Feature Extractor[DenseNet]
0.背景
随着CNN变得越来越深,人们发现会有梯度消失的现象。这个问题主要是单路径的信息和梯度的传播,其中的激活函数都是非线性的,从而特别是乘法就可以使得随着层数越深,假设将传统的神经网络的每一层看成是自动机中的一个状态。那么对于整个神经网络来说,输入到输出就是一个输入态不断的转移到输出态的一个过程。假设其中每一层都是有个变率,即缩放因子。那么:
- 变率大于1,层数越多,越呈现倍数放大趋势,比如爆炸;
- 变率小于1,层数越多,越呈现倍数缩小趋势,比如消失;
而传统以往的卷积神经网络都是单路径的,即从输入到输出只能走一条路,所以人们发现了可以通过扩展信息的传输路径和形式,如:
- inception系列从模块入手,基于每个模块建立多个不同的通道,然后将模块进行连接,不过从模型整体角度上看也是一本道;
- ResNet系列通过快捷连接的方式将不同层的输出直接连接到后面层的输入,算是让信息的传播通道有了分支,不完全直接走非线性的卷积和池化等权重层,让信息的传播路径有了选择。
正是发现可以从网络结构入手,让信息的传输路径不再单一。假如我们认为传统的神经网络的输入到输出是单路径形式,那么通过添加分支路径使得某些层能够比传统模型有更多更短的路径可以选择,这样较好的解决了唯一路径的"瓶颈问题"(信息只有一条路可走),从而通过网络训练,信息能够自适应的走网络的多个路径。不过近期很多的论文,如ResNet和Highway Network等都是通过恒等连接将某层的输出信息传递到后面其他层,且而《Deep networks with stochastic depth》在Resnet网络结构上发现其实很多层的信息是冗余的,通过在训练过程中随机丢弃某些层可以得到更好的信息和梯度流。
DenseNet由此出发,建立了更复杂的多通道模型,如图0.1所示,输入层可以快捷连接到输出层:
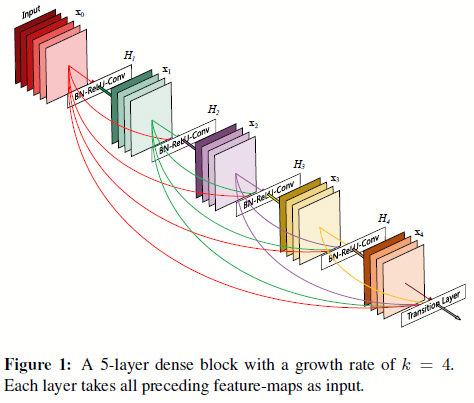
图0.1 Densenet的模块结构
如图0.1,这就是Densenet的模块结构。作者认为好处有:
- 缓和了梯度消失的问题(多路径带来的好处);
- 增强了特征传播(多路径带来的好处);
- 特征能够多次重用,从而减少冗余特征的学习;
- 模型参数量能够很大程度上的减少;
- 模型具有正则效果(在很小的数据集上减少过拟合)
如图0.1所示,Densenet在将特征连入后面的层之前,不对其做任何操作,只是将其以通道的维度进行合并(如第\(l\)层有\(l\)个通道输入,那么结合之前所有的卷积层,这时候的通道数变成了\(l(l+1)/2\)).
值得注意的是,通过实验发现,这样一个相对更密集的网络结构,所需要的参数量反而更少,这归功于densenet不需要去保留那些冗余的feature map。
1. DenseNet
基于上述自动机的角度,传统的前向网络结构可以认为是:当前层从前一层获取状态,然后加以处理,并将新的状态输出到下一层。这其中就会发现有些信息其实是需要保留到当前层的,结果也传递到后面去了,造成了冗余。接着从自动机角度出发,Resnet也可以看成是一个“相似的铺展开的RNN网络结构”(通过恒等连接实现循环),不过不同于RNN的就是resnet的参数量因为每一层都是有各自的参数,所以相比RNN的参数量要大很多。
为了防止参数量过大,且主要是基于特征重用。densenet设计的时候是让每一层的通道数量很小(一层12个通道),且如0.1图所示,后续每一层都能直接获取前面所有层的特征,最后的分类器可以基于所有的feature map进行做决策,这样让特定层的特征能够一直重用,从而减少网络的冗余特征学习。
用数学形式来说明ResNet与Densenet的差别如下:
- ResNet: \(x_l = H_l(x_{l-1})+x_{l-1}\)
- DenseNet: \(x_l = H_l([x_0,x_1,...,x_{l-1}])\)
其中\([x_0,x_1,...,x_{l-1}]\)就是将之前的feature map以通道的维度进行合并,且受到ResNet v2的影响,其中的\(H_l(\dot)\)也是三层网络:BN、ReLU、卷积。
如上面所述,在进行feature map合并的时候,是没法处理feature map的size不同的情况的,可是CNN是必须要有map的size的减小的,也就是池化还是需要的,不然输出层会参数量过多了。所以作者通过图1.1形式来解决这个问题。
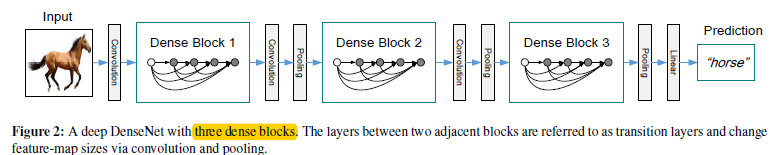
图1.1 将图0.1结构作为densenet的块来构建整个网络
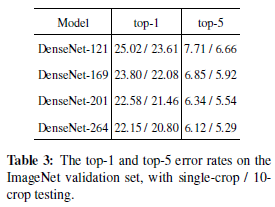
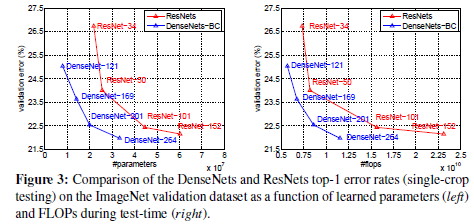
图1.2 基于imagenet上的实验结果
如图1.1。通过将图0.1的结构作为一个构建块,从而在不同的构建块之间建立转换层,从而解决feature map需要变化的问题(其中连接层由:BN层,\(1*1\)卷积层,\(2*2\)池化层构成,其中BN未画出来)(那么,这样是不是说在池化部分,就有瓶颈存在了呢?)
1.1 增长参数k
对于图0.1来说,假定每一层的feature maps的个数为k,则第\(l\)层的输入map个数为\(k_0+k*(l-1)\),即收集之前每层输出的feature maps,然后基于通道维度进行合并,以此作为当前层的输入feature maps。那么k值的大小就能控制网络的复杂度了,作者将该变量称为网络的"growth rate"
1.2 DenseNet-B
对于DenseNet-B来说,就是将之前densenet的构建块中的BN-ReLU-(\(3*3\)卷积)变成BN-ReLU-(\(1*1\)卷积),并且对于其中的(\(1*1\)卷积),输出的feature maps的通道数为4k个
1.3 DenseNet-C
对于Densenet-C来说,就是在转换层下功夫了,如图1.1中的两个Dense block中间的部分,如果上一个Dense block输出了m个feature maps(即将之前所有的feature map都连接到这个转换层),那么设定一个缩放因子\(\theta\),如果\(0<\theta<1\),那么就达到了网络通道上的降维,使得模型更紧凑,实验中该值设为0.5。
2 实现过程
- 1 - 作者在imagenet数据集上用个4个dense block,结构如下图
图2.1 k等于32基础上,不同层数densenet网络的结构

2 - 在其他数据集上是用了三个dense block(每个block中层数相同),转换层是\(1*1\)的卷积加上\(2*2\)的平均池化,在最后一个dense block后面跟上一个全局平均池化,然后是一个softmax。
其中三个dense block中feature map的大小分别是\(32*32\),\(16*16\),\(8*8\),且有三个不同的参数组合:
- 对于简单的densenet来说有(L=40,k=12)、(L=100,k=12)、(L=100,k=24);
- 对于densenet-BC来说有(L=100,k=12)、(L=250,k=24)、(L=190,k=40)

图2.2 其他数据集下的实验对比
Feature Extractor[DenseNet]的更多相关文章
- Feature Extractor[SENet]
0.背景 这个模型是<Deep Learning高质量>群里的牛津大神Weidi Xie在介绍他们的VGG face2时候,看到对应的论文<VGGFace2: A dataset f ...
- Feature Extractor[content]
0. AlexNet 1. VGG VGG网络相对来说,结构简单,通俗易懂,作者通过分析2013年imagenet的比赛的最好模型,并发现感受野还是小的好,然后再加上<network in ne ...
- Feature Extractor[VGG]
0. 背景 Karen Simonyan等人在2014年参加Imagenet挑战赛的时候提出的深度卷积神经网络.作者通过对2013年的ILSVRC中最好的深度神经网络模型(他们最初的对应模型都是ale ...
- Feature Extractor[inception v2 v3]
0 - 背景 在经过了inception v1的基础上,google的人员还是觉得有维度约间的空间,在<Rethinking the Inception Architecture for Com ...
- Feature Extractor[ResNet]
0. 背景 众所周知,深度学习,要的就是深度,VGG主要的工作贡献就是基于小卷积核的基础上,去探寻网络深度对结果的影响.而何恺明大神等人发现,不是随着网络深度增加,效果就好的,他们发现了一个违背直觉的 ...
- 图像金字塔(pyramid)与 SIFT 图像特征提取(feature extractor)
David Lowe(SIFT 的提出者) 0. 图像金字塔变换(matlab) matlab 对图像金字塔变换接口的支持(impyramid),十分简单好用. 其支持在reduce和expand两种 ...
- Feature Extractor[googlenet v1]
1 - V1 google团队在模型上,更多考虑的是实用性,也就是如何能让强大的深度学习模型能够用在嵌入式或者移动设备上.传统的想增强模型的方法无非就是深度和宽度,而如果简单的增加深度和宽度,那么带来 ...
- Feature Extractor[batch normalization]
1 - 背景 摘要:因为随着前面层的参数的改变会导致后面层得到的输入数据的分布也会不断地改变,从而训练dnn变得麻烦.那么通过降低学习率和小心地参数初始化又会减慢训练过程,而且会使得具有饱和非线性模型 ...
- Feature Extractor[Inception v4]
0. 背景 随着何凯明等人提出的ResNet v1,google这边坐不住了,他们基于inception v3的基础上,引入了残差结构,提出了inception-resnet-v1和inception ...
随机推荐
- Win7怎么录制电脑屏幕视频
我们在看视频的时候,经常会看到自己特别喜爱的视频,想要把其中的某些片段给录制下来,那么Win7怎么录制电脑屏幕视频?其实步骤很简单,下面就来分享下具体的步骤. 使用工具: 电脑 操作方法: 第一步.首 ...
- Ne10编译安装
介绍 NEON,即"ARM Advanced SIMD",是ARM从ARMv7开始提供的高级单指令多数据(SIMD)扩展.它是一种64/128位混合SIMD体系结构.NEON在网上 ...
- (后端)springboot 在idea中实现热部署(转)
自己用到了iIntelliJ IDEA 这个ide工具,但是和以前的工具写html,css,js直接刷新页面不同,这个需要去热部署,网上搜的解决方法: SpringBoot的web项目,在每一次修改了 ...
- Keras实现VGG16
一.代码实现 # -*- coding: utf-8 -*- """ Created on Sat Feb 9 15:33:39 2019 @author: zhen & ...
- SQL Server将一列的多行内容拼接成一行
昨天遇到一个SQL Server的问题:需要写一个储存过程来处理几个表中的数据,最后问题出在我想将一个表的一个列的多行内容拼接成一行 比如表中有两列数据 : ep_classes ep_name A ...
- win7 中 sql server2005 卸载简介
注:卸载前一定要做好备份,一定要清理干净,不然重装会出错(只针对完全卸载,没试过只删除一个版本的) 工具:①Windows Install Clean Up ②SrvInstw.exe 1.停止所有 ...
- Windows 在命令行中将输出内容放到文件中
1.将命令行中输出的内容存储到文件中. 使用重定向符号 “>” 就可以了. 通过 > 可以创建新文件并将内容放到文件中,如果文件存在,则会覆盖. 2.通过 >> 可以向已有的文 ...
- vmWare 虚机文件不能启动的事故处理
由于公司停电,导致几十台vmWare虚拟机器启动报错. 错误:Failed to power on virtual machine XXX. Failed to lock the file Click ...
- 【爬坑】远程连接 MySQL 失败
问题描述 远程连接 MySQL 服务器失败 报以下错误 host 192.168.23.1 is not allowed to connect to mysql server 解决方案 在服务器端打开 ...
- AI学习---特征工程【特征抽取、特征预处理、特征降维】
学习框架 特征工程(Feature Engineering) 数据和特征决定了机器学习的上限,而模型和算法只是逼近这个上限而已 什么是特征工程: 帮助我们使得算法性能更好发挥性能而已 sklearn主 ...