Python爬虫之足球小将动漫(图片)下载
尽管俄罗斯世界杯的热度已经褪去,但这届世界杯还是给全世界人民留下了无数难忘的回忆,不知你的回忆里有没有日本队的身影?本次世界杯中,日本队的表现让人眼前一亮,很难想象,就是这样一只队伍,二十几年还是我们国家足球队的水平一样,也许还不如我们国足呢。
足球小将(队长小翼、キャプテン翼)由日本著名动漫家高桥阳一于1981年开始连载,从此这部动漫就伴随着一代又一代的日本,甚至全世界的少年儿童成长,也在无形有形中促进了日本足球的进步。本届世界杯中,在日本与比利时的比赛中,日本球迷们高举队长小翼的画面就足以证明这部动漫对日本足球的深远影响。
本文将介绍如何利用Python爬虫来下载足球小将的动漫图片。
首先,我们需要下载的网址为:https://mhpic.samanlehua.com/comic/Z%2F足球小将翼%2F第01卷%2F2.jpg-noresize.webp, 截图如下:

我们注意到,在这个网址中,只有卷数和动漫图片的序号在发生改变,因此,我们只需要找到总共的卷数以及每一卷中所包含的图片即可完成此爬虫。
不过稍微需要注意的是,爬虫下载下来的图片格式为webp格式。WebP(发音 weppy,项目主页),是一种支持有损压缩和无损压缩的图片文件格式,派生自图像编码格式 VP8。根据 Google 的测试,无损压缩后的 WebP 比 PNG 文件少了 45% 的文件大小,即使这些 PNG 文件经过其他压缩工具压缩之后,WebP 还是可以减少 28% 的文件大小。
我们希望能够将webp格式的图片转化为png格式。因此,我们需要在Linux系统中安装webp软件,安装的方式如下:
- Ubuntu: sudo apt-get install webp
- CentOs: yum -y install libwebp-devel libwebp-tools
安装完后,通过以下命令就可以讲webp格式的图片转化为png格式了:
dwebp picture.webp -o picture.png
整个爬虫的思路就讲完了,我们利用多线程进行下载图片以及图片格式转换的操作,完整的Python代码如下(需要事先安装webp, 以及保存目录需要设置好):
# -*- coding: utf-8 -*-
import urllib.request
import os
import time
from concurrent.futures import ThreadPoolExecutor, wait, ALL_COMPLETED
global COUNT # 下载失败的图片张数
COUNT = 0
# 参数:
# dir: 图片保存的目录
# juanshu_num: 卷数
# page: 页数
# 此函数的作用: 下载特定卷的特定页的图片到指定的保存目录
def get_webp(dir, juanshu_num, page):
# 拼接下载的图片的网址
base_url = 'https://mhpic.samanlehua.com/comic/Z%2F'
name = urllib.parse.quote('足球小将翼')
juanshu = '0'+str(juanshu_num) if juanshu_num<10 else str(juanshu_num)
juanshu = urllib.parse.quote('第%s卷'%juanshu)
format = '.jpg-noresize.webp'
url = base_url+name+'%2F'+juanshu+'%2F'+str(page)+format
# print(url)
try:
urllib.request.urlretrieve(url, '%s/%d.webp'%(dir, page)) # 下载图片
print('开始转化图片格式:')
os.system('dwebp %s/%d.webp -o %s/%d.png'%(dir, page, dir, page)) # 将图片由webp格式转化为png格式
print('转化图片格式完毕。')
os.system('rm -rf %s/%d.webp'%(dir, page)) # 删除webp格式的图片
except Exception as err:
print(err)
# 参数:juanshu_num: 卷数
# page_num: 该卷的图片张数
# 此函数的作用: 下载某一卷中的所有图片
def download(juanshu_num, page_num):
# 如果目录不存在,则新建这个目录
if not os.path.exists('/home/tsubasa/卷%s'%juanshu_num):
os.mkdir('/home/tsubasa/卷%s'%juanshu_num)
dir = '/home/tsubasa/卷%s'%juanshu_num
# 下载每一卷中的所有图片
for page in range(1, page_num+1):
try:
get_webp(dir, juanshu_num, page)
except urllib.error.HTTPError:
print('该图片不存在或者网络连接错误。')
COUNT += 1
def main():
start_time = time.time()
# 每一卷的图片张数, 一共21卷
page_num_list = [175, 175, 165, 171, 169, 172, 170, 170, 168, 174, 171,
168, 168, 168, 176, 169, 171, 167, 166, 172, 172]
# 设置线程个数为10个
executor = ThreadPoolExecutor(max_workers=10) # 可以自己调整max_workers
# submit()的参数: 第一个为函数, 之后为该函数的传入参数,允许有多个
# 并发下载图片
future_tasks = [executor.submit(download, juanshu_num+1, page_num)
for juanshu_num,page_num in enumerate(page_num_list)]
wait(future_tasks, return_when=ALL_COMPLETED) # 等待所有的任务结束
end_time = time.time()
print('图片下载完毕!一共耗时%s秒。'%(end_time-start_time))
print('下载失败的图片张数为:%d'%COUNT)
main()
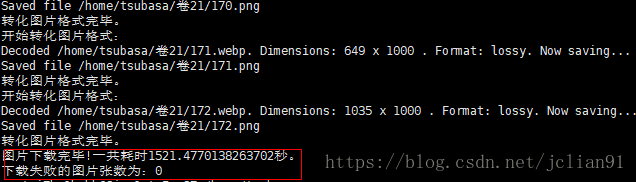
运行以上程序,静静地等待程序运行完毕,输出的结果如下:
我们再去Linux中查看已经下好的图片:
{kind=link}
一共下载了3577张图片(没有一张下载失败),用了约1521秒,效率杠杠的,哈哈~~
本文到此就要结束了,最后再加一句:中国足球,加油啊!
注意:本人现已开通两个微信公众号: 因为Python(微信号为:python_math)以及轻松学会Python爬虫(微信号为:easy_web_scrape), 欢迎大家关注哦~~
Python爬虫之足球小将动漫(图片)下载的更多相关文章
- python爬虫实战(3)--图片下载器
本篇目标 1.输入关键字能够根据关键字爬取百度图片 2.能够将图片保存到本地文件夹 1.URL的格式 进入百度图片搜索apple,这时显示的是瀑布流版本,我们选择传统翻页版本进行爬取.可以看到网址为: ...
- 使用Python爬虫爬取网络美女图片
代码地址如下:http://www.demodashi.com/demo/13500.html 准备工作 安装python3.6 略 安装requests库(用于请求静态页面) pip install ...
- Python爬虫+颜值打分,5000+图片找到你的Mrs. Right
一见钟情钟的不是情,是脸 日久生情生的不是脸,是情 项目简介 本项目利用Python爬虫和百度人脸识别API,针对简书交友专栏,爬取用户照片(侵删),并进行打分. 本项目包括以下内容: 图片爬 ...
- Python爬虫入门教程: 27270图片爬取
今天继续爬取一个网站,http://www.27270.com/ent/meinvtupian/ 这个网站具备反爬,so我们下载的代码有些地方处理的也不是很到位,大家重点学习思路,有啥建议可以在评论的 ...
- (8)分布式下的爬虫Scrapy应该如何做-图片下载(源码放送)
转载主注明出处:http://www.cnblogs.com/codefish/p/4968260.html 在爬虫中,我们遇到比较多需求就是文件下载以及图片下载,在其它的语言或者框架中,我们可能 ...
- Python爬虫入门教程 8-100 蜂鸟网图片爬取之三
蜂鸟网图片--啰嗦两句 前几天的教程内容量都比较大,今天写一个相对简单的,爬取的还是蜂鸟,依旧采用aiohttp 希望你喜欢 爬取页面https://tu.fengniao.com/15/ 本篇教程还 ...
- Python爬虫入门教程 7-100 蜂鸟网图片爬取之二
蜂鸟网图片--简介 今天玩点新鲜的,使用一个新库 aiohttp ,利用它提高咱爬虫的爬取速度. 安装模块常规套路 pip install aiohttp 运行之后等待,安装完毕,想要深造,那么官方文 ...
- Python爬虫入门教程 5-100 27270图片爬取
27270图片----获取待爬取页面 今天继续爬取一个网站,http://www.27270.com/ent/meinvtupian/ 这个网站具备反爬,so我们下载的代码有些地方处理的也不是很到位, ...
- python爬虫——爬取NUS-WIDE数据库图片
实验室需要NUS-WIDE数据库中的原图,数据集的地址为http://lms.comp.nus.edu.sg/research/NUS-WIDE.htm 由于这个数据只给了每个图片的URL,所以需 ...
随机推荐
- extjs__(grid Panel绑定数据)
1.修改面板名称 双击My Panel 就可以进行修改 2拖入一个grid panel绑定数据 3.创建一个model 只是为了创建一个模型 相当于java中的模型层 只是数据的一个标准 4 ...
- git安装以及初始化
安装文档参见:https://www.cnblogs.com/ximiaomiao/p/7140456.html 注意:安装成功后,用cmd进行基本信息设置时,当出现“git不是内部或外部命令,也不是 ...
- java 判断用户是PC端和还是APP端登陆
java 判断用户是PC端和还是APP端登陆 public void getRequestHeader(HttpServletRequest request){ // 从浏览器获取请求头信息 Stri ...
- Batch_Size 详解
Batch_Size(批尺寸)是机器学习中一个重要参数,涉及诸多矛盾,下面逐一展开. 首先,为什么需要有 Batch_Size 这个参数? Batch 的选择,首先决定的是下降的方向.如果数据集比较小 ...
- C#常用工具类——Excel操作类(ZT)
本文转载于: http://www.cnblogs.com/zfanlong1314/p/3916047.html /// 常用工具类——Excel操作类 /// <para> ----- ...
- 吴恩达机器学习笔记15-假设陈述(Hypothesis Representation)
在分类问题中,要用什么样的函数来表示我们的假设呢?此前说过,希望我们的分类器的输出值在0 和1 之间,因 此,我们希望想出一个满足某个性质的假设函数,这个性质是它的预测值要在0 和1 之间.回顾在一开 ...
- 微信小程序支付接入实战
1. 微信小程序支付接入实战 1.1. 需求 最近接到一个小程序微信支付的需求,需要我写后台支持,本着能不自己写就不自己写的cv原则,在网上找到了些第三方程序,经过尝试后,最后决定了这不要脸作者的 ...
- core跨域问题
#region 跨域问题 app.UseCors(builder => builder .AllowAnyOrigin() .AllowAnyMethod() .AllowAnyHeader() ...
- 使用Json封装scroll,已处理其兼容性问题
scroll.js /* 使用Json封装scroll */ function scroll(){ //标准模式(遵循W3C标准) if(pageYOffset!==null){ return { t ...
- Connect By
connect by 用于存在父子,祖孙,上下级等层级关系的数据表进行层级查询. 语法格式: { CONNECT BY [ NOCYCLE ] condition [AND condition]... ...