Kafka/Zookeeper集群的实现(二)
[root@kafkazk1 ~]# wget http://mirror.bit.edu.cn/apache/zookeeper/zookeeper-3.4.12/zookeeper-3.4.12.tar.gz
[root@kafkazk1 ~]# java -version
java version "1.8.0_131"
Java(TM) SE Runtime Environment (build 1.8.0_131-b11)
Java HotSpot(TM) 64-Bit Server VM (build 25.131-b11, mixed mode)
[root@kafkazk1 ~]# tar zxvf zookeeper-3.4.12.tar.gz -C /usr/local/
[root@kafkazk1 ~]# mv /usr/local/zookeeper-3.4.12/ /usr/local/zookeeper
[root@kafkazk1 conf]# cp zoo_sample.cfg zoo_sample.cfg.back
[root@kafkazk1 conf]# mv zoo_sample.cfg zoo.cfg
[root@kafkazk1 conf]# vim zoo.cfg
[root@kafkazk1 conf]# egrep -v "#|^$" zoo.cfg
tickTime=2000 #zookeeper使用基本时间单位,以毫秒为单位,用来控制心跳和超时
initLimit=10 #配置zookeeper集群中follower服务器初始化连接到Leader时,能够承受心跳时间间隔数;10*2000=20秒
syncLimit=5 #配置Leader与Follower之间发送消息,请求和应答时长不能超过心跳LinitLimit时间长度;5*2000=10秒
dataDir=/data/zookeeper #用于存储快照文件的目录
clientPort=2181 #zookeeper服务进程监听的TCP端口,默认情况下,会监听2181端口
server.=192.168.37.134::3888 #server.1:表示第几个服务器,IP地址表示本地IP,2888端口是服务器与集群中的Leader服务通信端口;
server.1=192.168.37.135:2888:3888 server.1=192.168.37.136:2888:3888
#echo "1" > /data/zookeeper/myid
# mkdir /data/zookeeper -p
# mkdir /data/zookeeper/zkdata -p
Ps:以下是其他两台(192.168.37.135/192.168.37.136)zookeeper配置依次对应即可
tickTime=2000
initLimit=10
syncLimit=5
dataDir=/data/zookeeper
dataLogDir=/data/zookeeper/zkdata
clientPort=2181
server.1=192.168.37.134:2888:3888
server.2=192.168.37.135:2888:3888
server.3=192.168.37.136:2888:3888
#echo "2" > /data/zookeeper/myid
# mkdir /data/zookeeper -p
# mkdir /data/zookeeper/zkdata -p
tickTime=2000
initLimit=10
syncLimit=5
dataDir=/data/zookeeper
dataLogDir=/data/zookeeper/zkdata
clientPort=2181
server.1=192.168.37.134:2888:3888
server.2=192.168.37.135:2888:3888
server.3=192.168.37.136:2888:3888
echo "3" > /data/zookeeper/myid
# mkdir /data/zookeeper -p
# mkdir /data/zookeeper/zkdata -p
添加环境变量到系统的/etc/profile,这样在任意路径都可执行“zkServer.sh start”启动命令了
[root@kafkazk1 conf]# cat <<EOF>>/etc/profile
> export ZOOKEEPER_HOME=/usr/local/zookeeper
> export PATH=\$PATH:\$ZOOKEEPER_HOME/bin
> EOF
[root@kafkazk1 conf]# source /etc/profile
[root@kafkazk1 conf]# zkServer.sh start
ZooKeeper JMX enabled by defaul
[root@kafkazk1 conf]# jps #可通过jps命令(jdk内置命令)验证zookeeeper是够启动
2809 QuorumPeerMain #Zookeeper启动进程,前面数字表示zookeeper进程PID
[root@kafkazk1 conf]# tail /usr/local/zookeeper/conf/zoo
zoo.cfg zookeeper.out zoo_sample.cfg.back
[root@kafkazk1 conf]# tail /usr/local/zookeeper/conf/zookeeper.out
-- ::, [myid:] - INFO [main:Environment@] - Server environment:os.arch=amd64
-- ::, [myid:] - INFO [main:Environment@] - Server environment:os.version=3.10.-.el7.x86_64
-- ::, [myid:] - INFO [main:Environment@] - Server environment:user.name=root
-- ::, [myid:] - INFO [main:Environment@] - Server environment:user.home=/root
-- ::, [myid:] - INFO [main:Environment@] - Server environment:user.dir=/usr/local/zookeeper/conf
-- ::, [myid:] - INFO [main:ZooKeeperServer@] - tickTime set to
-- ::, [myid:] - INFO [main:ZooKeeperServer@] - minSessionTimeout set to -
-- ::, [myid:] - INFO [main:ZooKeeperServer@] - maxSessionTimeout set to -
-- ::, [myid:] - INFO [main:ServerCnxnFactory@] - Using org.apache.zookeeper.server.NIOServerCnxnFactory as server connection factory
-- ::, [myid:] - INFO [main:NIOServerCnxnFactory@] - binding to port 0.0.0.0/0.0.0.0:
【Kafka分布式式集群构建】
[root@kafkazk1 ~]# wget https://mirrors.cnnic.cn/apache/kafka/2.0.0/kafka_2.11-2.0.0.tgz
[root@kafkazk1 ~]# tar zxvf kafka_2.11-2.0.0.tgz -C /usr/local/
[root@kafkazk1 ~]# mv /usr/local/kafka_2.11-2.0.0/ /usr/local/kafka
[root@kafkazk1 ~]# vim /usr/local/kafka/config/server.properties
broker.id=0 #集群节点唯一标识
listeners=PLAINTEXT://192.168.2.129:9092 #本地Kafka监听地址与端口号,可以设置监听地址为主机名或者IP地址,如果设置主机名,需要将主机名与IP对应关系解析到/etc/hosts中
num.network.threads=3
num.io.threads=
socket.send.buffer.bytes=
socket.receive.buffer.bytes=
socket.request.max.bytes=
log.dirs=/usr/local/kafka/logs #用于配置kafka保存数据的位置,kafka所有消息都会存在该目录下,可通过逗号指定多个路径,kafka会更具最少被使用的原则选择分配partition,
kafka在分配partition的选择原则是根据分配的partition的个数来决定的
num.partitions=6 #设置新创建的topic有多少个分区,
num.recovery.threads.per.data.dir=1 #
offsets.topic.replication.factor=
transaction.state.log.replication.factor=
transaction.state.log.min.isr=
log.retention.hours=60 #配置kafka中消息保存的时间,还支持log.retention.minutes和log.retention.ms配置项
log.segment.bytes=1073741824 #配置partition中每个segment数据文件的大小,默认是1Gb,如果超过这个大小,则自动创建一个新的segment file
log.retention.check.interval.ms=
zookeeper.connect=192.168.37.134:,192.168.37.135:,192.168.37.136:2181 #指定zookeeper所在地址,它存储了broker的元数据,
auto.create.topics.enable=true #用于设置是否自动创建topic,broker上面没有手动创建,此时如果consumer没有请求到topic,则broker会自动创建一个topic
delete.topic.enable=true 0.8.2版本之后,kafka提供了自动删除topic功能,但是默认情况下,不会直接删除,如果要从物理上删除(删除topic后,数据文件也会一同删除)就需要设置true
zookeeper.connection.timeout.ms=
group.initial.rebalance.delay.ms=
[root@kafkazk1 kafka]# nohup bin/kafka-server-start.sh config/server.properties &
【测试】
1)创建topic主题
[root@zk-kafkanode1 bin]# ./kafka-topics.sh --create --zookeeper 192.168.37.134:2181,192.168.37.135:2181,192.168.37.136:2181 --replication-factor 1 --partitions 3 --topic test_topic
2)查看各个主题状态信息
[root@zk-kafkanode1 bin]#./kafka-topics.sh --describe --zookeeper 192.168.2.129:2181,192.168.2.151:2181,192.168.2.155:2181 --topic test_bxytopic,test_topic
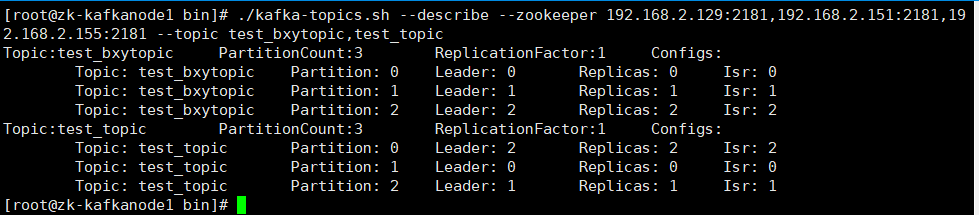
详情: leader:表示当前负责读写的Leader broker replicas:表示当前分区的所有副本对应的broker列表 isr:表示处于活跃状态的broker
--create:创建一个topic
--replication-factor:表示这个topic的副本数,这里的设置为1个
--partitions:指定topic的分区数,一般设置为小于或等于kafka集群节点数即可
--topic:指定要创建的topic的名称
--describe:查看topic指定
--from-beginning:该参数是读取生产消息的最开始的历史记录,如果不加上该指定,则读取当前生产消息
3)node1节点充当生产者producer,写入消息发送到broker各个集群主机列表
[root@zk-kafkanode1 bin]# ./kafka-console-producer.sh --broker-list 192.168.37.134:9092,192.168.37.135:9092,192.168.37.136:9092 --topic test_topic
[root@zk-kafkanode3 bin]# ./kafka-console-consumer.sh --bootstrap-server 192.168.37.134:9092,192.168.37.135:9092,192.168.37.136:9092 --topic test_topic --from-beginning
4)删除topic主题
[root@zk-kafkanode1 bin]# ./kafka-topics.sh --zookeeper 192.168.37.134:2181,192.168.37.135:2181,192.168.37.136:2181 --delete --topic test_topic
Topic test_topic is marked for deletion.
Note: This will have no impact if delete.topic.enable is not set to true.
【拓展】
ps:kafka版本之间还是有很大的区别的,就拿kafka2.11版本和2.10版本对比,本篇博客使用的是2.11版本,它的启动消费命令便有区别
2.11版本消费命令:./kafka-console-consumer.sh --bootstrap-server 192.168.37.134:9092,192.168.37.135:9092,192.168.37.136:9092 --topic test01 --from-beginning
2.10版本消费命令:./kafka-console-consumer.sh --zookeeper 192.168.37.134:2181,192.168.37.135:2181,192.168.37.136:2181 --topic test01 --from-beginning
在生产者上,命令没区别,但是生产界面没有了箭头,哈哈,当时还以为是卡屏了呢,折腾了好久~~

Kafka/Zookeeper集群的实现(二)的更多相关文章
- kafka+zookeeper集群
参考: kafka中文文档 快速搭建kafka+zookeeper高可用集群 kafka+zookeeper集群搭建 kafka+zookeeper集群部署 kafka集群部署 kafk ...
- Kafka+Zookeeper集群搭建
上次介绍了ES集群搭建的方法,希望能帮助大家,这儿我再接着介绍kafka集群,接着上次搭建的效果. 首先我们来简单了解下什么是kafka和zookeeper? Apache kafka 是一个分布式的 ...
- 消息中间件kafka+zookeeper集群部署、测试与应用
业务系统中,通常会遇到这些场景:A系统向B系统主动推送一个处理请求:A系统向B系统发送一个业务处理请求,因为某些原因(断电.宕机..),B业务系统挂机了,A系统发起的请求处理失败:前端应用并发量过大, ...
- 安装kafka + zookeeper集群
系统:centos 7.4 要求:jdk :1.8.x kafka_2.11-1.1.0 1.绑定/etc/hosts 10.10.10.xxx online-ops-xxx-0110.10 ...
- KAFKA && zookeeper 集群安装
服务器:#vim /etc/hosts10.16.166.90 sh-xxx-xxx-xxx-online-0110.16.168.220 sh-xx-xxx-xxx-online-0210.16.1 ...
- docker-搭建 kafka+zookeeper集群
拉取容器 docker pull wurstmeister/zookeeper docker pull wurstmeister/kafka 这里演示使 ...
- 【转】kafka&zookeeper集群搭建指南
[转自]:http://www.cnblogs.com/luotianshuai/p/5206662.html 待续...
- ELK+zookeeper+kafka+rsyslog集群搭建
前言 环境困境: 1.开发人员无法登陆服务器 2.各系统都有日志,日志数据分散难以查找 3.日志数据量大,查询忙,不能实时 环境要求: 1.日志需要标准化 集群流程图: 角色: 软件: 以 ...
- 【拆分版】Docker-compose构建Zookeeper集群管理Kafka集群
写在前边 在搭建Logstash多节点之前,想到就算先搭好Logstash启动会因为日志无法连接到Kafka Brokers而无限重试,所以这里先构建下Zookeeper集群管理的Kafka集群. 众 ...
随机推荐
- vue el-tree:默认展开第几级节点
需求描述: Tree 树形结构,默认展开第二级菜单. 查 element 文档: 解决方法: 设置 :default-expanded-keys 的值为 idArr 数组, <el-tree ...
- 用于主题检测的临时日志(c5ac07a5-5dab-45d9-8dc2-a3b27be6e507 - 3bfe001a-32de-4114-a6b4-4005b770f6d7)
这是一个未删除的临时日志.请手动删除它.(5051e554-d10d-4e48-b2ca-37c38a30153a - 3bfe001a-32de-4114-a6b4-4005b770f6d7)
- BeautifulSoup解析器的选择
BeautifulSoup解析器 在我们使用BeautifulSoup的时候,选择怎样的解析器是至关重要的.使用不同的解析器有可能会出现不同的结果! 今天遇到一个坑,在解析某html的时候.使用htm ...
- 46)django-发送邮件
django已封装好了邮件发送功能,可以直接调用发送模块 1. 配置相关参数 如果用的是 阿里云的企业邮箱,则类似于下面: 在 settings.py 的最后面加上类似这些 EMAIL_BACKEND ...
- DecimalFormat详解
DecimalFormat继承自NumberFormat,可以使用它将十进制的数以不同形式格式化为字符串形式,可以控制前导和尾随0.前缀.后缀.分组(千).小数分隔符等,如果要更改格式符号(例如小数点 ...
- Confluence 6 匿名访问远程 API
Confluence 管理员可能希望为匿名用户禁用远程访问 API.这样能够避免恶意软件随意在网站进行批量修改. 希望禁用远程访问 API: 在屏幕的右上角单击 控制台按钮 ,然后选择 General ...
- Confluence 6 后台中为站点添加应用导航
Confluence 6 后台中为站点添加应用导航的连界面和方法. https://www.cwiki.us/display/CONFLUENCEWIKI/Configuring+the+Site+H ...
- nginx实践(一)之静态资源web服务
静态资源服务场景CDN 配置语法-文件读取(nginx优势之一sendfile) 配置语法-tcp_nopush 简单的说就是把多个包合并,一次传输给客户端 配置语法-tap_nodelay 配置语法 ...
- TypeError: $(…).tooltip is not a function
问题描述:改了一个页面,发现进入这个页面的时候就一直在load···,F12看了一下,发现报了这个错误TypeError: $(…).tooltip is not a function,然后我就百度了 ...
- php回调函数的概念及实例
php提供了两个内置函数call_user_func()和call_user_func_array()提供对回调函数的支持.这两个函数的区别是call_user_func_array是以数组的形式接收 ...