爬虫学习笔记(2)--创建scrapy项目&&css选择器
一、手动创建scrapy项目
----------------
安装scrapy:
pip install -i https://pypi.douban.com/simple/ scrapy
1、创建项目
(article_spider) E:\PyCharmWorkspace>scrapy startproject ArticleSpider(项目名称)
此时只是利用现有模板创建了scrapy项目,但是没有spider
2、pycharm导入项目
1、open
2、配置解释器
file->setting->project interpreater-选择你创建的虚拟环境下script-python.exe
3、创建spider
1)进入项目目录下
(article_spider) E:\PyCharmWorkspace>cd ArticleSpider
2)创建spider
(article_spider)E:\PyCharmWorkspace\ArticleSpider>scrapy genspider jobbole(spider的名字) blog.jobbole.com(域名)
idea中spider目录下就会出现对应的py文件
4、为了可以调试scrapy,创建main文件
以后想debug的时候,直接debug该main文件即可。原理是在scrapy中调用spider(命令是scrapy crawl jobbole)
from scrapy.cmdline import execute
import sys
import os
#os.path.abspath(__file__)获取当前py文件的路径
#os.path.dirname(),获得参数文件所在文件夹的路径,即父目录
#__file__指当前py文件
print (os.path.abspath(__file__))
#在工程目录os.path.dirname(os.path.abspath(__file__))下执行命令行才有效
sys.path.append(os.path.dirname(os.path.abspath(__file__)))
#scrapy中启动spider项目:在命令行用scrapy crawl jobbole命令
execute(["scrapy","crawl","jobbole"])
5】、cmd执行spider命令
命令:scrapy crawl jobbole
错误:ImportError: No module named 'win32api'
解决:pip install -i https://pypi.douban.com/simple pypiwin32
6、修改seeting.py(必须改)
ROBOTSTXT_OBEY = False 将true改为false
若为true会自动过滤掉不符合ROBOTS规则的url
7】、
在jobbole.py中:
执行完spider(scrapy crawl jobbole)后会有如下操作:
下载start_urls = ['http://blog.jobbole.com/']该url的页面,返回一个response
def parse(self, response):
二、基础知识
----------
0、
scrapy获得的是右击页面->查看页面源代码
右击页面->检查,的代码是运行完js之后的,并不是scrapy要爬取的
1、css选择器
----------
* 选择所有节点
#container 选择id为container的节点
.container 选择所有class包含container的节点
li a 选取所有li下的所有a节点
ul + p 选择ul后面的第一个p元素(互为兄弟节点)
div#container > ul 选取id为container的div的第一个ul子元素
2、技巧
--------
1)如何快速得到css地址
chrome 右击你要定位的元素,选择copy->copy selector 即可
2)
每次启动scrapy都比较慢,每调试一次都需要启动scrapy. shell脚本调试
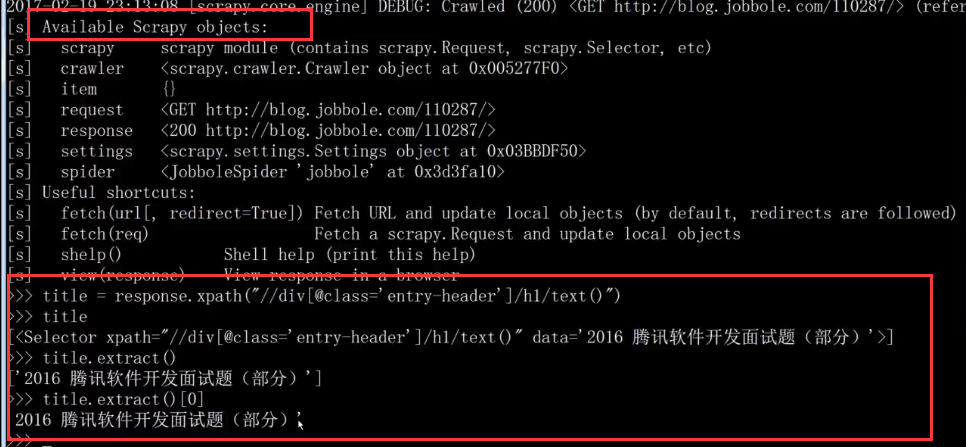
在虚拟环境下,cmd命令,执行scrapy shell http://blog.jobbole.com/112569/(对这个url进行调试),response可以调用:
3)
.strip():去除左右两边的空字符

爬虫学习笔记(2)--创建scrapy项目&&css选择器的更多相关文章
- springmvc学习笔记---idea创建springmvc项目
前言: 真的是很久没搞java的web服务开发了, 最近一次搞还是读研的时候, 想来感慨万千. 英雄没落, Eclipse的盟主地位隐隐然有被IntelliJ IDEA超越的趋势. Spring从2. ...
- yii学习笔记--快速创建一个项目
下载yii框架 下载地址:http://www.yiiframework.com/ 中文网站:http://www.yiichina.com/ 解压文件
- web前端学习(三)css学习笔记部分(4)-- CSS选择器详解
4. 元素选择器详解 4.1 元素选择器 4.2 选择器分组 用英文逗号","相连,使用相同的样式表 使用通配符对所有元素进行通用设定. 4.3 类选择器详解 4.3.1. ...
- scrapy爬虫学习系列二:scrapy简单爬虫样例学习
系列文章列表: scrapy爬虫学习系列一:scrapy爬虫环境的准备: http://www.cnblogs.com/zhaojiedi1992/p/zhaojiedi_python_00 ...
- pycharm创建scrapy项目教程及遇到的坑
最近学习scrapy爬虫框架,在使用pycharm安装scrapy类库及创建scrapy项目时花费了好长的时间,遇到各种坑,根据网上的各种教程,花费了一晚上的时间,终于成功,其中也踩了一些坑,现在整理 ...
- scrapy爬虫学习系列三:scrapy部署到scrapyhub上
系列文章列表: scrapy爬虫学习系列一:scrapy爬虫环境的准备: http://www.cnblogs.com/zhaojiedi1992/p/zhaojiedi_python_00 ...
- python网络爬虫学习笔记
python网络爬虫学习笔记 By 钟桓 9月 4 2014 更新日期:9月 4 2014 文章文件夹 1. 介绍: 2. 从简单语句中開始: 3. 传送数据给server 4. HTTP头-描写叙述 ...
- Django:学习笔记(2)——创建第一个应用
Django:学习笔记(2)——创建第一个应用 创建应用 在 Django 中,每一个应用都是一个 Python 包,并且遵循着相同的约定.Django 自带一个工具,可以帮你生成应用的基础目录结构, ...
- Java学习笔记-多线程-创建线程的方式
创建线程 创建线程的方式: 继承java.lang.Thread 实现java.lang.Runnable接口 所有的线程对象都是Thead及其子类的实例 每个线程完成一定的任务,其实就是一段顺序执行 ...
随机推荐
- int 与 string::length()
今天在代码中遇到这样的问题 ; while (nStart < strTemp.length()) { ... } 感觉自己写的逻辑没有错误,但是,代码执行结果就是不对,结果单步调试到该处发现, ...
- Java 十进制和十六制之间的转化(负数的处理)
原文: http://www.cnblogs.com/literoad/archive/2013/01/25/2875908.html 在一些情况下,我们需要将数字在十进制和十六制下互相转化. 在Ja ...
- java中的static方法和实例方法区别
1.static方法是大家共享的资源,放在内存堆中,比如村里的河水,每个人都可以取,而且不管你创建多少个实例,该方法在内存中只有一个,节省内存空间, 而且访问速度也是比较快的. 2.实例方法就不同,它 ...
- App上架注意事项(转)
上传不出现构建版本 现在苹果要求先上传版本,然后在提交审核,但是现在经常上传完应用后,不出现构建版本,等待很久很久,也不出现,那么怎么解决,我告诉你~~尼玛的苹果是自己数据丢包了,结果就造成你不出现构 ...
- Android Studio 使用笔记: 重命名和重构
重命名 选中一个变量名称,菜单才是可用状态.然后可以根据系统给出的建议或者自己重新定义变量名称. 快捷键:Shift + F6 (Windows和Mac都是一样的) 重构 选中需要重构的代码,可以按照 ...
- Vim使用技巧(4) -- 命令行模式 【持续更新】
基本保存,退出,帮助 :help //帮助 :w //保存 :q //退出 :wq //保存后退出 :q! //强制不保存退出 %s/a/b/g //将当前文件的a全部替换成b /abc //正向查找 ...
- Spell checker - poj 1035 (hash)
Time Limit: 2000MS Memory Limit: 65536K Total Submissions: 22541 Accepted: 8220 Description Yo ...
- 我的第7个java程序--把java web项目改为java project项目--mybatis
连接数据库需要 程序,连接字符串,查询语句 主程序->读取连接字符串->读取查询语句->把查询到的值赋值给映射对象->打印对象属性 java project的好处,不用做那么多 ...
- 我的第五个程序 java的JDBC连接mysql数据库 实现输入查询
import java.sql.*; import java.util.Scanner; public class JDBCTest { public static void main(String[ ...
- java.lang.IllegalArgumentException: column '_id' does not exist问题的解决方案
我在使用SimpleCursorAdapter的过程中遇到了问题: java.lang.IllegalArgumentException: column '_id' does not exist 这个 ...