CSharpGL(22)实现顺序无关的半透明渲染(Order-Independent-Transparency)
CSharpGL(22)实现顺序无关的半透明渲染(Order-Independent-Transparency)
在 GL.Enable(GL_BLEND); 后渲染半透明物体时,由于顶点被渲染的顺序固定,渲染出来的结果往往很奇怪。红宝书里提到一个OIT(Order-Independent-Transparency)的渲染方法,很好的解决了这个问题。这个功能太有用了。于是我把这个方法加入CSharpGL中。
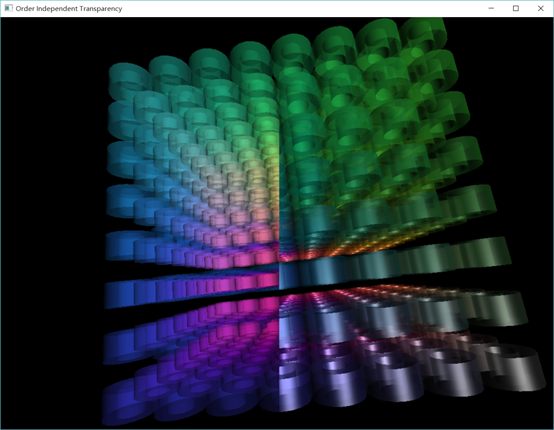
效果图
如下图所示,左边是常见的blend方法,右边是OIT渲染的结果。可以看到左边的渲染结果有些诡异,右边的就正常了。

网络允许的话可以看一下视频,更直观。
或者也可以看红宝书里的例子:左边是常见的blend方法,右边是OIT渲染的结果。
下载
CSharpGL已在GitHub开源,欢迎对OpenGL有兴趣的同学加入(https://github.com/bitzhuwei/CSharpGL)
实现原理
源头
为什么通常的blend方式会有问题?因为blend的结果是与source、dest两个颜色的出现顺序相关的。就是说blend(blend(ColorA, ColorB), ColorC)≠blend(ColorA,blend(ColorB, ColorC))。
那么很显然的一个想法是,分两遍渲染,第一遍:把这个位置上的所有Color都存到一个链表里,第二遍:根据每个Color的深度值进行排序,然后进行blend操作。这就解决了blend顺序的问题。
W*H个链表
显然,为了对宽度、高度分别为Width、Height的窗口实施OIT渲染,必须为此窗口上的每个像素分别设置一个链表,用于存储投影到此像素上的各个Color。这就是W*H个链表的由来。
当然了,这个链表要由GLSL shader来操作 。shader本身似乎没有操作链表的功能。那么就用一个大大的VBO来代替。这个VBO存储了所有的W*H个链表。

你可以想象,在第一遍渲染时,这个VBO的第二个位置上可能是第一个像素的第二个Color,也可能是第二个像素的第一个Color。这就意味着我们还需要一个数组来存放W*H个链表的头结点。这个数组我们用一个2DTexture实现,其大小正好等于Width*Height就可以了。
★这个Texture不像一般的Texture那样用于给模型贴图,而是用作记录头结点的信息。★
初始化
初始化工作主要包含这几项:创建和清空头结点Texture、链表VBO。
protected override void DoInitialize()
{
// Create head pointer texture
GL.GetDelegateFor<GL.glActiveTexture>()(GL.GL_TEXTURE0);
GL.GenTextures(, head_pointer_texture);
GL.BindTexture(GL.GL_TEXTURE_2D, head_pointer_texture[]);
GL.TexParameteri(GL.GL_TEXTURE_2D, GL.GL_TEXTURE_MIN_FILTER, (int)GL.GL_NEAREST);
GL.TexParameteri(GL.GL_TEXTURE_2D, GL.GL_TEXTURE_MAG_FILTER, (int)GL.GL_NEAREST);
GL.TexImage2D(GL.GL_TEXTURE_2D, , GL.GL_R32UI, MAX_FRAMEBUFFER_WIDTH, MAX_FRAMEBUFFER_HEIGHT, , GL.GL_RED_INTEGER, GL.GL_UNSIGNED_INT, IntPtr.Zero);
GL.BindTexture(GL.GL_TEXTURE_2D, ); GL.GetDelegateFor<GL.glBindImageTexture>()(, head_pointer_texture[], , true, , GL.GL_READ_WRITE, GL.GL_R32UI); // Create buffer for clearing the head pointer texture
GL.GetDelegateFor<GL.glGenBuffers>()(, head_pointer_clear_buffer);
GL.BindBuffer(BufferTarget.PixelUnpackBuffer, head_pointer_clear_buffer[]);
GL.GetDelegateFor<GL.glBufferData>()(GL.GL_PIXEL_UNPACK_BUFFER, MAX_FRAMEBUFFER_WIDTH * MAX_FRAMEBUFFER_HEIGHT * sizeof(uint), IntPtr.Zero, GL.GL_STATIC_DRAW);
IntPtr data = GL.MapBuffer(BufferTarget.PixelUnpackBuffer, MapBufferAccess.WriteOnly);
unsafe
{
var array = (uint*)data.ToPointer();
for (int i = ; i < MAX_FRAMEBUFFER_WIDTH * MAX_FRAMEBUFFER_HEIGHT; i++)
{
array[i] = ;
}
}
GL.UnmapBuffer(BufferTarget.PixelUnpackBuffer);
GL.BindBuffer(BufferTarget.PixelUnpackBuffer, ); // Create the atomic counter buffer
GL.GetDelegateFor<GL.glGenBuffers>()(, atomic_counter_buffer);
GL.BindBuffer(BufferTarget.AtomicCounterBuffer, atomic_counter_buffer[]);
GL.GetDelegateFor<GL.glBufferData>()(GL.GL_ATOMIC_COUNTER_BUFFER, sizeof(uint), IntPtr.Zero, GL.GL_DYNAMIC_COPY);
GL.BindBuffer(BufferTarget.AtomicCounterBuffer, ); // Create the linked list storage buffer
GL.GetDelegateFor<GL.glGenBuffers>()(, linked_list_buffer);
GL.BindBuffer(BufferTarget.TextureBuffer, linked_list_buffer[]);
GL.GetDelegateFor<GL.glBufferData>()(GL.GL_TEXTURE_BUFFER, MAX_FRAMEBUFFER_WIDTH * MAX_FRAMEBUFFER_HEIGHT * * Marshal.SizeOf(typeof(vec4)), IntPtr.Zero, GL.GL_DYNAMIC_COPY);
GL.BindBuffer(BufferTarget.TextureBuffer, ); // Bind it to a texture (for use as a TBO)
GL.GenTextures(, linked_list_texture);
GL.BindTexture(GL.GL_TEXTURE_BUFFER, linked_list_texture[]);
GL.GetDelegateFor<GL.glTexBuffer>()(GL.GL_TEXTURE_BUFFER, GL.GL_RGBA32UI, linked_list_buffer[]);
GL.BindTexture(GL.GL_TEXTURE_BUFFER, ); GL.GetDelegateFor<GL.glBindImageTexture>()(, linked_list_texture[], , false, , GL.GL_WRITE_ONLY, GL.GL_RGBA32UI); GL.ClearDepth(1.0f);
}
DoInitialize
2遍渲染
渲染过程主要有3步:重置链表、头结点、计数器等;1遍渲染填充链表;2遍渲染排序+blend。
protected override void DoRender(RenderEventArgs arg)
{
this.depthTestSwitch.On();
this.cullFaceSwitch.On(); // Reset atomic counter
GL.GetDelegateFor<GL.glBindBufferBase>()(GL.GL_ATOMIC_COUNTER_BUFFER, , atomic_counter_buffer[]);
IntPtr data = GL.MapBuffer(BufferTarget.AtomicCounterBuffer, MapBufferAccess.WriteOnly);
unsafe
{
var array = (uint*)data.ToPointer();
array[] = ;
}
GL.UnmapBuffer(BufferTarget.AtomicCounterBuffer);
GL.GetDelegateFor<GL.glBindBufferBase>()(GL.GL_ATOMIC_COUNTER_BUFFER, , ); // Clear head-pointer image
GL.BindBuffer(BufferTarget.PixelUnpackBuffer, head_pointer_clear_buffer[]);
GL.BindTexture(GL.GL_TEXTURE_2D, head_pointer_texture[]);
GL.TexSubImage2D(TexSubImage2DTarget.Texture2D, , , , arg.CanvasRect.Width, arg.CanvasRect.Height, TexSubImage2DFormats.RedInteger, TexSubImage2DType.UnsignedByte, IntPtr.Zero);
GL.BindTexture(GL.GL_TEXTURE_2D, );
GL.BindBuffer(BufferTarget.PixelUnpackBuffer, );
// // Bind head-pointer image for read-write
GL.GetDelegateFor<GL.glBindImageTexture>()(, head_pointer_texture[], , false, , GL.GL_READ_WRITE, GL.GL_R32UI); // Bind linked-list buffer for write
GL.GetDelegateFor<GL.glBindImageTexture>()(, linked_list_texture[], , false, , GL.GL_WRITE_ONLY, GL.GL_RGBA32UI); mat4 model = mat4.identity();
mat4 view = arg.Camera.GetViewMat4();
mat4 projection = arg.Camera.GetProjectionMat4();
this.buildListsRenderer.SetUniformValue("model_matrix", model);
this.buildListsRenderer.SetUniformValue("view_matrix", view);
this.buildListsRenderer.SetUniformValue("projection_matrix", projection);
this.resolve_lists.SetUniformValue("model_matrix", model);
this.resolve_lists.SetUniformValue("view_matrix", view);
this.resolve_lists.SetUniformValue("projection_matrix", projection); // first pass
this.buildListsRenderer.Render(arg);
// second pass
this.resolve_lists.Render(arg); GL.GetDelegateFor<GL.glBindImageTexture>()(, , , false, , GL.GL_WRITE_ONLY, GL.GL_RGBA32UI);
GL.GetDelegateFor<GL.glBindImageTexture>()(, , , false, , GL.GL_READ_WRITE, GL.GL_R32UI); this.cullFaceSwitch.Off();
this.depthTestSwitch.Off();
}
protected override void DoRender(RenderEventArgs arg)
Shader:填充链表
1遍渲染时,用一个fragment shader来填充链表:
#version core layout (early_fragment_tests) in; layout (binding = , r32ui) uniform uimage2D head_pointer_image;
layout (binding = , rgba32ui) uniform writeonly uimageBuffer list_buffer; layout (binding = , offset = ) uniform atomic_uint list_counter; layout (location = ) out vec4 color; in vec4 surface_color; uniform vec3 light_position = vec3(40.0, 20.0, 100.0); void main(void)
{
uint index;
uint old_head;
uvec4 item; index = atomicCounterIncrement(list_counter); old_head = imageAtomicExchange(head_pointer_image, ivec2(gl_FragCoord.xy), uint(index)); item.x = old_head;
item.y = packUnorm4x8(surface_color);
item.z = floatBitsToUint(gl_FragCoord.z);
item.w = / ; imageStore(list_buffer, int(index), item); color = surface_color;
}
Shader:排序、blend
2遍渲染时,用另一个fragment shader来排序和blend。
#version core /*
* OpenGL Programming Guide - Order Independent Transparency Example
*
* This is the resolve shader for order independent transparency.
*/ // The per-pixel image containing the head pointers
layout (binding = , r32ui) uniform uimage2D head_pointer_image;
// Buffer containing linked lists of fragments
layout (binding = , rgba32ui) uniform uimageBuffer list_buffer; // This is the output color
layout (location = ) out vec4 color; // This is the maximum number of overlapping fragments allowed
#define MAX_FRAGMENTS 40 // Temporary array used for sorting fragments
uvec4 fragment_list[MAX_FRAGMENTS]; void main(void)
{
uint current_index;
uint fragment_count = ; current_index = imageLoad(head_pointer_image, ivec2(gl_FragCoord).xy).x; while (current_index != && fragment_count < MAX_FRAGMENTS)
{
uvec4 fragment = imageLoad(list_buffer, int(current_index));
fragment_list[fragment_count] = fragment;
current_index = fragment.x;
fragment_count++;
} uint i, j; if (fragment_count > )
{ for (i = ; i < fragment_count - ; i++)
{
for (j = i + ; j < fragment_count; j++)
{
uvec4 fragment1 = fragment_list[i];
uvec4 fragment2 = fragment_list[j]; float depth1 = uintBitsToFloat(fragment1.z);
float depth2 = uintBitsToFloat(fragment2.z); if (depth1 < depth2)
{
fragment_list[i] = fragment2;
fragment_list[j] = fragment1;
}
}
} } vec4 final_color = vec4(0.0); for (i = ; i < fragment_count; i++)
{
vec4 modulator = unpackUnorm4x8(fragment_list[i].y); final_color = mix(final_color, modulator, modulator.a + fragment_list[i].w / );
} color = final_color;
// color = vec4(float(fragment_count) / float(MAX_FRAGMENTS));
}
resolve_lists.frag
总结
经过这个OIT问题的练习,我忽然明白了一些modern opengl的设计思想。
在modern opengl看来,Texture虽然名为Texture,告诉我们它是用于给模型贴图的,但是,Texture实际上可以用作各种各样的事(例如OIT里用作记录各个头结点)。
一个VBO不仅仅可以用于存储顶点位置、法线、颜色等信息,也可以用作各种各样的事(例如OIT里用作存储W*H个链表,这让我想起了我的(小型单文件NoSQL数据库SharpFileDB)里的文件链表,两者何其相似)。
为什么会这样?
因为modern opengl是用GLSL shader来实施渲染的。Shader是一段程序,程序的创造力是无穷无尽的,你可以以任何方式使用opengl提供的资源(Texture,VBO等等)。唯一固定不变的,就是modern opengl的渲染管道(pipeline,"管道"太玄幻了,其实就是渲染过程的意思)。
记住pipeline的工作流程,认识opengl的各种资源,发挥想象力。
2遍渲染的成功试验,从侧面印证了上述推断,也说明了opengl只是负责渲染,至于渲染之后是不是画到画布或者其他什么地方,都是可以控制的。
甚至,“渲染”的目的本就不必是为了画图。这就是compute shader的由来了吧。
原CSharpGL的其他功能(3ds解析器、TTF2Bmp、CSSL等),我将逐步加入新CSharpGL。
欢迎对OpenGL有兴趣的同学关注(https://github.com/bitzhuwei/CSharpGL)
CSharpGL(22)实现顺序无关的半透明渲染(Order-Independent-Transparency)的更多相关文章
- Single Depth peeling 顺序无关渲染(OIT)
什么是顺序无关渲染 在3D渲染中,物体的渲染是按一定的顺序渲染的,这也就可能导致半透明的物体先于不透明的物体渲染,结果就是可能出现半透明物体后的物体由于深度遮挡而没有渲染出来.对于这种情况通常会先渲染 ...
- CSharpGL(40)一种极其简单的半透明渲染方法
CSharpGL(40)一种极其简单的半透明渲染方法 开始 这里介绍一个实现半透明渲染效果的方法.此方法极其简单,不拖累渲染速度,但是不能适用所有的情况. 如下图所示,可以让包围盒显示为半透明效果. ...
- DirectX11 With Windows SDK--29 计算着色器:内存模型、线程同步;实现顺序无关透明度(OIT)
前言 由于透明混合在不同的绘制顺序下结果会不同,这就要求绘制前要对物体进行排序,然后再从后往前渲染.但即便是仅渲染一个物体(如上一章的水波),也会出现透明绘制顺序不对的情况,普通的绘制是无法避免的.如 ...
- CSharpGL(25)一个用raycast实现体渲染VolumeRender的例子
CSharpGL(25)一个用raycast实现体渲染VolumeRender的例子 本文涉及的VolumeRendering相关的C#代码是从(https://github.com/toolchai ...
- sqlmap映射继承机制及映射字段顺序与SQL查询字段顺序无关
<typeAlias alias="TblSpPartsinfo" type="com.bn.car.biz.supply.dao.po.PartsInfoPO&q ...
- thead、tbody、tfoot与顺序无关
今天发现一个问题,thead.tbody.tfoot等标签的内容排版与顺序无关,做了一个小的实验:
- python---方法解析顺序MRO(Method Resolution Order)<以及解决类中super方法>
MRO了解: 对于支持继承的编程语言来说,其方法(属性)可能定义在当前类,也可能来自于基类,所以在方法调用时就需要对当前类和基类进行搜索以确定方法所在的位置.而搜索的顺序就是所谓的「方法解析顺序」(M ...
- 【转】python---方法解析顺序MRO(Method Resolution Order)<以及解决类中super方法>
[转]python---方法解析顺序MRO(Method Resolution Order)<以及解决类中super方法> MRO了解: 对于支持继承的编程语言来说,其方法(属性)可能定义 ...
- 字节顺序标记——BOM,Byte Order Mark
定义 BOM(Byte Order Mark),字节顺序标记,出现在文本文件头部,Unicode编码标准中用于标识文件是采用哪种格式的编码. 介绍 UTF-8 不需要 BOM,尽管 Unico ...
随机推荐
- 【前端性能】高性能滚动 scroll 及页面渲染优化
最近在研究页面渲染及web动画的性能问题,以及拜读<CSS SECRET>(CSS揭秘)这本大作. 本文主要想谈谈页面优化之滚动优化. 主要内容包括了为何需要优化滚动事件,滚动与页面渲染的 ...
- mysql学习之 sql语句的技巧及优化
一.sql中使用正则表达式 select name,email from user where email Regexp "@163[.,]com$"; sql语句中使用Regex ...
- javascript之Object.defineProperty的奥妙
直切主题 今天遇到一个这样的功能: 写一个函数,该函数传递两个参数,第一个参数为返回对象的总数据量,第二个参数为初始化对象的数据.如: var o = obj (4, {name: 'xu', age ...
- JavaScript模仿块级作用域
avaScript 没有块级作用域的概念.这意味着在块语句中定义的变量,实际上是在包含函数中而非语句中创建的,来看下面的例子: function outputNumbers(count){ for ( ...
- Android Notification 详解——基本操作
Android Notification 详解 版权声明:本文为博主原创文章,未经博主允许不得转载. 前几天项目中有用到 Android 通知相关的内容,索性把 Android Notificatio ...
- Linux常用指令指南,终端装逼利器
最近搞了台Macbook Pro,就学习了一下Linux命令,在网上查了些资料,看了本书叫<快乐的 Linux 命令行>,里面涉及到了各个方面的命令. 在此将常用的整理出来,以备将来使用. ...
- 【开源毕设】一款精美的家校互动APP分享——爱吖校推 [你关注的,我们才推](持续开源更新3)附高效动态压缩Bitmap
一.写在前面 爱吖校推如同它的名字一样,是一款校园类信息推送交流平台,这么多的家校互动类软件,你选择了我,这是我的幸运.从第一次在博客园上写博客到现在,我一次一次地提高博文的质量和代码的可读性,都是为 ...
- Android如何制作漂亮的自适布局的键盘
最近做了个自定义键盘,但面对不同分辨率的机型其中数字键盘不能根据界面大小自已铺满,但又不能每种机型都做一套吧,所以要做成自适应,那这里主讲思路. 这里最上面的titlebar高度固定,下面输入的金额高 ...
- 高德地图api实现地址和经纬度的转换(python)
利用高德地图web服务api实现地理/逆地址编码 api使用具体方法请查看官方文档 文档网址:http://lbs.amap.com/api/webservice/guide/api/georegeo ...
- Python 基础之一变量和赋值
变量:程序在运行的时候会用到很多临时存储数据,这个时候就用到了变量,临时数据的名字. Python中变量不需要声明,直接可以使用,变量的数据类型由赋值确定. >>> name=&qu ...