pandas数据清洗策略2
首先,我们先要读入数据:
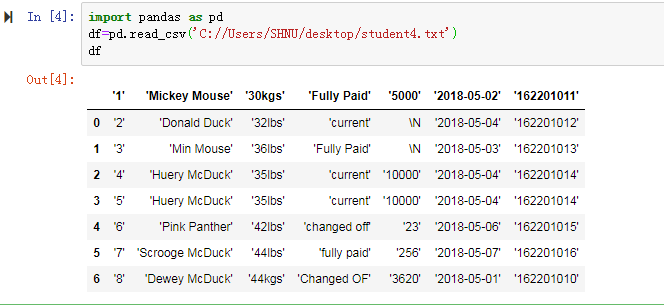
然后检查数据出现的问题:
1.没有表头,增加表头
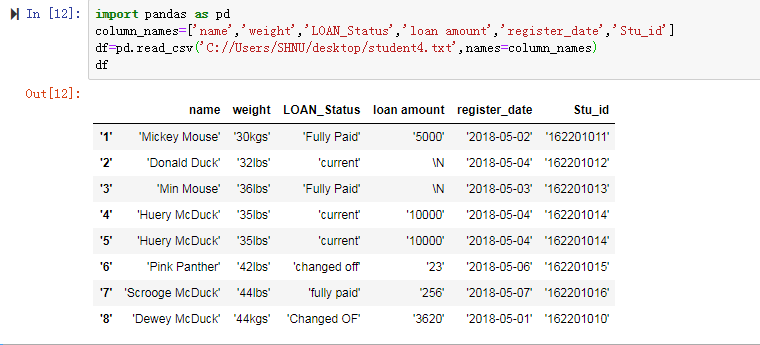
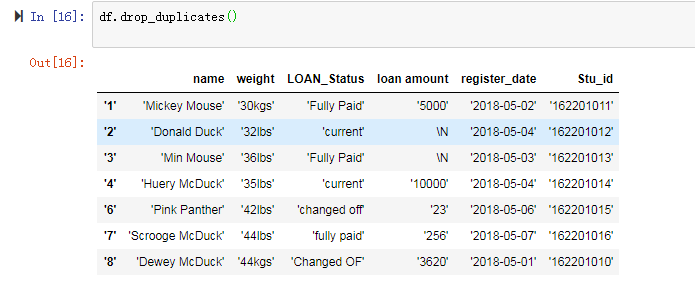
2.去除重复值:
df.duplicate()使用布尔数据查看数据表中是否有重复值,df.drop_duplicates(),删去重复的值
这里有两点需要说明:第一,数据表中两个条目间所有列的内容都相等时duplicated才会判断为重复值。(Duplicated也可以单独对某一列进行重复值判断)。第二,duplicated支持从前向后(first),
和从后向前(last)两种重复值查找模式。默认是从前向后进行重复值的查找和判断。换句话说就是将后出现的相同条件判断为重复值。

df.drop_duplicates(),删去重复的值
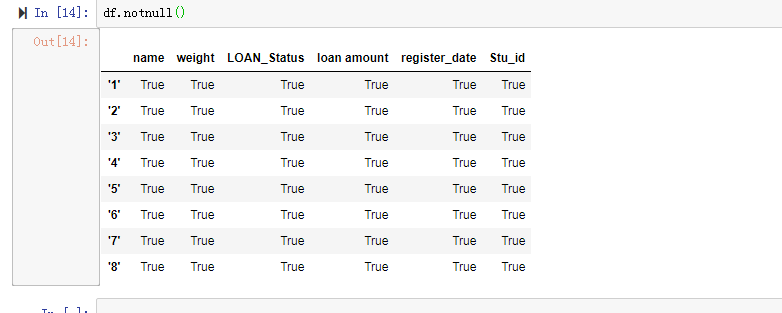
Pandas中查找数据表中空值的函数有两个,一个是函数isnull,如果是空值就显示True。另一个函数notnull正好相反,如果是空值就显示False。
以下两个函数的使用方法以及通过isnull函数获得的空值数量。

对于空值有两种处理的方法,第一种是使用fillna函数对空值进行填充,可以选择填充0值或者其他任意值。第二种方法是使用dropna函数直接将包含空值的数据删除。
df.fillna(0), df.dropna()
还有一种经常的用法是使用平均值代替,比如假设loan amount列中与空值,我们可以采用平均值代表空值
df['loan amount']=df['loan amount'].fillna(df['loan amount'].mean())
接下来换索引:
用法是df.set_index('column')
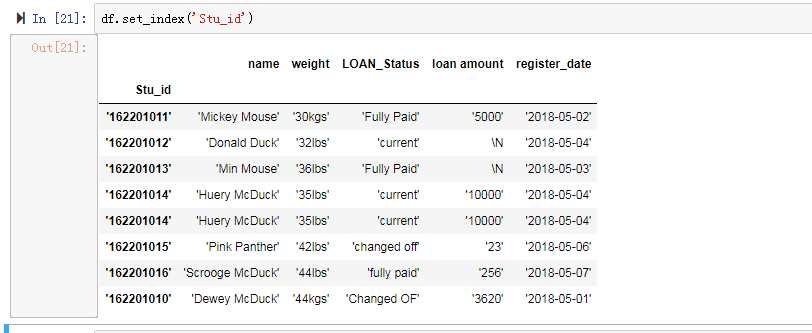
数据间的空格:
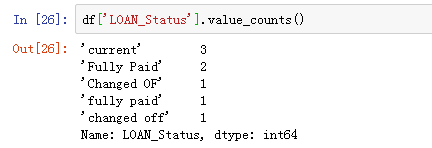
空格会影响我们后续会数据的统计和计算。从下面的结果中就可以看出空格对于常规的数据统计造成的影响。
df['LOAN_Status'].value_counts()
Python中去除空格的方法有三种,第一种是去除数据两边的空格,第二种是单独去除左边的空格,第三种是单独去除右边的空格。
df['LOAN_Status']=df['LOAN_Status'].map(str.strip)#删除左右俩边的空格
df['LOAN_Status']=df['LOAN_Status'].map(str.lstrip)#删除左边空格
df['LOAN_Status']=df['LOAN_Status'].map(str.rstrip)#删除右边空格
大小写转换
大小写转换的方法也有三种可以选择,分别为全部转换为大写,全部转换为小写,和转换为首字母大写。
df['LOAN_Status']=df['LOAN_Status'].map(str.upper)#全部大写
df['LOAN_Status']=df['LOAN_Status'].map(str.lower)#全部小写
df['LOAN_Status']=df['LOAN_Status'].map(str.title)#首字母写
最后我们还需要对数据表中关键字段的内容进行检查,确保关键字段中内容的统一。主要包括数据是否全部为字符,字母或数字。
df['weight'].apply(lambda x:
x.isalpha())#检查该列是否全部为字符
df['weight'].apply(lambda x:
x.isalnum())#检查该列是否全部为数字
df['weight'].apply(lambda x:
x.isalpha())#检查该列是否全部为字母
第一步是更改和规范数据格式,所使用的函数是astype。下面是更改数据格式的代码:
df['loan amount']=df['loan amount'].astype(np.int64)#数据格式处理
df['register_date']=pd.to_datetime(df['register_date'])#日期格式的数据需要使用to_datatime函数进行处理
数据中的异常和极端值
用describe函数可以生成描述统计结果。其中我们主要关注最大值(max)和最小值(min)情况。
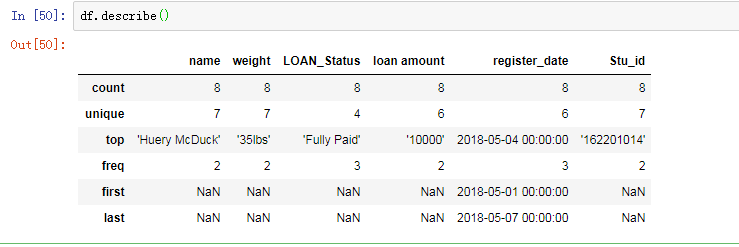
使用平均值代替,公式:
df.replace([23],df['loan amount'].mean())
数据分组
把weight数据进行分组
bins=[30,35,40,45]
group_names=['A','B','C','D']
df['categories']= pd.cut(df['weight'],bins, labels=group_names)
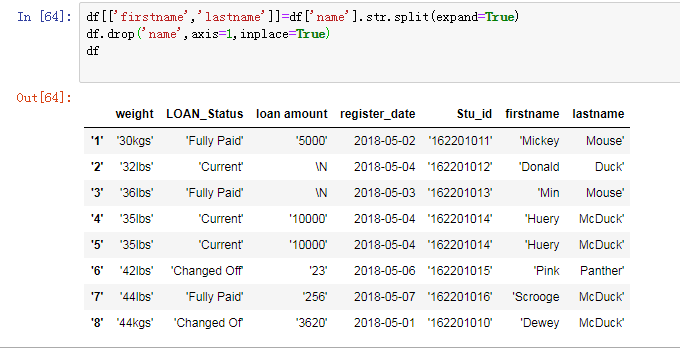
数据分列
pandas数据清洗策略2的更多相关文章
- pandas数据清洗策略1
Pandas常用的数据清洗5大策略如下: 1.删除 DataFrame 中的不必要 columns 2.改变 DataFrame 的 index 3.使用 .str() 方法来清洗 columns 4 ...
- 2.pandas数据清洗
pandas是用于数据清洗的库,安装配置pandas需要配置许多依赖的库,而且安装十分麻烦. 解决方法:可以用Anaconda为开发环境,Anaconda内置了许多有关数据清洗和算法的库. 1.安装p ...
- Python | Pandas数据清洗与画图
准备数据 2016年北京PM2.5数据集 数据源说明:美国驻华使馆的空气质量检测数据 数据清洗 1. 导入包 import numpy as np import matplotlib.pyplot a ...
- Pandas 数据清洗常用篇
一.缺失值 sklearn中的preprocessing下有imputer,可进官方文档参考.这里主讲pandas. 拿到数据,一般先检查是否有缺失值,用isnul()或notnull(). 再决定d ...
- pandas数据清洗
1.我已安装好Anavonda3.5.所以我只用打开"jupyter notebook",然后打开浏览器 然后点击右侧的“new",然后打开python3
- 数据清洗记录,pandas
pandas数据清洗:http://www.it165.net/pro/html/201405/14269.html data=pd.Series([1,2,3,4]) data.replace([1 ...
- Pandas模块
前言: 最近公司有数据分析的任务,如果使用Python做数据分析,那么对Pandas模块的学习是必不可少的: 本篇文章基于Pandas 0.20.0版本 话不多说社会你根哥!开干! pip insta ...
- Python数据处理常用工具(pandas)
目录 数据清洗的常用工具--Pandas 数据清洗的常用工具 Pandas常用数据结构series和方法 Pandas常用数据结构dataframe和方法 常用方法 数据清洗的常用工具--Pandas ...
- Python 3爬虫、数据清洗与可视化实战PDF高清完整版免费下载|百度云盘
百度云盘:Python 3爬虫.数据清洗与可视化实战PDF高清完整版免费下载 提取码: 内容简介 <Python 3爬虫.数据清洗与可视化实战>是一本通过实战教初学者学习采集数据.清洗和组 ...
随机推荐
- python连接sqlserver数据库
1.准备工作 python3.6连接sqlserver数据库需要引入pymssql模块 pymssql官方:https://pypi.org/project/pymssql/ 没有安装的话需要: pi ...
- SQLServer图数据库一些优点
上一篇简要介绍了图数据库的一些基本内容(初识SQL Server2017 图数据库(一)),本篇通过对比关系型一些语法来体现图数据库模式的一些优点,比如查询方便,语句易理解等. 在图数据库模型上构建查 ...
- innodb二阶段日志提交机制和组提交解析
前些天在查看关于innodb_flush_log_at_trx_commit的官网解释时产生了一些疑问,关于innodb_flush_log_at_trx_commit参数的详细解释参见官网: htt ...
- 便捷的方式在手机上查看Unity3D的Console Log(调试信息 日志)
Logs Viewer 功能描述 Using this tool you can easily check your editor console logs inside the game itsel ...
- stored information about method csdn
Eclipse编译时保留方法的形参 Window -> Preferences -> Java -> Compiler. 选中Store information about meth ...
- 设置Firefox自动清除缓存,无需手动清除
1.在firefox的地址栏上输入about:config回车 2.找到browser.cache.check_doc_frequency选项,双击将3改成1保存即可. 那么这个选项每个值都是什么含义 ...
- adb install与pm install 区别
“adb install xx.apk”= “adb push xx.apk /data/local/tmp”+“pm install /data/local/tmp/xx.apk”. “adb in ...
- C# - 汉字与unicode之间的转换
/// <summary> /// 字符串转Unicode码 /// </summary> /// <returns>The to unicode.</ret ...
- WPF自定义控件(二)の重写原生控件样式模板
话外篇: 要写一个圆形控件,用Clip,重写模板,去除样式引用圆形图片可以有这三种方式. 开发过程中,我们有时候用WPF原生的控件就能实现自己的需求,但是样式.风格并不能满足我们的需求,那么我们该怎么 ...
- leetcode 74. Search a 2D Matrix 、240. Search a 2D Matrix II
74. Search a 2D Matrix 整个二维数组是有序排列的,可以把这个想象成一个有序的一维数组,然后用二分找中间值就好了. 这个时候需要将全部的长度转换为相应的坐标,/col获得x坐标,% ...