[大数据之Yarn]——资源调度浅学
在hadoop生态越来越完善的背景下,集群多用户租用的场景变得越来越普遍,多用户任务下的资源调度就显得十分关键了。比如,一个公司拥有一个几十个节点的hadoop集群,a项目组要进行一个计算任务,b项目组要计算一个任务,集群到底先执行哪个任务?如果你需要提交1000个任务呢?这些任务又是如何执行的?
为了解决上面的问题,就需要在hadoop集群中引入资源管理和任务调度的框架。这就是——Yarn。
YARN的发展
Yarn在第一代的时候,框架跟hdfs差不多。一个主节点jobtracker,用来分配任务和监控任务运行情况;多个从节点tasktracker,用来执行真正的计算。

这种方式还是有一定的弊端的:
- tasktracker出现故障,会导致整个任务计算失败。
- jobtracker压力过大,既要负责全局的任务分配,还需要时刻与tasktracker沟通。
因此,就出现了第二代的YARN。

这种模式主要的特点,就是两个地方:
jobtracker被分离为两个角色,一个是resourcemanager,简称RM,仅仅负责任务的调度和应用的管理;一个是applicationmaster,简称AM,每个应用任务都会创建一个AM,用于申请任务需要的资源并且监控任务运行状况。
YARN资源调度流程
YARN的资源调度可以看官网提供的图片:
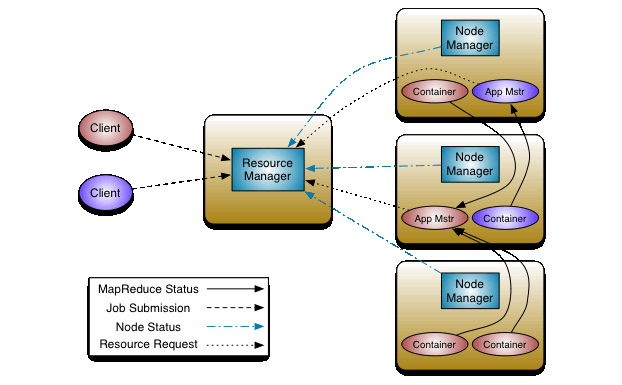
流程大致如下:
- client客户端向yarn集群(resourcemanager)提交任务
- resourcemanager选择一个node创建appmaster
- appmaster根据任务向rm申请资源
- rm返回资源申请的结果
- appmaster去对应的node上创建任务需要的资源(container形式,包括内存和CPU)
- appmaster负责与nodemanager进行沟通,监控任务运行
- 最后任务运行成功,汇总结果。
其中Resourcemanager里面一个很重要的东西,就是调度器Scheduler,调度规则可以使用官方提供的,也可以自定义。
官方大概提供了三种模式:
- FIFO,最简单的先进先出,按照用户提交任务的顺序执行。这种方式最简单,但是也一大堆问题,比如任务可能独占资源,导致其他任务饿死等。
- Capacity,采用队列的概念,任务提交到队列,队列可以设置资源的占比,并且支持层级队列、访问控制、用户限制、预定等等高级的玩法。
- Fair share,基于用户或者应用去平分资源,灵活分配。
capacity和fair share都是采用队列的模式,队列内部基本上还是FIFO。并且同级的队列任务,如果一个队列是空闲的,那么另一个队列任务可以使用资源;如果这个队列又提交了任务,则会抢占或者等待资源释放,直到资源到达预定的分配比例。
总的来说,YARN的资源调度还是比较完善的。
参考
[大数据之Yarn]——资源调度浅学的更多相关文章
- 月薪3万+的大数据人都在疯学Flink,为什么?
身处大数据圈近5年了,在我的概念里一直认为大数据最牛的两个东西是Hadoop和Spark.18年下半年的时候,我突然发现身边很多大数据牛人都是研究学习Flink,甚至连Spark都大有被冷落抛弃的感觉 ...
- 大数据之Yarn——Capacity调度器概念以及配置
试想一下,你现在所在的公司有一个hadoop的集群.但是A项目组经常做一些定时的BI报表,B项目组则经常使用一些软件做一些临时需求.那么他们肯定会遇到同时提交任务的场景,这个时候到底如何分配资源满足这 ...
- 入门大数据---通过Yarn搭建MapReduce和应用实例
上一篇中我们了解了MapReduce和Yarn的基本概念,接下来带领大家搭建下Mapreduce-HA的框架. 结构图如下: 开始搭建: 一.配置环境 注:可以现在一台计算机上进行配置,然后分发给其它 ...
- 大数据框架-YARN
YARN(Yet Another Resource Negotiator): 是一种新的 Hadoop 资源管理器 [ResourceManager:纯粹的调度器,基于应用程序对资源的需求进行调度的, ...
- 大数据学习——yarn集群启动
启动yarn命令: start-yarn.sh 验证是否启动成功 jps查看进程 http://192.168.74.100:8088页面 关闭 stop-yarn.sh
- 大数据之 Spark
1 渊源 于2009由Matei Zaharia创立了spark大数据处理和计算框架,基于内存,用scala编写. 2 部署 2.1 需要软件包 下载路径见已有博文 Jdk ——因为运行环境为jvm ...
- 参加2013中国大数据技术大会(BDTC2013)
2013年12月5日-6日参加了为期两天的2013中国大数据技术大会(Big Data Technology Conference, BDTC2013),本期会议主题是:“应用驱动的架构与技术 ”.大 ...
- 大数据作业之利用MapRedeuce实现简单的数据操作
Map/Reduce编程作业 现有student.txt和student_score.txt.将两个文件上传到hdfs上.使用Map/Reduce框架完成下面的题目 student.txt 20160 ...
- 坐实大数据资源调度框架之王,Yarn为何这么牛
摘要:Yarn的出现伴随着Hadoop的发展,使Hadoop从一个单一的大数据计算引擎,成为大数据的代名词. 本文分享自华为云社区<Yarn为何能坐实资源调度框架之王?>,作者: Java ...
随机推荐
- Entity Framework Core 1.1 升级通告
原文地址:https://blogs.msdn.microsoft.com/dotnet/2016/11/16/announcing-entity-framework-core-1-1/ 翻译:杨晓东 ...
- Java 征途:行者的地图
前段时间应因缘梳理了下自己的 Java 知识体系, 成文一篇望能帮到即将走进或正在 Java 世界跋涉的程序员们. 第一张,基础图 大约在 2003 年我开始知道 Java 的(当时还在用 Delph ...
- ABP文档 - 本地化
文档目录 本节内容: 简介 应用语言 本地化源 XML文件 注册XML本地化源 JSOn文件 注册JSON本地化源 资源文件 自定义源 获取一个本地文本 在服务端 在MVc控制器里 在MVC视图里 在 ...
- myeclipse学习总结一(在MyEclipse中设置生成jsp页面时默认编码为utf-8编码)
1.每次我们在MyEclispe中创建Jsp页面,生成的Jsp页面的默认编码是"ISO-8859-1".在这种情况下,当我们在页面中编写的内容存在中文的时候,就无法进行保存.如下图 ...
- 最长回文子串-LeetCode 5 Longest Palindromic Substring
题目描述 Given a string S, find the longest palindromic substring in S. You may assume that the maximum ...
- 深入浅出JavaScript之原型链&继承
Javascript语言的继承机制,它没有"子类"和"父类"的概念,也没有"类"(class)和"实例"(instanc ...
- 在.NET Core之前,实现.Net跨平台之Mono+CentOS+Jexus初体验
准备工作 本篇文章采用Mono+CentOS+Jexus的方式实现部署.Net的Web应用程序(实战,上线项目). 不懂Mono的请移步张善友大神的:国内 Mono 相关文章汇总 不懂Jexus为何物 ...
- R abalone data set
#鲍鱼数据集aburl <- 'http://archive.ics.uci.edu/ml/machine-learning-databases/abalone/abalone.data' ab ...
- QT内省机制、自定义Model、数据库
本文将介绍自定义Model过程中数据库数据源的获取方法,我使用过以下三种方式获取数据库数据源: 创建 存储对应数据库所有字段的 结构体,将结构体置于容器中返回,然后根据索引值(QModelIndex) ...
- Redis配置文件redis.conf
1.地址 2.Units单位 1 配置大小单位,开头定义了一些基本的度量单位,只支持bytes,不支持bit 2 对大小写不敏感 3.includes包含