基于superagent 与 cheerio 的node简单爬虫
最近重新玩起了node,便总结下基本的东西,在本文中通过node的superagent与cheerio来抓取分析网页的数据。
目的
superagent 抓取网页
cheerio 分析网页
准备
Node(我的6.0)
三个依赖, express(4X),superagent 和 cheerio。
文档参考
superagent(http://visionmedia.github.io/superagent/ ) 是个 http 方面的库,可以发起 get 或 post 请求。
cheerio(https://github.com/cheeriojs/cheerio )为服务器特别定制的,快速、灵活、实施的jQuery. 用来从网页中以 css selector 取数据,使用方式跟 jquery 一样。
代码
那么我将抓取自己博客的数据。(有兴趣的朋友可以锦上添花一下,用正则筛选阅读数不少于400的文章.)
var express = require('express');
var superagent = require('superagent');
var cheerio = require('cheerio');
var app = express();
app.get('/', function (req, res, next) {
superagent.get('http://www.cnblogs.com/LIUYANZUO')
.end(function (err, sres) {
if (err) {
return next(err);
}
// sres.text 里面存储着网页的 html 内容,将它传给 cheerio.load 之后
// 就可以得到一个实现了 jquery 接口的变量,我们习惯性地将它命名为 `$`
// 剩下就都是 jquery 的内容了
var $ = cheerio.load(sres.text);
var items = [];
$('.day .postTitle2').each(function (index, element) {
var $element = $(element);
items.push({
标题: $element.text(),
网址: $element.attr('href')
});
});
res.send(items);
});
});
app.listen(4000, function () {
console.log('app is listenling at port 4000');
});
在命令行运行,得到截图
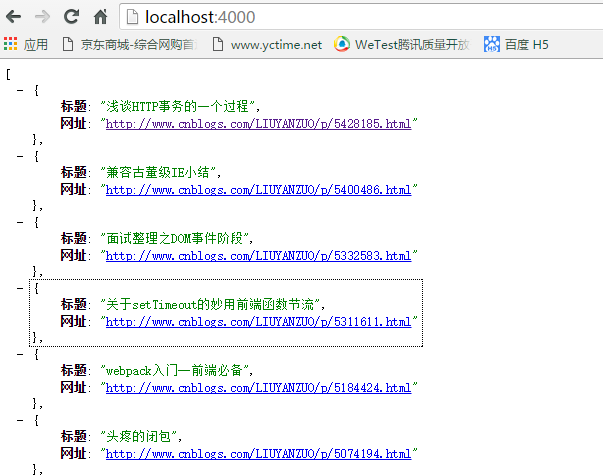
当然这是最简单的,下一篇我想介绍下node的异步并发。
基于superagent 与 cheerio 的node简单爬虫的更多相关文章
- 手把手教你学node.js之使用 superagent 与 cheerio 完成简单爬虫
使用 superagent 与 cheerio 完成简单爬虫 目标 建立一个 lesson 3 项目,在其中编写代码. 当在浏览器中访问 http://localhost:3000/ 时,输出 CNo ...
- nodejs爬虫初试---superagent和cheerio
前言 早就听过爬虫,这几天开始学习nodejs,写了个爬虫 demo ,爬取 博客园首页的文章标题.用户名.阅读数.推荐数和用户头像,现做个小总结. 使用到这几个点: 1.node的核心模块-- 文件 ...
- node的简单爬虫
最近在学node,这里简单记录一下. 首先是在linux的环境下,关于node的安装教程: https://github.com/alsotang/node-lessons/tree/master ...
- node 简单的爬虫
基于express爬虫, 1,node做爬虫的优势 首先说一下node做爬虫的优势 第一个就是他的驱动语言是JavaScript.JavaScript在nodejs诞生之前是运行在浏览器上的脚本语言, ...
- <node.js爬虫>制作教程
前言:最近想学习node.js,突然在网上看到基于node的爬虫制作教程,所以简单学习了一下,把这篇文章分享给同样初学node.js的朋友. 目标:爬取 http://tweixin.yueyishu ...
- 【原】小玩node+express爬虫-2
上周写了一个node+experss的爬虫小入门.今天继续来学习一下,写一个爬虫2.0版本. 这次我们不再爬博客园了,咋玩点新的,爬爬电影天堂.因为每个周末都会在电影天堂下载一部电影来看看. talk ...
- node:爬虫爬取网页图片
代码地址如下:http://www.demodashi.com/demo/13845.html 前言 周末自己在家闲着没事,刷着微信,玩着手机,发现自己的微信头像该换了,就去网上找了一下头像,看着图片 ...
- nodejs的简单爬虫
闲聊 好久没写博客了,前几天小颖在朋友的博客里看到了用nodejs的简单爬虫.所以小颖就自己试着做了个爬博客园数据的demo.嘻嘻...... 小颖最近养了条泰日天,自从养了我家 ...
- Node.js爬虫-爬取慕课网课程信息
第一次学习Node.js爬虫,所以这时一个简单的爬虫,Node.js的好处就是可以并发的执行 这个爬虫主要就是获取慕课网的课程信息,并把获得的信息存储到一个文件中,其中要用到cheerio库,它可以让 ...
随机推荐
- 防止ajax请求重发
debounce ajax请求,防止用户点击过快造成重发 按钮disabled处理,显示loading,防止用户失去耐心,重复点击 表单提交也可以同样处理.
- C# CryptoStream
using System; using System.IO; using System.Security.Cryptography; namespace RijndaelManaged_Example ...
- Java NIO原理和使用
Java NIO非堵塞应用通常适用用在I/O读写等方面,我们知道,系统运行的性能瓶颈通常在I/O读写,包括对端口和文件的操作上,过去,在打开一个I/O通道后,read()将一直等待在端口一边读取字节内 ...
- iOS ASIHTTPRequest用https协议加密请求
iOS 终端请求服务端数据时,为了保证数据安全,我们一般会使用https协议加密,而对于iOS的网络编程,我们一般会使用开源框架:ASIHTTPRequest,但是如果使用传统的http方式,即使忽略 ...
- 陷阱~EF中的Update与Insert共用一个数据上下文
事情是这样的,有一个列表,里面有很多用户信息,可能会有重复的用户,将这个列表的用户插入到数据表中,如果用户已经存在,就更新这个用户的FillTimes 字段,让它加1,使用的底层ORM是entity ...
- jQuery1.11源码分析(4)-----Sizzle工厂函数[原创]
在用前两篇讲述完正则表达式.初始化.特性检测之后,终于到了我们的正餐——Sizzle工厂函数! Sizzle工厂函数有四个参数, selector:选择符 context:查找上下文 results: ...
- html tr td colspan
colspan 属性规定单元格可横跨的列数, 第一行的colspan规定其一行所跨越的列数,要与下一行的<td></td>个数一致 if(!empty ($alarmDesc ...
- Sql存储过程分页--临时表存储
set ANSI_NULLS ON set QUOTED_IDENTIFIER ON go -- ============================================= -- Au ...
- characterCustomezition的资源打包代码分析
using System.Collections.Generic; using System.IO; using UnityEditor; using UnityEngine; class Creat ...
- GDB 使用大法
一.GDB 我用的是 GCC+POWERSHELL+GDB, GDB刚刚接触也有很多要记的. 二.一个调试示例 tst.c #include <stdio.h> int func(int ...