elasticsearch的映射
一.简介:
映射:在创建索引时,可以预先定义字段的类型(映射类型,也就是type,一个索引可以有一个或多个类型)及相关属性。
Elasticsearch会根据JSON源数据的基础类型猜测你想要的字段映射。将输入的数据转变成可搜索的索引项。Mapping就是我们定义的字段的数据类型,同时告诉Elasticsearch如何索引数据以及是否可以被搜索。
作用:会让索引建立的更加细致和完善。
二.映射类型:
1.1 动态映射:
字段和属性不需要预先事先定义。在你添加文档的时候,就会自动添加到索引,这个过程不需要事先在索引进行字段数据类型匹配之类,他会自己推断数据类型,动态映射是可以配置的。
1.2 显示映射:
和动态映射相反,显示映射需要我们在索引映射中进行预先定义。
1.3 更新当前映射:
一般我们不会改变当前的索引的映射类型和字段,因为这样,意味着废弃已经索引的文档。我们应该根据映射创建新的索引并重新索引数据。
三.内置类型:
1.string类型:
text(会进行分析【分词,建立倒排索引】),keyword【不会分析,只有完全匹配才能搜索到】,(string类型在es5后已经废弃了)
2.数字类型:
long、integer、short、byte、double、float
3.日期类型:
date(可以解析date和datetime(时分秒)等日期)
4.bool类型:
boolean(可以解析传递过来的值,True/False/Yes/No等都能解析成bool类型)
5.二进制数据类型:
binary(不会被检索)
6.复杂数据类型
数组:无需专门的数据类型
对象数据类型:object,单独的JSON对象
嵌套数据类型:nested,关于JSON对象的数组

如Company就是一个object类型

emplyment是一个nested类型
7.geo类型(地理数据类型):
地理点数据类型:geo_point,经纬点
地理形状数据类型:geo_shape
8.专业数据类型:
IPv4数据类型
完成数据类型:completion
单词计数数据类型:token_counts
三.数据类型可以接收的参数
1.简单概括:
| 属性 | 描述 | 适合类型 |
| store | 值为yes表示存储,为no表示不存储,默认为no | all |
| index | yes表示分析,no表示不分析,默认为true | string |
| null_value | 如果字段为空,可以设置一个默认值,比如"人生" | all |
| analyzer | 可以设置索引和搜索时用的分析器,默认使用的是standard分析器,还可以使用whitespace,simple,english | all |
| include_in_all | 默认es为每个文档定义一个特殊域_all,它的作用是让每个字段被搜索到,如果不想让某个字段被搜索到,可以设置为false | all |
| format | 时间格式字符串的模式 | date |
2.详细:
2.1符串可以接收的参数:
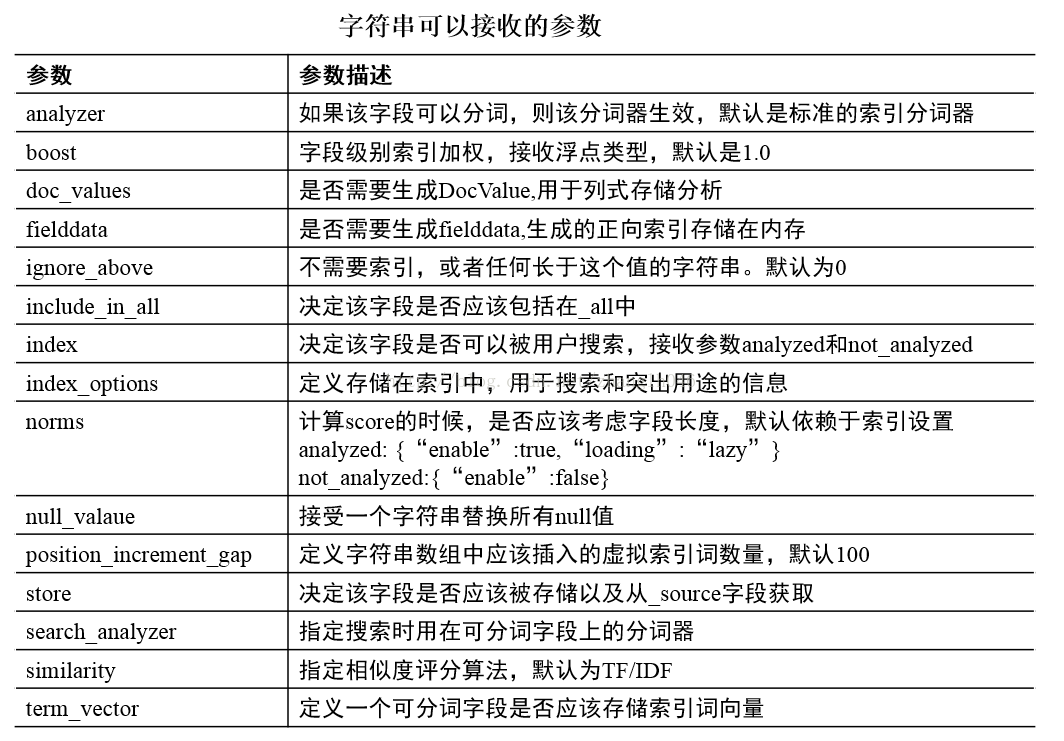
2.2数字型可以接收的参数:

2.3日期型可以接收的参数:

2.4布尔型可以接收的参数:

四.演示
1.创建索引及映射(创建映射后无法修改):
PUT lagou
{
#参数mappings
"mappings":
{
#指定表jobs
"jobs":
{
#参数(中文特性,性能)
"properties":
{
#指定类型为text,会分词等
"title":{
"type":"text"
},
#指定类型为integer
"salary_min":
{
"type":"integer"
},
"city":{
#指定类型为keyword,不分词,必须完全匹配才搜索得到
"type":"keyword"
}. #嵌套properies
"Company":{
"properties":{
"name":{
"type":"text"
},
"address":{
"type":"text"
}
}
},
#date类型
"pub-date":{
"type":"date"
}
}
}
}
}
运行成功
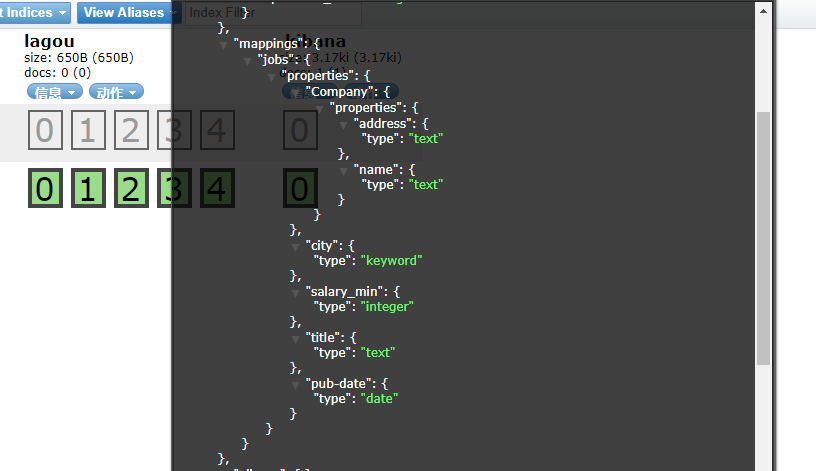
查看索引信息一致
2.数据插入:
PUT lagou/job/1
{
"title":"Java后端研发",
#这里插入时,为"20000"也行,会尝试转换为整型
"salary_min":20000,
"city":"北京",
"Company":{
"name":"百度",
"address":"北京"
},
"pub_date":"2018-10-28"
}
PUT lagou/job/2
{
"title":"Python分部式爬虫",
"salary_min":20000,
"city":"成都",
"Company":{
"name":"美团",
"address":"成都"
},
"pub_date":"2018-10-27"
}
PUT lagou/job/3
{
"title":"前端研发",
"salary_min":20000,
"city":"北京",
"Company":{
"name":"阿里",
"address":"北京"
},
"pub_date":"2018-10-28"
}
3.获取mapping:
#所有
GET _all/_mapping
#索引为拉钩
GET lagou/_mapping
#索引为lagou,type为job
GET lagou/_mapping/job
五.参考文献:
https://blog.csdn.net/zhanglh046/article/details/78529208
elasticsearch的映射的更多相关文章
- ElasticSearch 嵌套映射和过滤器及查询
ElasticSearch - 嵌套映射和过滤器 Because nested objects are indexed as separate hidden documents, we can’t q ...
- Elasticsearch mapping映射文件设置没有生效
Elasticsearch mapping映射文件设置没有生效 问题背景 我们一般会预先创建 Elasticsearch index的 mapping.properties 文件(类似于MySQL中的 ...
- Elasticsearch入门教程(三):Elasticsearch索引&映射
原文:Elasticsearch入门教程(三):Elasticsearch索引&映射 版权声明:本文为博主原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明. 本文 ...
- elasticsearch的映射(mapping)和分析(analysis)
转发自:http://blog.csdn.net/hzrandd/article/details/47128895 分析和分析器 分析(analysis)是这样一个过程: 首先,表征化一个文本块为适用 ...
- ES 11 - 配置Elasticsearch的映射 (mapping)
目录 1 映射的相关概念 1.1 什么是映射 1.2 映射的组成 1.3 元字段 1.4 字段的类型 2 如何配置mapping 2.1 创建mapping 2.2 更新mapping 2.3 查看m ...
- 利用kibana插件对Elasticsearch进行映射
映射(mapping) 映射是创建索引的时候,可以预先定义字段的类型以及相关属性 Elasticsearch会根据JSON源数据的基础类型去猜测你想要的字段映射.将输入的数据变成可搜索的索引项.Map ...
- elasticsearch(6) 映射和分析
类似关系型数据库中每个字段都有对应的数据类型,例如nvarchar.int.date等等,elasticsearch也会将文档中的字段映射成对应的数据类型,这一映射可以使ES自动生成的,也是可以由我们 ...
- Elasticsearch 自定义映射
尽管在很多情况下基本域数据类型 已经够用,但你经常需要为单独域自定义映射 ,特别是字符串域.自定义映射允许你执行下面的操作: 全文字符串域和精确值字符串域的区别 使用特定语言分析器 优化域以适应部分匹 ...
- Elasticsearch (2) - 映射
常用映射类型 核心的字段类型如下: String 字符串包括text和keyword两种类型: 1.text analyzer 通过analyzer属性指定分词器. 下边指定name的字段类型为tex ...
随机推荐
- 有时间了解一下Spark SQL parser的解析器架构
1:了解大体架构 2:了解流程以及各个类的职责 3:尝试编写一个
- 【移动端】meta使用
<!doctype html> <html> <head> <meta charset="utf-8"> <meta http ...
- 六、Oracle 存储过程
一.存储过程1语法:create procedure 名字is|as 声明变量begin 代码块end; 2.执行存储过程打开命令窗口,输入:exec 过程名字 3.打开输出命令:set server ...
- 16 python 初学(生成器)
列表生成器(列表生成式): 使用此种方式生成的列表会放在内存中占用内存 a = [x*2 for x in range(1, 11)] print(a) # >>> [2, 4, ...
- ogg-01027(长事务)
OGG-01027(长事务) 示例9-25: WARNING OGG-01027 Long Running Transaction: XID 82.4.242063, Items 0, Extra ...
- C# — 动态获取本地IP地址及可用端口
1.在VS中动态获取本地IP地址,代码如下: 2.获取本机的可用端口以及已使用的端口:
- selenium:解决页面元素display:none的方法
在UI自动化测试中,有时候会遇到页面元素无法定位的问题,包括xpath等方法都无法定位,是因为前端元素被设置为不可见导致. 这篇博客,介绍下如何通过JavaScript修改页面元素属性来定位的方法.. ...
- Vue2.x源码学习笔记-Vue实例的属性和方法整理
还是先从浏览器直观的感受下实例属性和方法. 实例属性: 对应解释如下: vm._uid // 自增的id vm._isVue // 标示是vue对象,避免被observe vm._renderProx ...
- F#.NET周报 2018第34周-Ionide下载量100万
回顾一下过去一周F#和.NET最新相关信息 原文 新闻 Ionide 你在VS Code 上写F# 是离不开他的. ^^ 下载100万了 .NET Core 2.1.3发布,支持LTS版本(L ...
- 【commons】时间日期工具类——commons-lang3-time
推荐参考:http://www.cnblogs.com/java-class/p/4845962.html https://blog.csdn.net/yihaoawang/article/detai ...