基于superagent 与 cheerio 的node简单爬虫
最近重新玩起了node,便总结下基本的东西,在本文中通过node的superagent与cheerio来抓取分析网页的数据。
目的
superagent 抓取网页
cheerio 分析网页
准备
Node(我的6.0)
三个依赖, express(4X),superagent 和 cheerio。
文档参考
superagent(http://visionmedia.github.io/superagent/ ) 是个 http 方面的库,可以发起 get 或 post 请求。
cheerio(https://github.com/cheeriojs/cheerio )为服务器特别定制的,快速、灵活、实施的jQuery. 用来从网页中以 css selector 取数据,使用方式跟 jquery 一样。
代码
那么我将抓取自己博客的数据。(有兴趣的朋友可以锦上添花一下,用正则筛选阅读数不少于400的文章.)
var express = require('express');
var superagent = require('superagent');
var cheerio = require('cheerio');
var app = express();
app.get('/', function (req, res, next) {
superagent.get('http://www.cnblogs.com/LIUYANZUO')
.end(function (err, sres) {
if (err) {
return next(err);
}
// sres.text 里面存储着网页的 html 内容,将它传给 cheerio.load 之后
// 就可以得到一个实现了 jquery 接口的变量,我们习惯性地将它命名为 `$`
// 剩下就都是 jquery 的内容了
var $ = cheerio.load(sres.text);
var items = [];
$('.day .postTitle2').each(function (index, element) {
var $element = $(element);
items.push({
标题: $element.text(),
网址: $element.attr('href')
});
});
res.send(items);
});
});
app.listen(4000, function () {
console.log('app is listenling at port 4000');
});
在命令行运行,得到截图
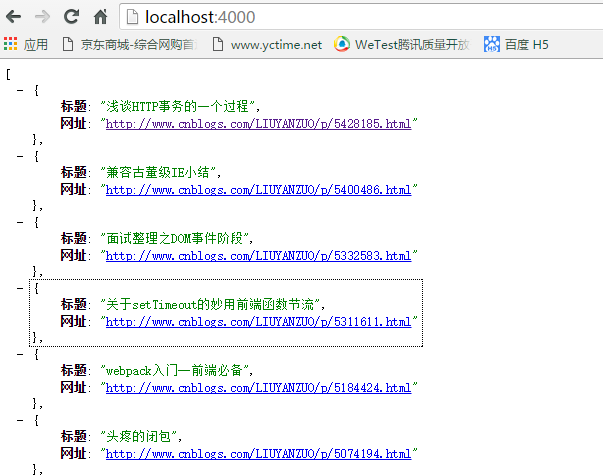
当然这是最简单的,下一篇我想介绍下node的异步并发。
基于superagent 与 cheerio 的node简单爬虫的更多相关文章
- 手把手教你学node.js之使用 superagent 与 cheerio 完成简单爬虫
使用 superagent 与 cheerio 完成简单爬虫 目标 建立一个 lesson 3 项目,在其中编写代码. 当在浏览器中访问 http://localhost:3000/ 时,输出 CNo ...
- nodejs爬虫初试---superagent和cheerio
前言 早就听过爬虫,这几天开始学习nodejs,写了个爬虫 demo ,爬取 博客园首页的文章标题.用户名.阅读数.推荐数和用户头像,现做个小总结. 使用到这几个点: 1.node的核心模块-- 文件 ...
- node的简单爬虫
最近在学node,这里简单记录一下. 首先是在linux的环境下,关于node的安装教程: https://github.com/alsotang/node-lessons/tree/master ...
- node 简单的爬虫
基于express爬虫, 1,node做爬虫的优势 首先说一下node做爬虫的优势 第一个就是他的驱动语言是JavaScript.JavaScript在nodejs诞生之前是运行在浏览器上的脚本语言, ...
- <node.js爬虫>制作教程
前言:最近想学习node.js,突然在网上看到基于node的爬虫制作教程,所以简单学习了一下,把这篇文章分享给同样初学node.js的朋友. 目标:爬取 http://tweixin.yueyishu ...
- 【原】小玩node+express爬虫-2
上周写了一个node+experss的爬虫小入门.今天继续来学习一下,写一个爬虫2.0版本. 这次我们不再爬博客园了,咋玩点新的,爬爬电影天堂.因为每个周末都会在电影天堂下载一部电影来看看. talk ...
- node:爬虫爬取网页图片
代码地址如下:http://www.demodashi.com/demo/13845.html 前言 周末自己在家闲着没事,刷着微信,玩着手机,发现自己的微信头像该换了,就去网上找了一下头像,看着图片 ...
- nodejs的简单爬虫
闲聊 好久没写博客了,前几天小颖在朋友的博客里看到了用nodejs的简单爬虫.所以小颖就自己试着做了个爬博客园数据的demo.嘻嘻...... 小颖最近养了条泰日天,自从养了我家 ...
- Node.js爬虫-爬取慕课网课程信息
第一次学习Node.js爬虫,所以这时一个简单的爬虫,Node.js的好处就是可以并发的执行 这个爬虫主要就是获取慕课网的课程信息,并把获得的信息存储到一个文件中,其中要用到cheerio库,它可以让 ...
随机推荐
- get_magic_quotes_gpc函数
magic_quotes_gpc函数在php中的作用是判断解析用户提示的数据,如包括有:post.get.cookie过来的数据增加转义字符“\”,以确保这些数据不会引起程序,特别是数据库语句因为特殊 ...
- java常见异常类图(分类了Error/RuntimeExecption、check Exception)
版权:欧初权 http://www.cnblogs.com/langtianya/p/4435537.html
- H2Database数据类型
数据类型 整数(INT) 布尔型(BOOLEAN) 微整数(TINYINT) 小整数(SMALLINT) 大整数(BIGINT) 标识符(IDENTITY) 货币数(DECIMAL) 双精度实数( ...
- “System.Transactions.Diagnostics.DiagnosticTrace”的类型初始值设定项引发异常[WCF]
未处理System.TypeInitializationException HResult=-2146233036 Message=“System.ServiceModel.Diagnostics ...
- ExtJS学习之路第四步:看源码,实战MessageBox
可以通过看MessageBox.js的源码来深入认识,记住它的主要用法.Ext.MessageBox是实用类,用于生成不同风格的消息框,它是Singleton(单例),别名Ext.Msg.注意Mess ...
- git 笔记- 概念
本文参考书中内容 http://cnpmjs.org/ 镜像文件 下载插件的镜像 可参考fis 对于任何一个文件,在Git 内都只有三 种状态:已提交(committed),已修改(modified) ...
- 第三方br查询工具害人不浅
第三方br查询工具害人不浅,查询的时候会大批量调用百度的数据库,为什么说是大批量查询呢? 首先是自己查询,心急的站长恨不得下一次刷新br时数值会有所提高,不是那么急的也会一天查一次或几天一次,记录网站 ...
- zstu.4022.旋转数阵(模拟)
旋转数阵 Time Limit: 1 Sec Memory Limit: 64 MB Submit: 1477 Solved: 102 Description 把1到n2的正整数从左上角开始由外层 ...
- PHP数组的交集array_intersect(),array_intersect_assoc(),array_inter_key()函数详解
求两个数组的交集问题可以使用 array_intersect(),array_inersect_assoc,array_intersect_key来实现,其中 array_intersect()函数是 ...
- 浅谈setTimeout函数和setInterval函数
前几天学了js,看到了两个非常有趣的函数,他们分别是setTimeout函数和setInterval函数,这两个函数能使网页呈现非常一些网页中比较常见的效果,比如说图片轮播,等一些非常好玩的效果.下面 ...