<node.js爬虫>制作教程
前言:最近想学习node.js,突然在网上看到基于node的爬虫制作教程,所以简单学习了一下,把这篇文章分享给同样初学node.js的朋友。
目标:爬取 http://tweixin.yueyishujia.com/webapp/build/html/ 网站的所有门店发型师的基本信息。
思路:访问上述网站,通过chrome浏览器的network对网页内容分析,找到获取各个门店发型师的接口,对参数及返回数据进行分析,遍历所有门店的所有发型师,直到遍历完毕,同事将信息存储到本地。
步骤一:安装node.js
下载并安装node,此步骤比较简单就不详细解释了,有问题的可以直接问一下度娘。
步骤二:建立工程
1)打开dos命令条,cd进入想要创建项目的路径(我将此项目直接放在了E盘,以下皆以此路径为例);
2)mkdir node (创建一个文件夹用来存放项目,我这里取名为node);
3)cd 进入名为node的文件夹,并执行npm init初始化工程(期间会让填写一些信息,我是直接回车的);
步骤三:创建爬取到的数据存放的文件夹
1)创建data文件夹用来存放发型师基本信息;
2)创建image文件夹用来存储发型师头像图片;
此时工程下文件如下:

步骤四:安装第三方依赖包(fs是内置模块,不需要单独安装)
1)npm install cheerio –save
2)npm install superagent –save
3)npm install async –save
4)npm install request –save
分别简单解释一下上面安装的依赖包:
cheerio:是nodejs的抓取页面模块,为服务器特别定制的,快速、灵活、实施的jQuery核心实现,则能够对请求结果进行解析,解析方式和jQuery的解析方式几乎完全相同;
superagent:能够实现主动发起get/post/delete等请求;
async:async模块是为了解决嵌套金字塔,和异步流程控制而生,由于nodejs是异步编程模型,有一些在同步编程中很容易做到的事情,现在却变得很麻烦。Async的流程控制就是为了简化这些操作;
request:有了这个模块,http请求变的超简单,Request使用简单,同时支持https和重定向;
步骤五:编写爬虫程序代码
打开hz.js,编写代码:
var superagent = require('superagent');
var cheerio = require('cheerio');
var async = require('async');
var fs = require('fs');
var request = require('request');
var page=1; //获取发型师处有分页功能,所以用该变量控制分页
var num = 0;//爬取到的信息总条数
var storeid = 1;//门店ID
console.log('爬虫程序开始运行......');
function fetchPage(x) { //封装函数
startRequest(x);
}
function startRequest(x) {
superagent
.post('http://tweixin.yueyishujia.com/v2/store/designer.json')
.send({
// 请求的表单信息Form data
page : x,
storeid : storeid
})
// Http请求的Header信息
.set('Accept', 'application/json, text/javascript, */*; q=0.01')
.set('Content-Type','application/x-www-form-urlencoded; charset=UTF-8')
.end(function(err, res){
// 请求返回后的处理
// 将response中返回的结果转换成JSON对象
if(err){
console.log(err);
}else{
var designJson = JSON.parse(res.text);
var deslist = designJson.data.designerlist;
if(deslist.length > 0){
num += deslist.length;
// 并发遍历deslist对象
async.mapLimit(deslist, 5,
function (hair, callback) {
// 对每个对象的处理逻辑
console.log('...正在抓取数据ID:'+hair.id+'----发型师:'+hair.name);
saveImg(hair,callback);
},
function (err, result) {
console.log('...累计抓取的信息数→→' + num);
}
);
page++;
fetchPage(page);
}else{
if(page == 1){
console.log('...爬虫程序运行结束~~~~~~~');
console.log('...本次共爬取数据'+num+'条...');
return;
}
storeid += 1;
page = 1;
fetchPage(page);
}
}
});
}
fetchPage(page);
function saveImg(hair,callback){
// 存储图片
var img_filename = hair.store.name+'-'+hair.name + '.png';
var img_src = 'http://photo.yueyishujia.com:8112' + hair.avatar; //获取图片的url
//采用request模块,向服务器发起一次请求,获取图片资源
request.head(img_src,function(err,res,body){
if(err){
console.log(err);
}else{
request(img_src).pipe(fs.createWriteStream('./image/' + img_filename)); //通过流的方式,把图片写到本地/image目录下,并用发型师的姓名和所属门店作为图片的名称。
console.log('...存储id='+hair.id+'相关图片成功!');
}
});
// 存储照片相关信息
var html = '姓名:'+hair.name+'<br>职业:'+hair.jobtype+'<br>职业等级:'+hair.jobtitle+'<br>简介:'+hair.simpleinfo+'<br>个性签名:'+hair.info+'<br>剪发价格:'+hair.cutmoney+'元<br>店名:'+hair.store.name+'<br>地址:'+hair.store.location+'<br>联系方式:'+hair.telephone+'<br>头像:<img src='+img_src+' style="width:200px;height:200px;">';
fs.appendFile('./data/' +hair.store.name+'-'+ hair.name + '.html', html, 'utf-8', function (err) {
if (err) {
console.log(err);
}
});
callback(null, hair);
}
步骤六:运行爬虫程序
输入node hz.js命令运行爬虫程序,效果图如下:
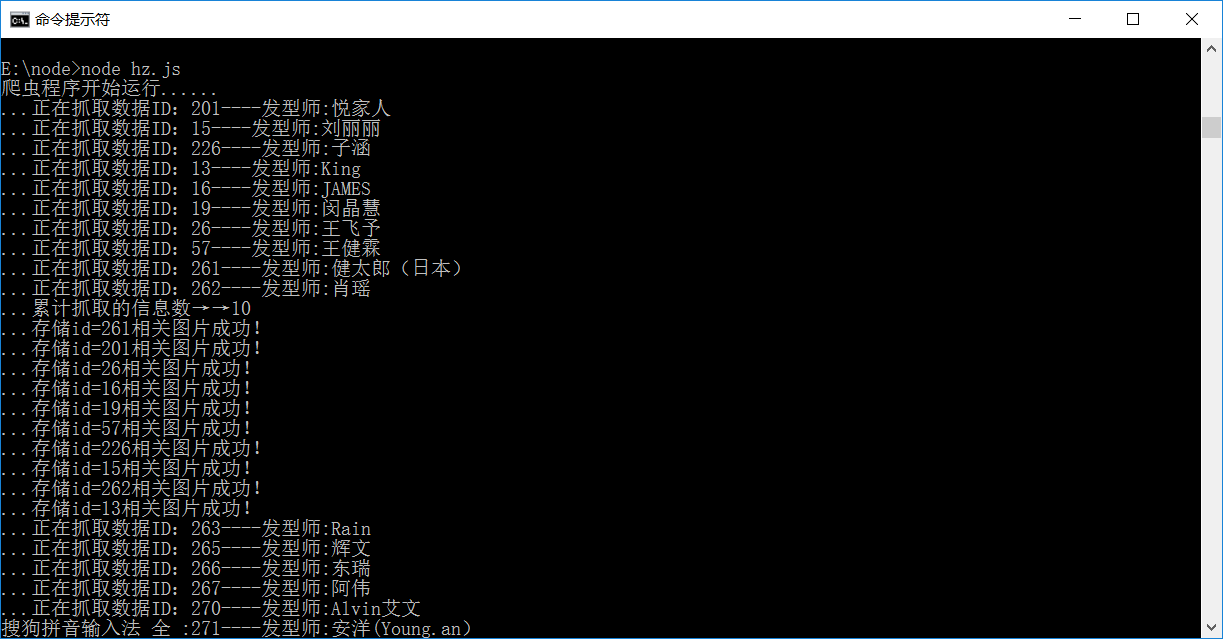
运行成功后,发型师基本信息以html文件的形式存储在data文件夹中,发型师头像图片存储在image文件夹下:
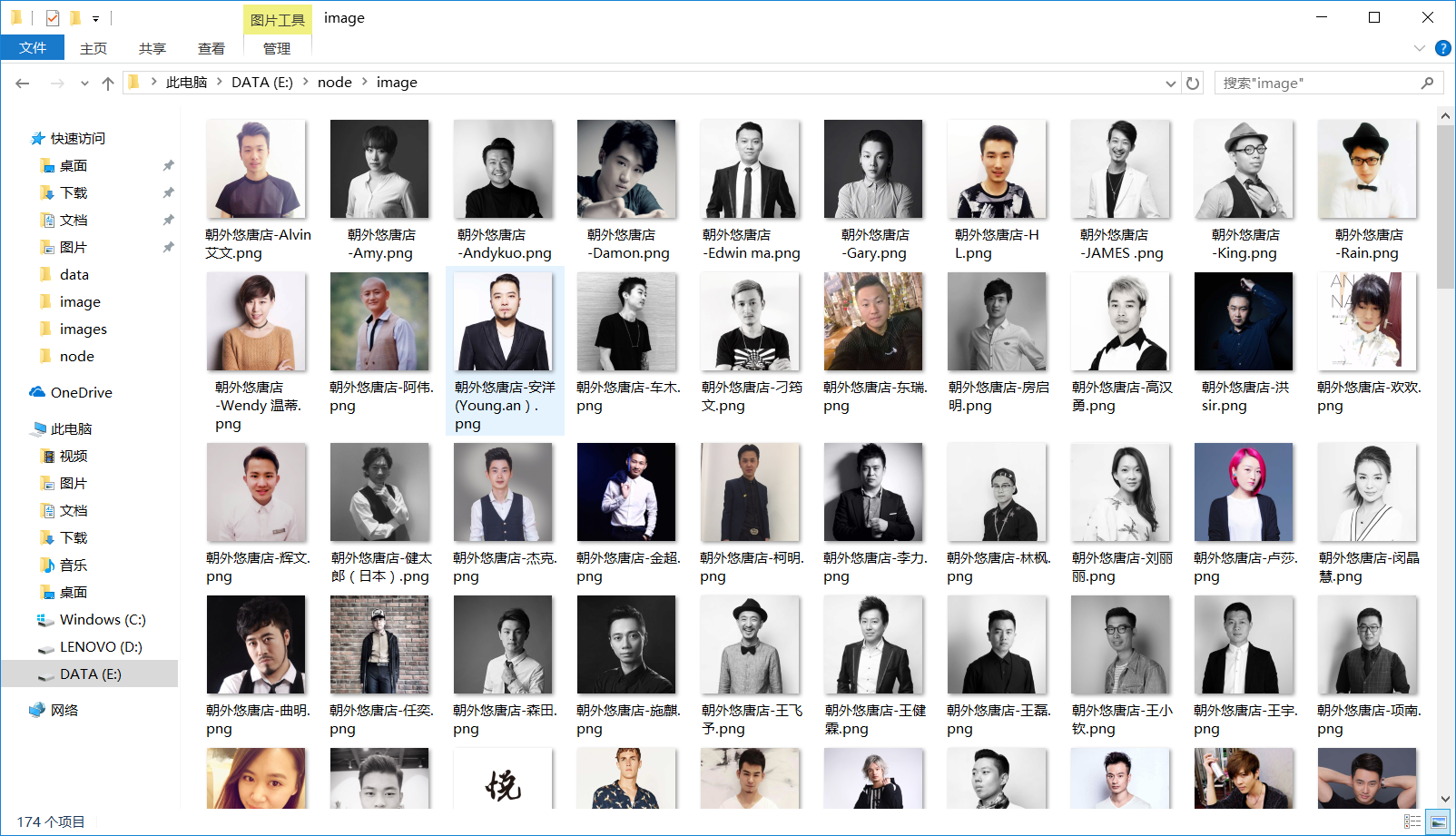
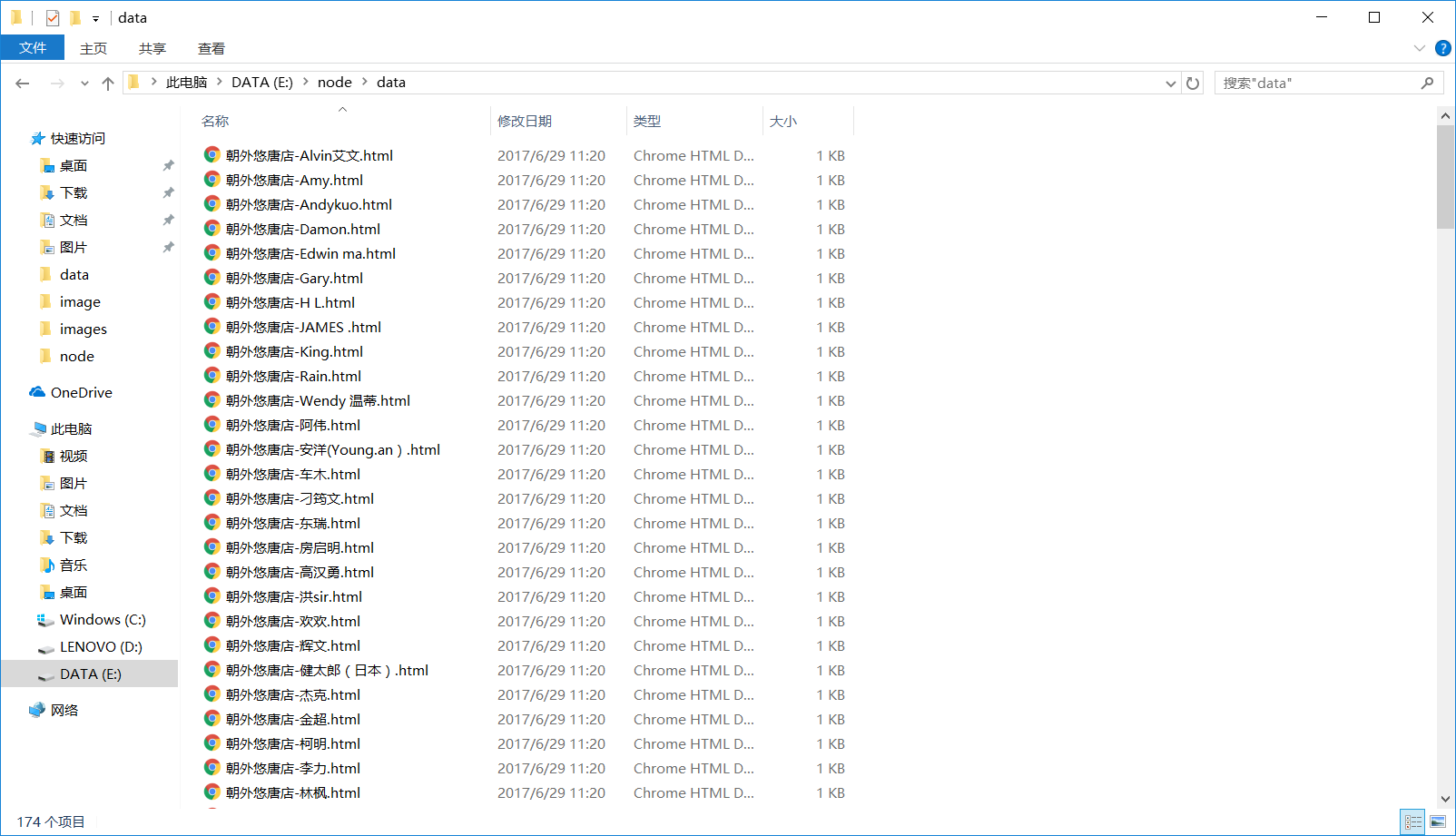
后记:到此一款基于node.js制作的简单爬虫就大功告成了,由于我也是初学者,好多地方也不是很理解,但好在是自己完成了,不足之处敬请谅解。
代码下载地址:https://github.com/yanglei0323/nodeCrawler
<node.js爬虫>制作教程的更多相关文章
- node.js爬虫
这是一个简单的node.js爬虫项目,麻雀虽小五脏俱全. 本项目主要包含一下技术: 发送http抓取页面(http).分析页面(cheerio).中文乱码处理(bufferhelper).异步并发流程 ...
- Node.js爬虫-爬取慕课网课程信息
第一次学习Node.js爬虫,所以这时一个简单的爬虫,Node.js的好处就是可以并发的执行 这个爬虫主要就是获取慕课网的课程信息,并把获得的信息存储到一个文件中,其中要用到cheerio库,它可以让 ...
- Node.js aitaotu图片批量下载Node.js爬虫1.00版
即使是https网页,解析的方式也不是一致的,需要多试试. 代码: //====================================================== // aitaot ...
- Node.js umei图片批量下载Node.js爬虫1.00
这个爬虫在abaike爬虫的基础上改改图片路径和下一页路径就出来了,代码如下: //====================================================== // ...
- Node.js abaike图片批量下载Node.js爬虫1.01版
//====================================================== // abaike图片批量下载Node.js爬虫1.01 // 1.01 修正了输出目 ...
- Node.js abaike图片批量下载Node.js爬虫1.00版
这个与前作的差别在于地址的不规律性,需要找到下一页的地址再爬过去找. //====================================================== // abaik ...
- Node JS爬虫:爬取瀑布流网页高清图
原文链接:Node JS爬虫:爬取瀑布流网页高清图 静态为主的网页往往用get方法就能获取页面所有内容.动态网页即异步请求数据的网页则需要用浏览器加载完成后再进行抓取.本文介绍了如何连续爬取瀑布流网页 ...
- Node.js 爬虫爬取电影信息
Node.js 爬虫爬取电影信息 我的CSDN地址:https://blog.csdn.net/weixin_45580251/article/details/107669713 爬取的是1905电影 ...
- 养只爬虫当宠物(Node.js爬虫爬取58同城租房信息)
先上一个源代码吧. https://github.com/answershuto/Rental 欢迎指导交流. 效果图 搭建Node.js环境及启动服务 安装node以及npm,用express模块启 ...
随机推荐
- 洛谷P2563 [AHOI2001]质数和分解
题目描述 任何大于 1 的自然数 n 都可以写成若干个大于等于 2 且小于等于 n 的质数之和表达式(包括只有一个数构成的和表达式的情况),并且可能有不止一种质数和的形式.例如,9 的质数和表达式就有 ...
- HTTP ------ connection 为 close 和 keep-alive 的区别
keep-alive和close这个要从TCP握手讲起 HTTP请求是基于TCP连接的,TCP的请求会包含(三次握手,中间请求,四次挥手)在HTTP/1.0时代,一个HTTP请求就要三次握手和四次挥手 ...
- 给阿里云ECS主机添加IPV6地址
阿里云公开的CentOS镜像将IPv6支持给去掉了,需要加载相关模块.通过HE的tunnelbroker开启IPv6隧道使国内VPS支持IPv6地址. 1. vim /etc/modprobe.d ...
- ZOJ 3782 G - Ternary Calculation 水
LINK:http://acm.zju.edu.cn/onlinejudge/showProblem.do?problemCode=3782 题意:给出3个数和两个符号(+-*/%) 思路:拿到题目还 ...
- TCP和UDP相关概念
位于传输层的协议,都是基于IP协议的. TCP是面向连接的.可靠的传输,UDP是无连接的.不可靠的传输.要进行TCp传输时候,需要进行三次握手,建立连接,然后才能发送数据,而且在发送过程中,有数据的确 ...
- TED_Topic1:Why we need to rethink capitalism
Topic 1:Why we need to rethink capitalism By Paul Tudor Jones II # Background about our speaker ...
- $this->success()传值不完整
public function manager_doExport() { $search=$_POST['search']; //前台输入2017-12-1,即,$search['starttime' ...
- mysql数据库 批量替换 某字段中的数据
当数据库出现这种情况: 表名:area id name 1 太仓 2 太仓市 3 太仓市 ... ... 我需要把 name字段中 的太仓市 的“市“去掉 可以使用: update `area` ...
- 搭建hibernate
需要导入的hibernate的包 其中所需要的依赖包 需要的配置文件 一个是元数据orm的配置文件 例如 package com.fmt.hibernate;public class Custome ...
- 22、WebDriver
什么是WebDriver?1.Webdriver(Selenium2)是一种用于Web应用程序的自动测试工具:2.它提供了一套友好的API:3.Webdriver完全就是一套类库,不依赖任何测试框架, ...