ES ik分词器使用技巧
match查询会将查询词分词,然后对分词的结果进行term查询。
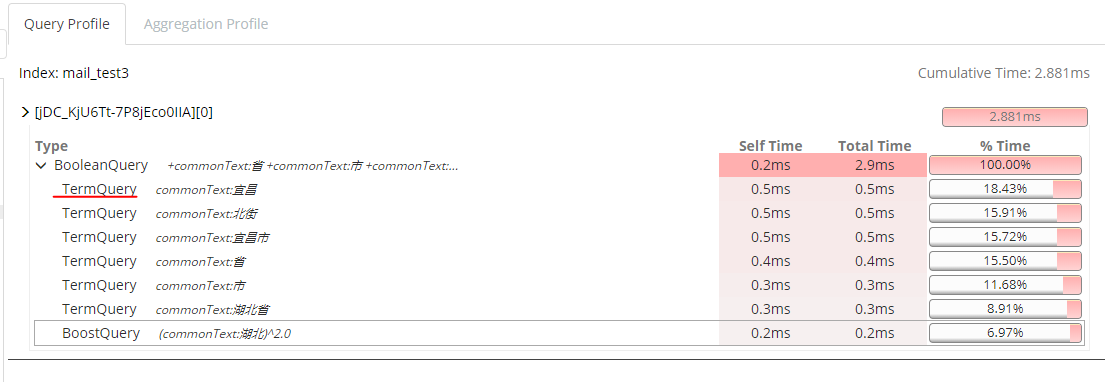
然后默认是将每个分词term查询之后的结果求交集,所以只要分词的结果能够命中,某条数据就可以被查询出来,而分词是在新建索引时指定的,只有text类型的数据才能设置分词策略。
新建索引,并指定分词策略:
PUT mail_test3
{
"settings": {
"index": {
"refresh_interval": "30s",
"number_of_shards": "1",
"number_of_replicas": "0"
}
},
"mappings": {
"default": {
"_all": {
"enabled": false
},
"_source": {
"enabled": true
},
"properties": {
"addressTude": {
"type": "text",
"analyzer": "ik_max_word",
"search_analyzer": "ik_smart",
"copy_to": [
"commonText"
],
"fielddata": true
},
"captureTime": {
"type": "long"
},
"commonText": {
"type": "text",
"analyzer": "ik_max_word",
"search_analyzer": "ik_smart",
"fielddata": true
},
"commonNum":{
"type": "text",
"analyzer": "ik_max_word",
"search_analyzer": "ik_smart",
"fielddata": true
},
"imsi": {
"type": "keyword",
"copy_to": ["commonNum"]
},
"uuid": {
"type": "keyword"
}
}
}
}
}
analyzer 指的是在建索引时的分词策略,search_analyzer 指的是在查询时的分词策略。ik分词器还有一种ik_smart 的分词策略,可以比较两种分词策略的差别:
ik_smart分词策略:
GET mail_test3/_analyze
{
"analyzer": "ik_smart",
"text": "湖南省湘潭市江山路96号-11-8"
}
结果:
{
"tokens": [
{
"token": "湖南省",
"start_offset": 0,
"end_offset": 3,
"type": "CN_WORD",
"position": 0
},
{
"token": "湘潭市",
"start_offset": 3,
"end_offset": 6,
"type": "CN_WORD",
"position": 1
},
{
"token": "江",
"start_offset": 6,
"end_offset": 7,
"type": "CN_CHAR",
"position": 2
},
{
"token": "山路",
"start_offset": 7,
"end_offset": 9,
"type": "CN_WORD",
"position": 3
},
{
"token": "96号",
"start_offset": 9,
"end_offset": 12,
"type": "TYPE_CQUAN",
"position": 4
},
{
"token": "11-8",
"start_offset": 13,
"end_offset": 17,
"type": "LETTER",
"position": 5
}
]
}
ik_max_word分词策略:
GET mail_test1/_analyze
{
"analyzer": "ik_max_word",
"text": "湖南省湘潭市江山路96号-11-8"
}
分词结果:
{
"tokens": [
{
"token": "湖南省",
"start_offset": 0,
"end_offset": 3,
"type": "CN_WORD",
"position": 0
},
{
"token": "湖南",
"start_offset": 0,
"end_offset": 2,
"type": "CN_WORD",
"position": 1
},
{
"token": "省",
"start_offset": 2,
"end_offset": 3,
"type": "CN_CHAR",
"position": 2
},
{
"token": "湘潭市",
"start_offset": 3,
"end_offset": 6,
"type": "CN_WORD",
"position": 3
},
{
"token": "湘潭",
"start_offset": 3,
"end_offset": 5,
"type": "CN_WORD",
"position": 4
},
{
"token": "市",
"start_offset": 5,
"end_offset": 6,
"type": "CN_CHAR",
"position": 5
},
{
"token": "江山",
"start_offset": 6,
"end_offset": 8,
"type": "CN_WORD",
"position": 6
},
{
"token": "山路",
"start_offset": 7,
"end_offset": 9,
"type": "CN_WORD",
"position": 7
},
{
"token": "96",
"start_offset": 9,
"end_offset": 11,
"type": "ARABIC",
"position": 8
},
{
"token": "号",
"start_offset": 11,
"end_offset": 12,
"type": "COUNT",
"position": 9
},
{
"token": "11-8",
"start_offset": 13,
"end_offset": 17,
"type": "LETTER",
"position": 10
},
{
"token": "11",
"start_offset": 13,
"end_offset": 15,
"type": "ARABIC",
"position": 11
},
{
"token": "8",
"start_offset": 16,
"end_offset": 17,
"type": "ARABIC",
"position": 12
}
]
}
ik_max_word分词器的分词结果更多,分词的粒度更细,而ik_smart的分词结果粒度更粗,但较为智能。一般的策略是建立索引使用ik_max_word,查询时使用ik_smart,这样就能尽可能多的查到结果,而且上文提到,match查询最终是转化为term查询,因此只要某个分词结果命中,结果中就会有该条数据。
如果对搜索结果的精度较高,可以在查询中加入operator参数,然后让分词结果的每个term查询结果之间求交集,这样能尽可能地提高精度。
这里的operator设置为or和and的差别较大,可以测试进行比较:
GET mail_test3/_search
{
"query": {
"match": {
"commonText": {
"query": "湖北省宜昌市天台东二街",
"operator": "and"
}
}
}
}
ES ik分词器使用技巧的更多相关文章
- ES系列一、CentOS7安装ES 6.3.1、集成IK分词器
Elasticsearch 6.3.1 地址: wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-6.3. ...
- 安装ik分词器以及版本和ES版本的兼容性
一.查看自己ES的版本号与之对应的IK分词器版本 https://github.com/medcl/elasticsearch-analysis-ik/blob/master/README.md 二. ...
- es之IK分词器
1:默认的分析器-- standard 使用默认的分词器 curl -XGET 'http://hadoop01:9200/_analyze?pretty&analyzer=standard' ...
- Elasticsearch5.1.1+ik分词器+HEAD插件安装小记
一.安装elasticsearch 1.首先需要安装好java,并配置好环境变量,详细教程请看 http://tecadmin.net/install-java-8-on-centos-rhel-an ...
- elasticsearch 之IK分词器安装
IK分词器地址:https://github.com/medcl/elasticsearch-analysis-ik 安装好ES之后就可以安装分词器插件了 记住选择ES对应的版本 对应的有版本选择下载 ...
- 如何开发自己的搜索帝国之安装ik分词器
Elasticsearch默认提供的分词器,会把每个汉字分开,而不是我们想要的根据关键词来分词,我是中国人 不能简单的分成一个个字,我们更希望 “中国人”,“中国”,“我”这样的分词,这样我们就需要 ...
- elasticsearch安装ik分词器
一.概要: 1.es默认的分词器对中文支持不好,会分割成一个个的汉字.ik分词器对中文的支持要好一些,主要由两种模式:ik_smart和ik_max_word 2.环境 操作系统:centos es版 ...
- ElasticSearch6.5.0 【安装IK分词器】
不得不夸奖一下ES的周边资源,比如这个IK分词器,紧跟ES的版本,卢本伟牛逼!另外ES更新太快了吧,几乎不到半个月一个小版本就发布了!!目前已经发了6.5.2,估计我还没怎么玩就到7.0了. 下载 分 ...
- Elasticsearch入门之从零开始安装ik分词器
起因 需要在ES中使用聚合进行统计分析,但是聚合字段值为中文,ES的默认分词器对于中文支持非常不友好:会把完整的中文词语拆分为一系列独立的汉字进行聚合,显然这并不是我的初衷.我们来看个实例: POST ...
随机推荐
- vnc server的安装
vnc是一款使用广泛的服务器管理软件,可以实现图形化管理.我在安装vnc server碰到一些问题,也整理下我的安装步骤,希望对博友们有一些帮助. 1 安装对应的软件包 [root@centos6 ~ ...
- PE知识复习之PE新增节
PE知识复习之PE新增节 一丶为什么新增节.以及新增节的步骤 例如前几讲.我们的PE文件在空白区可以添加代码.但是这样是由一个弊端的.因为你的空白区节属性可能是只读的不能执行.如果你修改了属性.那么程 ...
- PWA的探索与应用
本文由云+社区发表 PWA(Progressive Web App)起源背景 传统的Web网页存在以下几个问题: 进入一个页面必须要记住它的url或者加入书签,入口不便捷: 没网络就没响应,不具备离线 ...
- 服务器控件的几个属性 SelectedIndex、SelectedItem、SelectedValue、SelectedItem.Text、selectedItem.value
转自http://blog.csdn.net/iqv520/article/details/4419186 1. SelectedIndex ——选项的索引,为int,从0开始,可读可写 2. Sel ...
- [MySQL] timestamp和datetime的区别和大坑
1.timestamp占用4个字节;datetime占用8个字节2.timestamp范围1970-01-01 00:00:01.000000 到 2038-01-19 03:14:07.999999 ...
- Flask 系列之 Migration
说明 操作系统:Windows 10 Python 版本:3.7x 虚拟环境管理器:virtualenv 代码编辑器:VS Code 实验目标 通过使用 flask-migrate 实现数据库的迁移操 ...
- linux下sophos,clamav+clamtk杀毒软件
以deepin为例 avast for linux sophos for linux comodo for linux 目前能够在官网找到. 先说clamav clamav 听说很活跃,clamav是 ...
- 安卓开发:UI组件-图片控件ImageView(使用Glide)和ScrollView
2.7ImageView 2.7.1插入本地图片 一个图片控件,可以用来显示本地和网络图片. 在首页添加按钮ImageView,指向新页面(步骤与前同,不再详写). activity_image_vi ...
- 基础环境系列:PHP7.3.0并连接pache/IIS和MySQL
版本: php7.3.0 MySQL8.0.12 Apache2.4 IIS8 一.下载PHP 1.下载php3.7 PHP版本:php7.3(7.3.0) 下载地址:https://windows ...
- SpringBoot实现全文搜索
• 全文搜索 • solr安装 • solr中文分词 • solr数据库导入 • solr数据查询 • solrj接口调用 1: