Coursera Deep Learning 3 Structuring Machine Learning Projects, ML Strategy
Why ML stategy
怎么提高预测准确度?有了stategy就知道从哪些地方入手,而不至于找错方向做无用功.


Satisficing and Optimizing metric

上图中,running time <= 100ms 就是satisficing,accuracy 就是 optimazing.
Dev set and test set should be from same distribution.
传统的traing set/ dev set / test set 比例是60/20/20, 在大数据时代可以是 98/1/1 这样的比例.
有些时候不能只看error rate 的值,下面这个图讲到算法A虽然error值低一些,但是如果含有色情图片就是不能接受的,所以需要一种新的计算error的方法, 对特定的图片加权.

还有一种情况是下面讲的,当你去做预测的时候,发现B的实际效果,比如你在高精度training set上训练的model, 用户却经常上传一些不专业的或者模糊的照片。这时你就要调整你的training set了.

Comparing to human performance
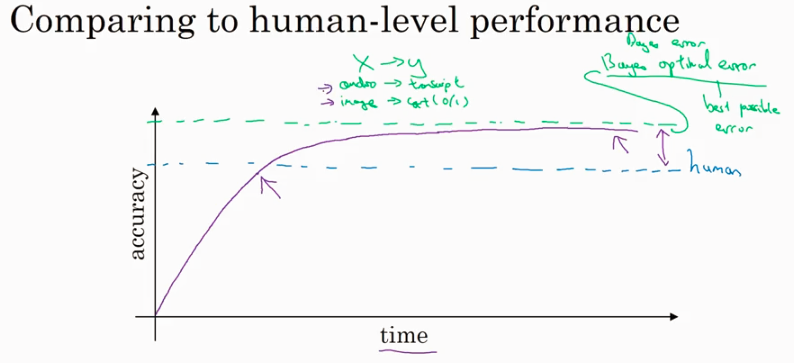
why comparing to human performance, 我的理解就是找到差距,变的更强大.

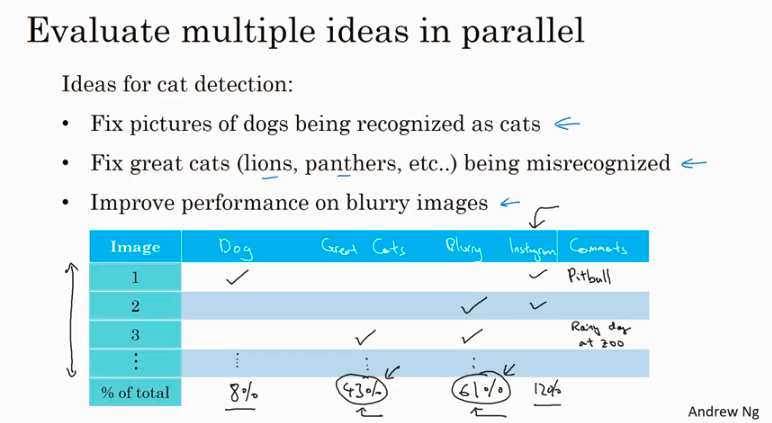
Error analysis
从mislabelled example 里统计各种不同类型的error, 看哪种占比大就从哪里入手.

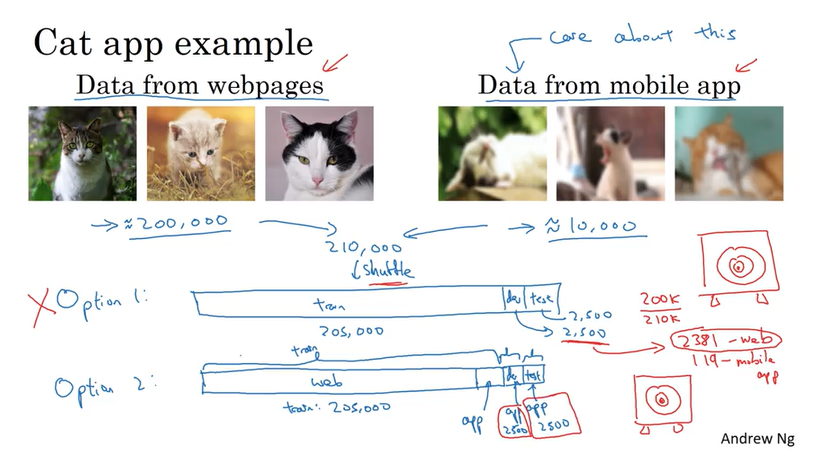
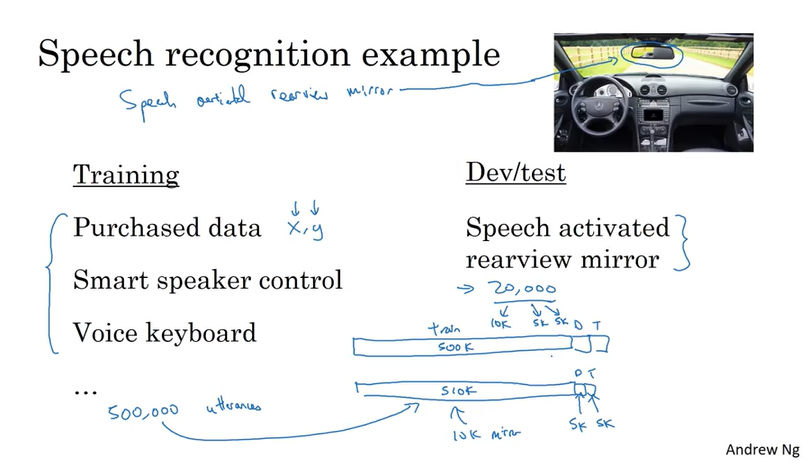
Mismatched training and dev/test set (training data 和 dev/test data 来自不同的distribution)
把一些来自实际场景的数据,这些数据有价值但是数量不多,一部分放在training set里,另一部分都放在dev/test set. 就是下面的推荐的Option 2,dev set 和test set 里都是真正有价值的data. 这样做的好处使得我们的model 面向最终解决的问题.
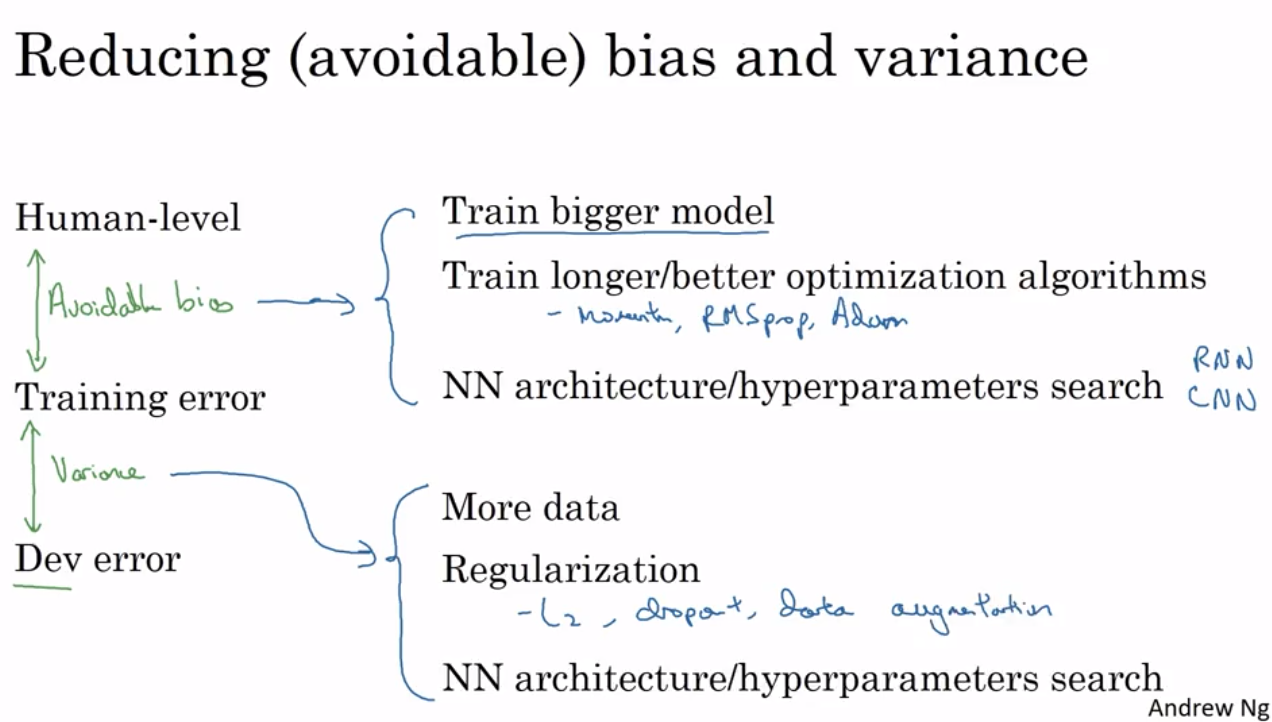
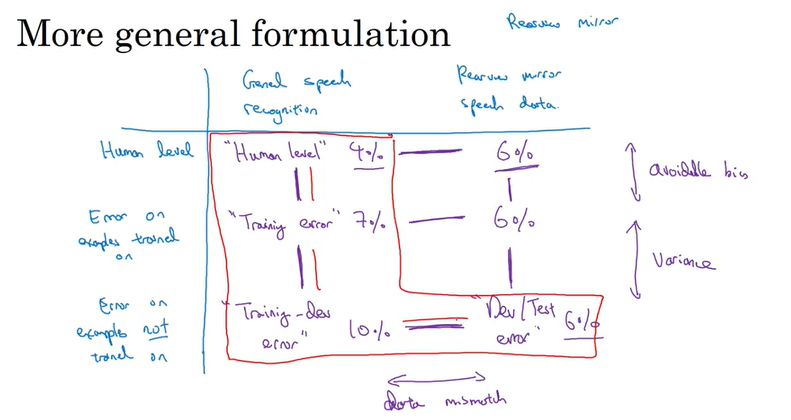
在training set 和dev/test set 有不同的distribution时,根据训练得到的不同error值,怎么定位到底是bias, variance, 还是 data mismatch 问题?
可以多分一份 training-dev 的数据集


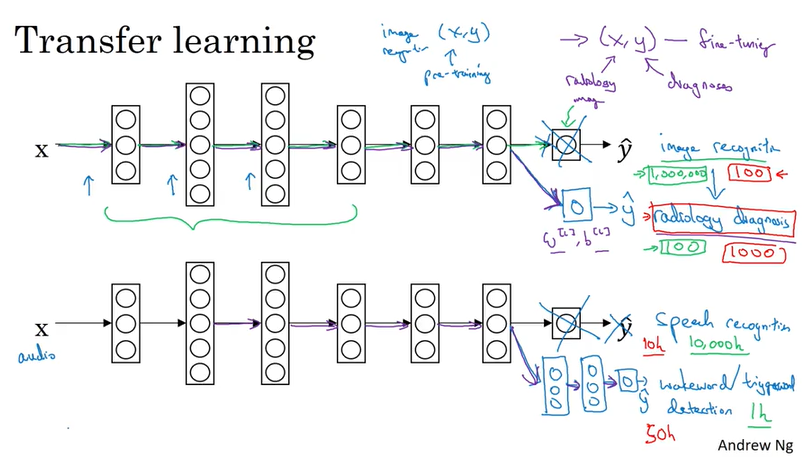
How to address data mismatch ?



Transfer learning

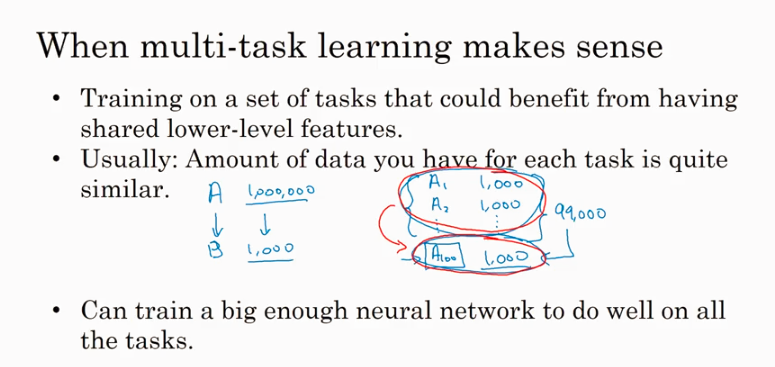
Mult-task learning
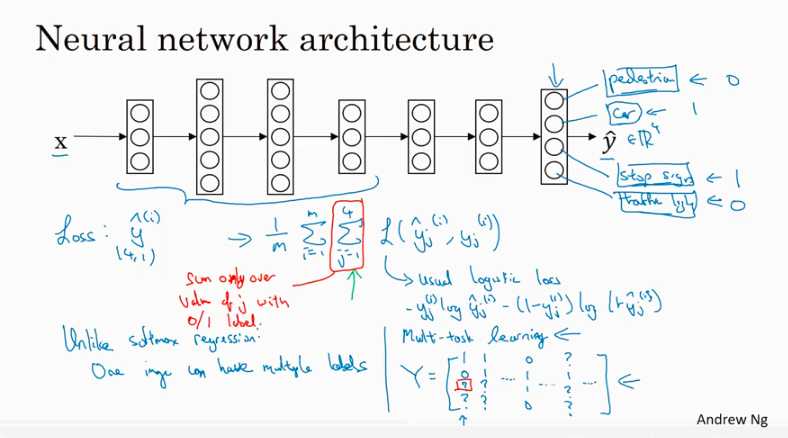
只要神经网络够大,multi-task learning 的performance会比针对每种分类跑一次softmax分类效率更高 (softmax 一个输出只包含一种类型, multi-task 一个输出可以有多个类型,比如既有行人又有汽车). multi-task learing is much less than transfer leaning in practice.
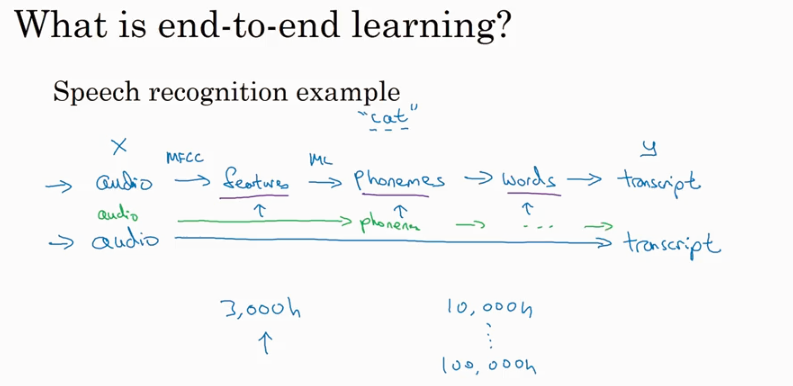
End-to-end learning
一般的做法是经历很多中间步骤,但是E2E learning 就是直接从raw data X 到 Y. 在有大量数据的情况下E2E 可能会有很好的performance, 但是
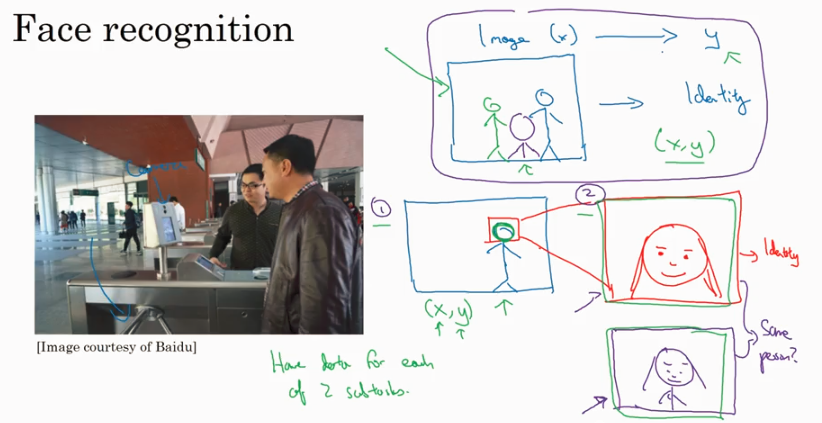


补充阅读:
什么是precision 和 recall
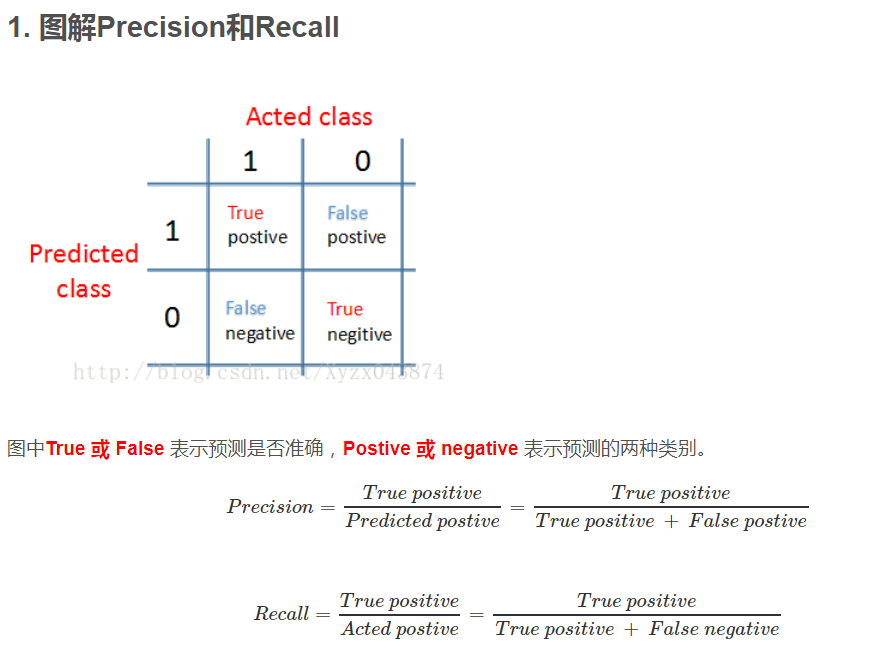
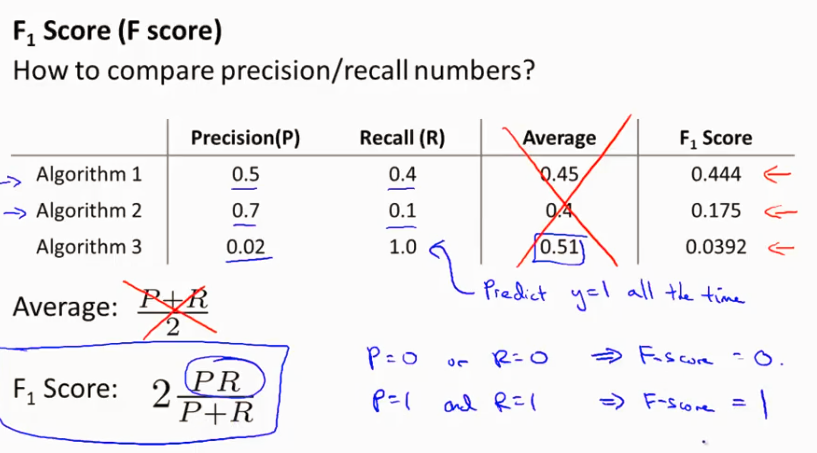
关于Precision 和 Recall 的作用有个很好的例子可以说明,就是针对 skewed data 比如判断病人是否有癌症,一个Model直接hardcode 使得 y=0 (没有癌症)也可以得到很好的预测结果,这个model 明显不合理,就引出了使用 Precision 和 Recall 来判断一个model 的优劣. 在这两个值都很大的情况下(接近1)就可以说Model很好.
用一个值来判断可以用F1 score.
Coursera Deep Learning 3 Structuring Machine Learning Projects, ML Strategy的更多相关文章
- 《Structuring Machine Learning Projects》课堂笔记
Lesson 3 Structuring Machine Learning Projects 这篇文章其实是 Coursera 上吴恩达老师的深度学习专业课程的第三门课程的课程笔记. 参考了其他人的笔 ...
- Decision Boundaries for Deep Learning and other Machine Learning classifiers
Decision Boundaries for Deep Learning and other Machine Learning classifiers H2O, one of the leading ...
- [C5] Andrew Ng - Structuring Machine Learning Projects
About this Course You will learn how to build a successful machine learning project. If you aspire t ...
- 课程三(Structuring Machine Learning Projects),第一周(ML strategy(1)) —— 0.Learning Goals
Learning Goals Understand why Machine Learning strategy is important Apply satisficing and optimizin ...
- 课程三(Structuring Machine Learning Projects),第一周(ML strategy(1)) —— 1.Machine learning Flight simulator:Bird recognition in the city of Peacetopia (case study)
[]To help you practice strategies for machine learning, the following exercise will present an in-de ...
- Structuring Machine Learning Projects 笔记
1 Machine Learning strategy 1.1 为什么有机器学习调节策略 当你的机器学习系统的性能不佳时,你会想到许多改进的方法.但是选择错误的方向进行改进,会使你花费大量的时间,但是 ...
- 吴恩达《深度学习》-课后测验-第三门课 结构化机器学习项目(Structuring Machine Learning Projects)-Week1 Bird recognition in the city of Peacetopia (case study)( 和平之城中的鸟类识别(案例研究))
Week1 Bird recognition in the city of Peacetopia (case study)( 和平之城中的鸟类识别(案例研究)) 1.Problem Statement ...
- [C3W2] Structuring Machine Learning Projects - ML Strategy 2
第二周:机器学习策略(2)(ML Strategy(2)) 误差分析(Carrying out error analysis) 你好,欢迎回来,如果你希望让学习算法能够胜任人类能做的任务,但你的学习算 ...
- 课程回顾-Structuring Machine Learning Projects
正交化 Orthogonalization单一评价指标保证训练.验证.测试的数据分布一致不同的错误错误分析数据分布不一致迁移学习 transfer learning多任务学习 Multi-task l ...
随机推荐
- VS Code汉化
F1搜索 Configure Language { // Defines VS Code's display language. // See https://go.microsoft.com/fw ...
- A1140. Look-and-say Sequence
Look-and-say sequence is a sequence of integers as the following: D, D1, D111, D113, D11231, D112213 ...
- MVC相关问题归纳
问题: 1.How MVC pattern flows 2.对象模型.关系模型 3.OR Framework 4.EF(Entity FrameWork)实体框架 5.模型驱动数据数据驱动模型的两种方 ...
- Vue+Django2.0 restframework打造前后端分离的生鲜电商项目(1)
1.开发环境配置 Windows7 64位旗舰版 python3.6 node.js mysql navicat pycharm webstorm或vscode 2.项目初始化 新版的pycharm很 ...
- ES6(promise)_解决回调地狱初体验
一.前言 通过这个例子对promise解决回调地狱问题有一个初步理解. 二.主要内容 1.回调地狱:如下图所示,一个回调函数里面嵌套一个回调函数,这样的代码可读性较低也比较恶心 2.下面用一个简单的例 ...
- IAR STM32 ------ CSTACK HEAP 设置一次可用栈的大小,HardFault_Hander
CSTACK:限制函数中定义数组的最大值,否则进入HardFault_Hander HEAP:限制动态分配内存(C函数库中的malloc)的大小,不用可以设置为0
- 关键字(7):属性的增删改add,drop,modify
新建一张表: )); 注意:新建表时,表里面至少要有一个字段 删除整张表: drop table nac_user.a_bt; 增加表的一个属性: ) default('M') 新增外键 ...
- python自动化开发-[第十二天]-前端Css
CSS基本语法 CSS 规则由两个主要的部分构成:选择器,以及一条或多条声明. selector { property: value; property: value; ... property: v ...
- ARM三级流水线
title: ARM三级流水线 tags: ARM date: 2018-10-14 16:57:10 --- 参考: ARM指令集E004armproc.chm ARM Architecture R ...
- 11:12:21.924 [main] DEBUG org.apache.ibatis.logging.LogFactory - Logging initialized using 'class org.apache.ibatis.logging.slf4j.Slf4jImpl' adapter.
11:12:21.924 [main] DEBUG org.apache.ibatis.logging.LogFactory - Logging initialized using 'class or ...