Apache Flink 简单安装
流计算这两年很火了,可能对数据的实时性要求高。现在用的hadoop框架,对流计算的支持,主要还是微批(spark),也不支持“Exactly Once”语义(可以使用外接的数据库解决),公司项目可能会用所以就下载了个Flink试试。
1. 下载解压
打开官网:https://flink.apache.org/, “DOWNLOAD”,下载对应 hadoop 和scala 版本。Flink以来JDK和HADOOP,提前下载。
[root@spring software]# wget http://mirrors.tuna.tsinghua.edu.cn/apache/flink/flink-1.7.1/flink-1.7.1-bin-hadoop27-scala_2.12.tgz
[root@spring software]# tar -zxvf flink-1.7.-bin-hadoop27-scala_2..tgz
[root@spring software]# ll
total
drwxrwxrwx venn venn Dec : flink-1.7.
-rw-r--r-- root root Dec : flink-1.7.-bin-hadoop27-scala_2..tgz
drwxr-xr-x. Apr jdk1.
-rw-r--r--. root root Dec : jdk-8u91-linux-x64.tar.gz
2. 配置
官网教程: https://ci.apache.org/projects/flink/flink-docs-release-1.7/tutorials/local_setup.html
在bin/config.sh 是Flink 的配置文件,但是不需要配置,只需要有配置JAVA_HOME, HADOOP_HOME ( 或者HADOOP_CONF_DIR)
export JAVA_HOME=/opt/software/jdk1.
export CLASSPATH=.:$JAVA_HOME/lib
export PATH=$JAVA_HOME/bin:$PATH
export HADOOP_HOME=/etc/hadoop
export HADOOP_CONF_DIR=/etc/hadoop/conf [root@spring bin]# source /etc/profile
[root@spring bin]# echo $HADOOP_CONF_DIR
/etc/hadoop/conf
[root@spring bin]# echo $HADOOP_HOME
/etc/hadoop
[root@spring bin]# echo $JAVA_HOME
/opt/software/jdk1.
config.sh
KEY_ENV_JAVA_HOME="env.java.home" # java使用环境变量 # Check if deprecated HADOOP_HOME is set, and specify config path to HADOOP_CONF_DIR if it's empty. # 读取环境变量 HADOOP_HOME HADOOP_CONF_DIR
if [ -z "$HADOOP_CONF_DIR" ]; then
if [ -n "$HADOOP_HOME" ]; then
# HADOOP_HOME is set. Check if its a Hadoop .x or .x HADOOP_HOME path
if [ -d "$HADOOP_HOME/conf" ]; then
# its a Hadoop .x
HADOOP_CONF_DIR="$HADOOP_HOME/conf"
fi
if [ -d "$HADOOP_HOME/etc/hadoop" ]; then
# Its Hadoop 2.2+
HADOOP_CONF_DIR="$HADOOP_HOME/etc/hadoop"
fi
fi
fi # try and set HADOOP_CONF_DIR to some common default if it's not set
if [ -z "$HADOOP_CONF_DIR" ]; then
if [ -d "/etc/hadoop/conf" ]; then
echo "Setting HADOOP_CONF_DIR=/etc/hadoop/conf because no HADOOP_CONF_DIR was set."
HADOOP_CONF_DIR="/etc/hadoop/conf"
fi
fi
4. 流计算demo wordcount
使用nc 模拟输入流,输入数据
[root@spring log]# nc -l ...
启动wordcount demo
[root@spring flink-1.7.]# ./bin/flink run examples/streaming/SocketWindowWordCount.jar --port
Starting execution of program
nc输入继续输入数据。。。
"ctrl + C" 关闭nc,wordcount demo 随之关闭。
trewt
re
w
^C # kill nc
[root@spring log]# # wordcount 完成
[root@spring flink-1.7.]# ./bin/flink run examples/streaming/SocketWindowWordCount.jar --port
Starting execution of program
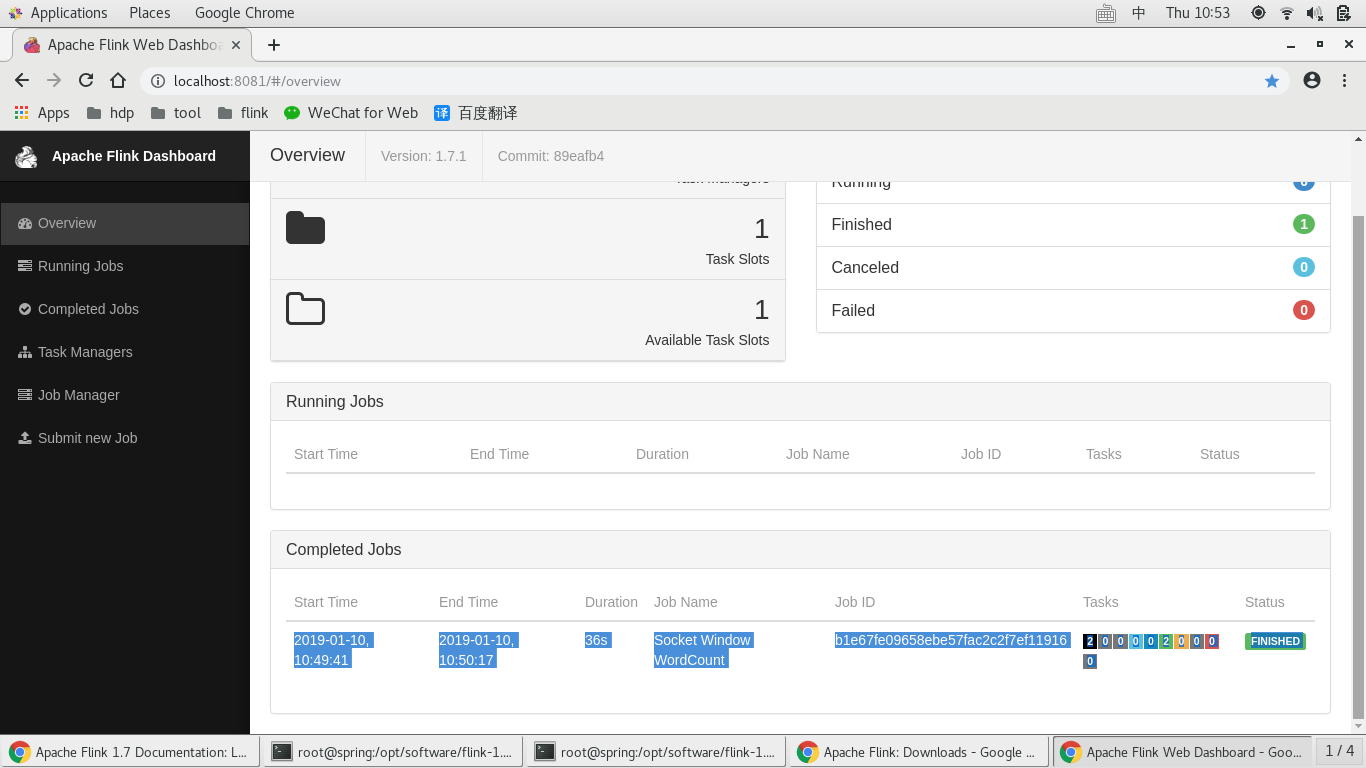
Program execution finished
Job with JobID b1e67fe09658ebe57fac2c2f7ef11916 has finished.
Job Runtime: ms
查看统计结果:
[root@spring flink-1.7.]# more -f log/flink-root-taskexecutor-2-spring.hadoop.out # 第一次执行是 0
:
qq :
:
tyr :
tre :
o :
i :
u :
y :
t :
r :
e :
w :
q :
:
:
:
:
:
:
:
:
:
rew :
:
:
:
trew :
fds :
:
其 :
rfd :
其q :
fdsgfd :
trewtg :
raq :
dfs :
eh :
r :
wyht :
re :
rds :
g :
fgrd :
ygtre :
fretg :
trewt :
erw :
wtg :
gre :
ds :
fv :
:
gfr :
t :
ghrw :
s :
gvdf :
d :
wg :
er :
wt :
re :
rewt :
redwg :
查看管理控制台

本文所有内容来自官网教程,本地执行,https://ci.apache.org/projects/flink/flink-docs-release-1.7/tutorials/local_setup.html
搞定
Apache Flink 简单安装的更多相关文章
- Apache Flink教程----安装初体验
1.window 版本安装 https://flink.apache.org/downloads.html#apache-flink-164 D:\flink-1.6.2-bin-scala_2\fl ...
- redhat 7.6 apache 服务简单安装-01
rpm -qa | grep httpd //该命令查看apache是否安装,下面图片是已安装,未安装不会显示任何内容 yum install httpd -y ...
- Apache Spark简单介绍、安装及使用
Apache Spark简介 Apache Spark是一个高速的通用型计算引擎,用来实现分布式的大规模数据的处理任务. 分布式的处理方式可以使以前单台计算机面对大规模数据时处理不了的情况成为可能. ...
- web服务的简单介绍及apache服务的安装
一,web服务的作用: 是指驻留于因特网上某种类型计算机的程序,可以向浏览器等Web客户端提供文档.可以放置网站文件,让全世界浏览: 可以放置数据让全世界下载.目前最主流的三个Web服务器是Ap ...
- centos7.2安装apache比较简单,直接上代码
centos7.2安装apache比较简单,直接上代码 1.安装 yum install httpd 2.启动apache systemctl start httpd.service 3. ...
- Apache Flink
Flink 剖析 1.概述 在如今数据爆炸的时代,企业的数据量与日俱增,大数据产品层出不穷.今天给大家分享一款产品—— Apache Flink,目前,已是 Apache 顶级项目之一.那么,接下来, ...
- 新一代大数据处理引擎 Apache Flink
https://www.ibm.com/developerworks/cn/opensource/os-cn-apache-flink/index.html 大数据计算引擎的发展 这几年大数据的飞速发 ...
- Apache Flink系列(1)-概述
一.设计思想及介绍 基本思想:“一切数据都是流,批是流的特例” 1.Micro Batching 模式 在Micro-Batching模式的架构实现上就有一个自然流数据流入系统进行攒批的过程,这在一定 ...
- 深入理解Apache Flink
Apache Flink(下简称Flink)项目是大数据处理领域最近冉冉升起的一颗新星,其不同于其他大数据项目的诸多特性吸引了越来越多人的关注.本文将深入分析Flink的一些关键技术与特性,希望能够帮 ...
随机推荐
- [Flutter] 因为不讲这个重点, 全网所有 flutter 实战视频沦为二流课程
二流课程也有其存在的价值,看到不同组件的轮流使用也是不断熟悉的过程,不过太眼花缭乱了. 授人以渔,基础用法是其一,讲清套路是其二,不然坑萌新. 那么 flutter 的套路是什么呢,我认为有下面几点: ...
- 求$N^N$的首位数字
正如"大得多"定理所言,当$n\longrightarrow \infty$时: $$ n^n \gg n! \gg a^n \gg n^b \gg ln^kn $$ $f(n) = n^n$的增长 ...
- Java环境变量PATH和CLASSPATH
Java开发中常用到环境变量的配置,下面简单介绍下Java中经常配置的环境变量:PATH和CLASSPATH. 1.PATH环境变量 1.1 作用简介 安装完JDK(Java Development ...
- PYTHON基础-入门
变量名可以是数字,字母,下划线,字母不能开头.
- 云笔记项目-Spring事务学习-传播NOT_SUPPORTED
接下来测试事务传播属性设置为NOT_SUPPORTED Service层 Service层主要设置如下,其中还插入了REQUIRED作为比较. package Service; import java ...
- C# File API
[C# File API] 1.System.IO.File Provides static methods for the creation, copying, deletion, moving, ...
- Java虚拟机运行时数据区域及垃圾回收算法
程序计数器 记录正在执行的虚拟机字节码指令的地址(如果正在执行的是本地方法则为空). Java 虚拟机栈 每个 Java 方法在执行的同时会创建一个栈帧用于存储局部变量表.操作数栈.动态链接.方法出口 ...
- windows server 2012R2 故障转移集群配置
配置说明: AD:10.10.1.10/24 Node-2:10.10.1.20/24 Node-3:10.10.1.30/24 zhangsan-PC:10.10.1.50/24 VIP1:10 ...
- 关于Image创建的内存管理
image创建方法 [UIImage imageNamed:imageName] 上述方法创建的image,会常驻在内存中,不会随着imageView的dealloc而释放内存. NSString * ...
- docker-compose安装
安装docker-compose两种最新的docker安装方式 1.从github上下载docker-compose二进制文件安装下载最新版的docker-compose文件 $ sudo curl ...