url = qt_img.css('.img-show .lazy::attr(data-original)').extract_first()
title = qt_img.css('.img-show .lazy::attr(title)').extract_first()
size = qt_img.css('.hover-pic-detail .pic-info .info-title::text').extract_first()
#width = re.findall(r'(.*?)\*',size).extract_first()
#height = re.findall(r'\*(.*?)', size).extract_first()
#print(width)
#print(height)
#time.sleep(10)
item['qtimg_url'] = img_url
item['qtimg_title'] = title
item['size'] = size
#item['width'] = width
#item['height'] = height
yield item
except:
pass
觅元素和千图网差不多,但是选取图片链接有技巧,千图网图片可以看到有两个图片链接,其中data-original这个链接不同处理即可,但是如果选src会发现,选取出来的链接都是一样的,而且当你打开链接时发现黑色一片,我感觉这是种保护吧,但只有这一种链接该怎么办呢,于是我用正则去选择,结果发现,抓取结果中有两条链接,而第一条是无用的,第二条才是有用的,它的名字是data-src,这就好办了,只需要把src改成data-src即可成功选取。

mys_imgs = response.css('.content-wrap .w1200 .f-content .i-flow-item')
for mys_img in mys_imgs:
try:
item = Mys_Item()
img_url = mys_img.css('.img-out-wrap .img-wrap img::attr(data-src)').extract_first()
title = mys_img.css('.img-out-wrap .img-wrap img::attr(alt)').extract_first()
size = mys_img.css('.i-title-wrap a::text').extract_first()
size_detail = re.findall(r'\((.*?)\)',size)
#text = mys_img.css('.img-wrap .lazy').extract_first()
# time.sleep(10)
#img_url = re.findall(r'src="(.*?)!/fw/260/quality/90/unsharp/true/compress/true"', text)
#width = re.findall(r'(.*?)x', size_detail).extract_first()
#height = re.findall(r'x(.*?)', size_detail).extract_first()
item['mysimg_url'] = img_url
item['mysimg_title'] = title
item['size'] = size_detail
#item['width'] = width
#item['height'] = height
yield item
except:
pass
这东西有点意思,需要琢磨,以后用到再慢慢学吧
scrapy中css选择器初识的更多相关文章
- 使用scrapy中xpath选择器的一个坑点
情景如下: 一个网页下有一个ul,这个ur下有125个li标签,每个li标签下有我们想要的 url 字段(每个 url 是唯一的)和 price 字段,我们现在要访问每个li下的url并在生成的请求中 ...
- 爬虫学习笔记(2)--创建scrapy项目&&css选择器
一.手动创建scrapy项目---------------- 安装scrapy: pip install -i https://pypi.douban.com/simple/ scrapy 1 ...
- 爬虫(十一):scrapy中的选择器
Scrapy提取数据有自己的一套机制,被称作选择器(selectors),通过特定的Xpath或者CSS表达式来选择HTML文件的某个部分Xpath是专门在XML文件中选择节点的语言,也可以用在HTM ...
- selenium中CSS选择器定位
selenium元素定位,CSS选择器定位效率会高很多. CSS选择器用于选择你想要的元素的样式的模式.表格摘自“菜鸟教程”,具体用法可去查阅 选择器 示例 示例说明 CSS .class .intr ...
- Scrapy的中Css 选择器
//通过 名为 video_part_lists 的Class 中下面的 li 标签 liList = response.css('.video_part_lists li') for li in l ...
- Scrapy基础------css选择器基础
基本语法: * 选择所有节点 #container 选择id为container的节点 .container 选择所有class包含container的节点 li a 选取所有li 下所有a节点 ul ...
- 第 13 章 CSS 选择器[上]
学习要点: 1.选择器总汇 2.基本选择器 3.复合选择器 4.伪元素选择器 主讲教师:李炎恢 本章主要探讨 HTML5 中 CSS 选择器,通过选择器定位到想要设置样式的元素.目前 CSS 选择器的 ...
- 第七十节,css选择器
css选择器 学习要点: 1.选择器总汇 2.基本选择器 3.复合选择器 4.伪元素选择器 本章主要探讨 HTML5中 CSS选择器,通过选择器定位到想要设置样式的元素.目前CSS选择器的版本已经升 ...
- 初始scrapy,简单项目创建和CSS选择器,xpath选择器(1)
一 安装 #Linux: pip3 install scrapy #Windows: a. pip3 install wheel b. 下载twisted http://www.lfd.uci.edu ...
随机推荐
- todo项目总结
vue+webpack项目工程配置 1.vue-loader+webpack项目配置 2.webpack配置项目加载各种静态资源 3.webpack-dev-server的配置和使用 安装: pack ...
- 一、使用Navicat连接阿里云服务器宝塔面板里创建的数据库
一.数据库配置连接 (通过新增用户的方式)
- python代码块,小数据池,驻留机制深入剖析
一,什么是代码块. 根据官网提示我们可以获知: 根据提示我们从官方文档找到了这样的说法: A Python program is constructed from code blocks. A blo ...
- [Codeforces741D]Arpa's letter-marked tree and Mehrdad's Dokhtar-kosh paths——dsu on tree
题目链接: Codeforces741D 题目大意:给出一棵树,根为$1$,每条边有一个$a-v$的小写字母,求每个点子树中的一条最长的简单路径使得这条路径上的边上的字母重排后是一个回文串. 显然如果 ...
- mpvue——Error: EPERM: operation not permitted
报错 $ npm run build > mpvue@ build D:\wamp\www\webpack\mpvue\my-project > node build/build.js w ...
- codechef EBAIT Election Bait【欧几里得算法】
题目分析: 欧几里得算法来处理一类分数问题,分数问题的形式如下 $\frac{a}{b} < \frac{p}{q} < \frac{c}{d}$ 当a=0时,答案等于$\frac{1}{ ...
- IDEA如何查看maven的依赖结构
打开方式: 方法一:该工具有个Maven Projects窗口,一般在右侧能够找到,如果没有可以从菜单栏打开:View>Tool Windows>Maven Projects:选择要分析的 ...
- 栈长这里是生成了一个 Maven 示例项目。
Spring Cloud 的注册中心可以由 Eureka.Consul.Zookeeper.ETCD 等来实现,这里推荐使用 Spring Cloud Eureka 来实现注册中心,它基于 Netfl ...
- 自学华为IoT物联网_02 常见物联网通信技术
点击返回自学华为IoT物流网 自学华为IoT物联网_02 常见物联网通信技术 两类技术: 有线通信技术 无线通信技术 一. 有线通信技术 1.1 物联网有线技术介绍及对比 ETH 主要用于支持以太网标 ...
- 【BZOJ5316】[JSOI2018]绝地反击(网络流,计算几何,二分)
[BZOJ5316][JSOI2018]绝地反击(网络流,计算几何,二分) 题面 BZOJ 洛谷 题解 很明显需要二分一个答案. 那么每个点可以确定的范围就是以当前点为圆心,二分出来的答案为半径画一个 ...