Acoustic modelling from the signal domain using CNNs
3. Neural network architecture
此处描述了在本文当中所使用的网络结构,和所提取的关键特征(key features)。首先,描述了两个新型的网络结构:the network-in-network nonlinearity和the statistics extraction layer(NIN非线性结构和统计信息提取层)。
3.1 Network-in-Network nonlinearity
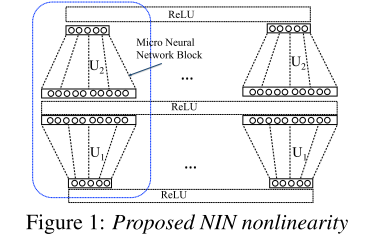
如图(1)所示,该网络结构是一个多对多的非线性系统,由两个块对角阵组成,在使用的过程中,在同一层中,所有的NIN模块是参数共享的,且互相之间不重叠(non-overlapping)。
在NIN的内部,转换块(transformation block)\(U_1\)是尺寸为\(m\times k\)的矩阵,将尺寸为\(m\)的输入映射到维度为\(k\)的高维空间中,然后使用Relu函数进行非线性映射;\(U_2\)是尺寸为\(k\times n\)的矩阵,将非线性变化后的\(k\)维变量映射到\(n\)为空间当中,再进行Relu非线性映射。该NIN模块在论文中称之为“micro neural network blocks”。
如果,NIN模块在单层网络中共享权值,那么\(U_1\)的每一列可以解释为一维卷积核,且卷积核的尺寸为\(m\),卷积的步长为\(m\)。
对于此处的理解:
\[
x \cdot U_{(m,k)}=x \cdot [u_1,u_2 \cdots u_k]=[x\cdot u_1,x\cdots u_2 \cdots x\cdot u_k]
\]
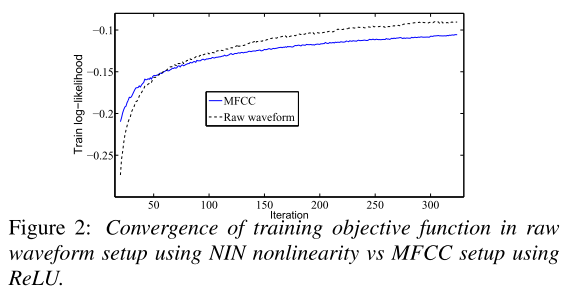
在图(2)当中,将本文提出的网络与基于MFCC的基线系统目标函数的收敛情况进行对比,可以得到:本文提出的网络目标函数的收敛速度较快,且收敛之后的目标函数的数值较好。
Acoustic modelling from the signal domain using CNNs的更多相关文章
- 基于SincNet的原始波形说话人识别
speaker recognition from raw waveform with SincNet Mirco Ravanelli, Yoshua Bengio 作为一种可行的替代i-vector的 ...
- 论文翻译:2018_Deep Learning for Acoustic Echo Cancellation in Noisy and Double-Talk Scenarios
论文地址:深度学习用于噪音和双语场景下的回声消除 博客地址:https://www.cnblogs.com/LXP-Never/p/14210359.html 摘要 传统的声学回声消除(AEC)通过使 ...
- 论文翻译:2020_Attention Wave-U-Net for Acoustic Echo Cancellation
论文地址:http://www.interspeech2020.org/uploadfile/pdf/Thu-1-10-10.pdf Attention Wave-U-Net 的回声消除 摘要 提出了 ...
- Paper List ABOUT Deep Learning
Deep Learning 方向的部分 Paper ,自用.一 RNN 1 Recurrent neural network based language model RNN用在语言模型上的开山之作 ...
- Deep Learning方向的paper
转载 http://hi.baidu.com/chb_seaok/item/6307c0d0363170e73cc2cb65 个人阅读的Deep Learning方向的paper整理,分了几部分吧,但 ...
- Introduction to CELP Coding
Speex is based on CELP, which stands for Code Excited Linear Prediction. This section attempts to in ...
- Tips on Acoustic Signal Processing
1.声音的三个主要的主观属性(即音量.音调.音色).音色(Timbre)是指不同的声音的频率表现在波形方面总是有与众不同的特性,音色的不同取决于不同的泛音.频率的高低决定声音的音调,振幅的大小决定声音 ...
- 论文翻译:2020_Joint NN-Supported Multichannel Reduction of Acoustic Echo, Reverberation and Noise
论文地址:https://ieeexploreieee.fenshishang.com/abstract/document/9142362 神经网络支持的回声.混响和噪声联合多通道降噪 摘要 我们考虑 ...
- 《The challenge of realistic music generation: modelling raw audio at scale》论文阅读笔记
The challenge of realistic music generation: modelling raw audio at scale 作者:Deep mind三位大神 出处:NIPS ...
随机推荐
- python学习 生成随机函数 random模块的用法
random模块是用于生成随机数 常用函数 函数 含义 random() 生成一个[0,1.0)之间的随机浮点数 uniform(a,b) 生成一个a到b之间的随机浮点数 randint(a,b) 生 ...
- MFC 中MessageBox 显示在所有窗口的最上面
int MessageBox( HWND hWnd, // handle of owner window LPCTSTR lpText, // address of ...
- Golang源码探索(二) 协程的实现原理(转)
Golang最大的特色可以说是协程(goroutine)了, 协程让本来很复杂的异步编程变得简单, 让程序员不再需要面对回调地狱,虽然现在引入了协程的语言越来越多, 但go中的协程仍然是实现的是最彻底 ...
- 1506.01186-Cyclical Learning Rates for Training Neural Networks
1506.01186-Cyclical Learning Rates for Training Neural Networks 论文中提出了一种循环调整学习率来训练模型的方式. 如下图: 通过循环的线 ...
- Mysql出现(10061)错误提示的暴力解决办法
上个月我还在说别人的怎么老是会错呢,我的就没事,嘿 今天就轮到我了 我发誓 我绝对没碰它 是它先动的手 言归正传 下面给你们 介绍 终极大招 为什么是终极大招呢 因为网上那些前辈们的方法我都试 ...
- 调试HDF0308-A50的相机驱动。
使用rk3128做为主芯片: 使用andriod5.1-sdk软件包. 1.在rk3128-86v.dts 中加入头文件 #include "rk3128-cif-sensor.dtsi&q ...
- python入门(十三):面向对象(继承、重写、公有、私有)
1. 三种类定义的写法 class P1:#定义类 加不加()都可以 pass class P2(): #带(),且括号中为空,类定义 pass ...
- js 获取get参数
function get_val(url,key) { var two= url.split("?"); var right= two[1]; var values = right ...
- 摘选改善Python程序的91个建议2
62.metaclass stackflow 中文翻译 63.Python对象协议 https://zhuanlan.zhihu.com/p/26760180 ...
- django xadmin多对多字段过滤(含filter的反向查询)
要实现的功能: 继昨天实现拓展User模型使其得到其上级用户,今天要实现某些模型与用户多对多字段过滤功能. 功能描述:以用户指派功能为例,当前用户将文件指派给多个下级,修改前 程序会将所有用户都显示出 ...