spark-jobserver安装实践 (centos7.4)
spark-jobserver 提供了一个RESTful接口来提交和管理spark的jobs,jars和job contexts。
该工程位于:https://github.com/spark-jobserver/spark-jobserver
特性:
- 针对job 和 contexts的各个方面提供了REST风格的api接口进行管理
- 支持SparkSQL,Hive,Streaming Contexts/jobs 以及定制job contexts!
- 支持压秒级别低延迟的任务通过长期运行的job contexts
- 可以通过结束context来停止运行的作业(job)
- 分割jar上传步骤以提高job的启动
- 异步和同步的job API,其中同步API对低延时作业非常有效
- 支持Standalone Spark和Mesos
- Job和jar信息通过一个可插拔的DAO接口来持久化
- 命名RDD以缓存,并可以通过该名称获取RDD。这样可以提高作业间RDD的共享和重用
- 支持scala 2.10 和 2.11 和2.12
当前部署环境:

export JAVA_HOME=/usr/local/java/jdk1.8.0_191
export CLASSPATH=.:$JAVA_HOME/lib/tools.jar:$JAVA_HOME/lib/dt.jar
export PATH=$JAVA_HOME/bin:$HOME/bin:$HOME/.local/bin:$PATH
使配置文件生效
source /etc/profile 或 . /etc/profile
验证是否成功
java -version

scala安装:
下载源码包:
wget https://downloads.lightbend.com/scala/2.12.6/scala-2.12.6.tgz
创建安装目录:
mkdir /usr/local/scala
解压:
tar -zxf scala-2.12.6.tgz -C /usr/local/scala/
添加环境变量:vim /etc/profile 在最后添加

export SCALA_HOME=/usr/local/scala/scala-2.12.6
export PATH=$PATH:$SCALA_HOME/bin
使配置生效:
source /etc/profile 或 . /etc/profile
验证是否成功:
scala -version

spark安装:
下载安装包:wget https://archive.apache.org/dist/spark/spark-2.3.1/spark-2.3.1-bin-hadoop2.6.tgz
创建安装目录:
mkdir /usr/local/spark
解压安装包:
tar -xzvf spark-2.3.1-bin-hadoop2.6.tgz -C /usr/local/spark/
设置环境变量:vim /etc/profile 在最后添加

export SPARK_HOME=/usr/local/spark/spark-2.3.1-bin-hadoop2.6
export PATH=$PATH:$SPARK_HOME/bin
使配置生效:
source /etc/profile 或 . /etc/profile
修改配置:
cd /usr/local/spark/spark-2.3.1-bin-hadoop2.6/conf/
cp spark-env.sh.template spark-env.sh
vim spark-env.sh
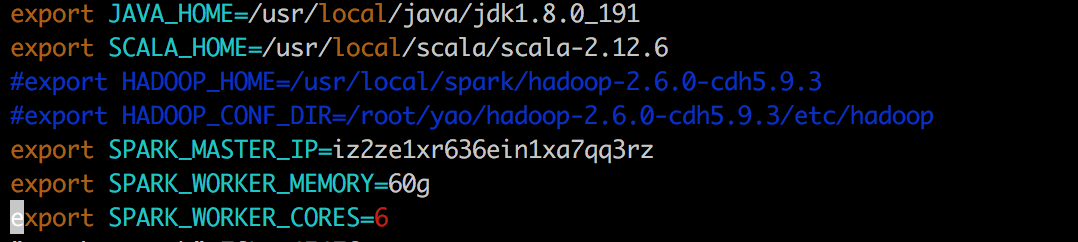
export JAVA_HOME=/usr/local/java/jdk1.8.0_191
export SCALA_HOME=/usr/local/scala/scala-2.12.6
#export HADOOP_HOME=/usr/local/spark/hadoop-2.6.0-cdh5.9.3
#export HADOOP_CONF_DIR=/root/yao/hadoop-2.6.0-cdh5.9.3/etc/hadoop
export SPARK_MASTER_IP=iz2ze1xr636ein1xa7qq3rz
export SPARK_WORKER_MEMORY=60g
export SPARK_WORKER_CORES=6
*spark 为单节点
cp slaves.template slaves
启动spark
sh ./sbin/start-all.sh 或者
sh /bin/spark-shell.sh
验证是否成功:
spark-shell
jps查看

浏览器查看
ip:8080
sbt安装:
下载yum源repo:
curl https://bintray.com/sbt/rpm/rpm > /etc/yum.repos.d/bintray-sbt-rpm.repo
安装sbt:
yum install sbt -y
验证安装是否成功:

spark-jobserver安装:
1)安装mysql 版本不限 当前使用版本为mysql5.6
查看已安装的 Mariadb 数据库版本并卸载:
rpm -qa|grep mariadb|xargs rpm -e --nodeps
下载安装包:
wget http://repo.mysql.com/mysql-community-release-el7-5.noarch.rpm
安装mysql-community-release-el7-5.noarch.rpm包:
rpm -ivh mysql-community-release-el7-5.noarch.rpm
安装完成之后,会在 /etc/yum.repos.d/ 目录下新增 mysql-community.repo 、mysql-community-source.repo 两个 yum 源文件
安装mysql :
yum install mysql-server
启动msyql:
systemctl start mysqld.service #启动 mysql
systemctl restart mysqld.service #重启 mysql
systemctl stop mysqld.service #停止 mysql
systemctl enable mysqld.service #设置 mysql 开机启动
设置密码:
mysql5.6 安装完成后,它的 root 用户的密码默认是空的,我们需要及时用 mysql 的 root 用户登录(第一次直接回车,不用输入密码),并修改密码。
# mysql -u root
mysql> use mysql;
mysql> update user set password=PASSWORD("这里输入root用户密码") where User='root';
mysql> flush privileges;
创建spark-jobserver数据库
mysql>create database spark_jobserver;
mysql>grant all privileges on *.* to root@'%' identified by '123456';
mysql> flush privileges;
2)安装jobserver
官方文档:https://github.com/spark-jobserver/spark-jobserver
clone jobserver源代码:
cd /usr/local/spark/spark-2.3.1-bin-hadoop2.6/
git clone https://github.com/spark-jobserver/spark-jobserver.git
修改配置:
cd /usr/local/spark/spark-2.3.1-bin-hadoop2.6/spark-jobserver/job-server/config/
cp local.conf.template local.conf
cp local.sh.template local.sh
cp shiro.ini.basic.template shiro.ini
修改local.conf 修改内容如下:
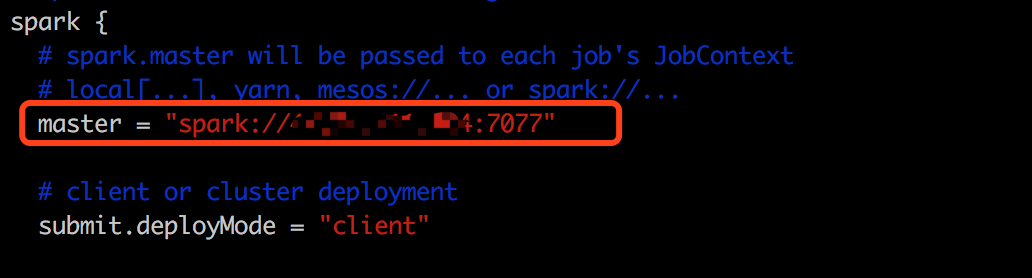
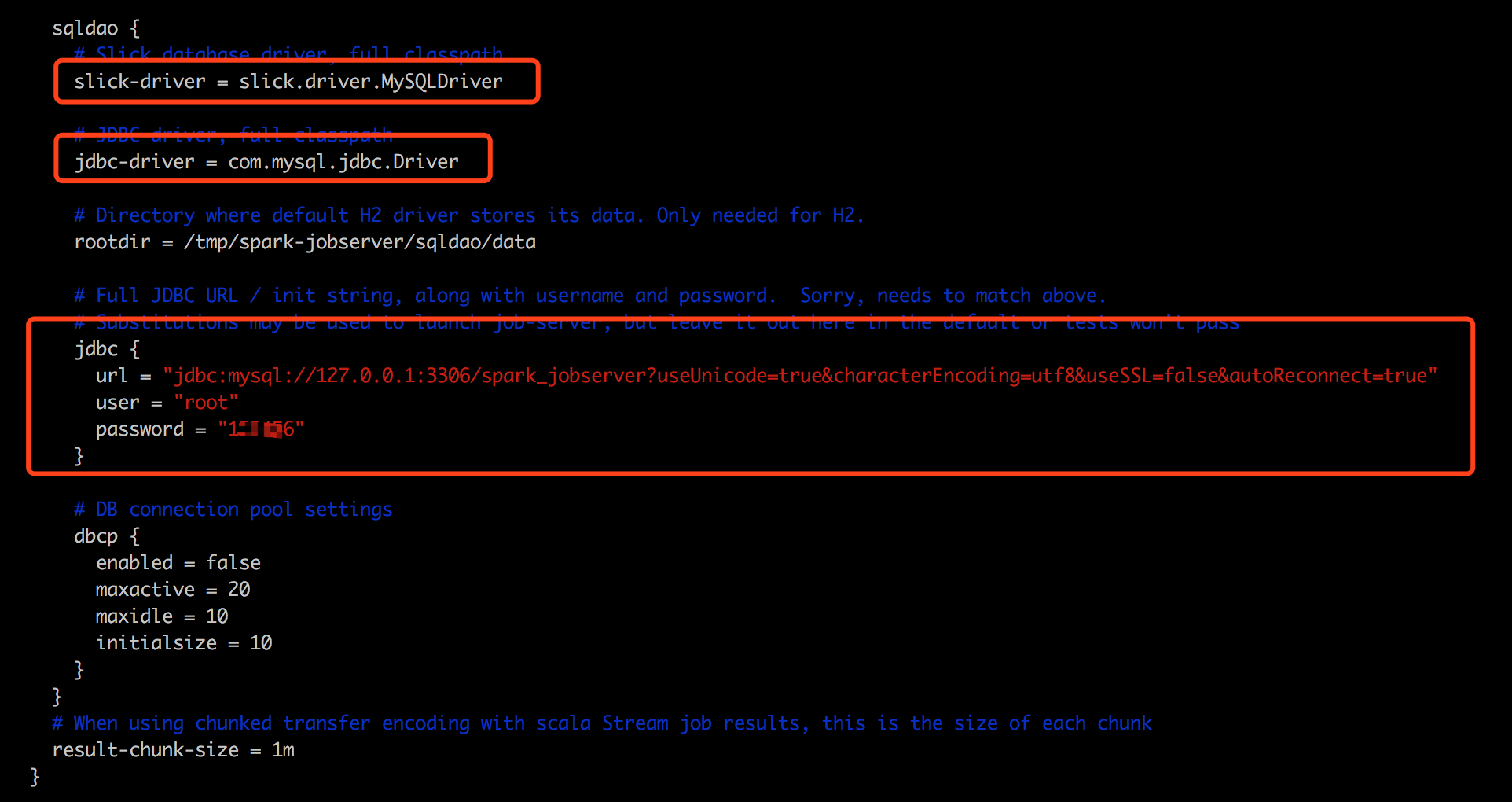

local.sh :修改属性

修改配置文件application.conf:
vim /usr/local/spark/spark-2.3.1-bin-hadoop2.6/spark-jobserver/job-server/src/main/resources/application.conf

修改心跳检测超时时间为30s

vim /usr/local/spark/spark-2.3.1-bin-hadoop2.6/spark-jobserver/config/local.conf
在结尾添加
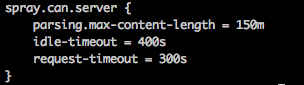
spray.can.server {
parsing.max-content-length = 150m
idle-timeout = 400s
request-timeout = 300s
}
上传jar包大小限制配置,大小自定义
打包配置:
cd /usr/local/spark/spark-2.3.1-bin-hadoop2.6/spark-jobserver/bin/
sh server_deploy.sh local

启动jobserver:
cd ..
sh server_start.sh

验证启动是否成功:

上传jar包时,可能会出现如下问题
1) jar包大小限制问题
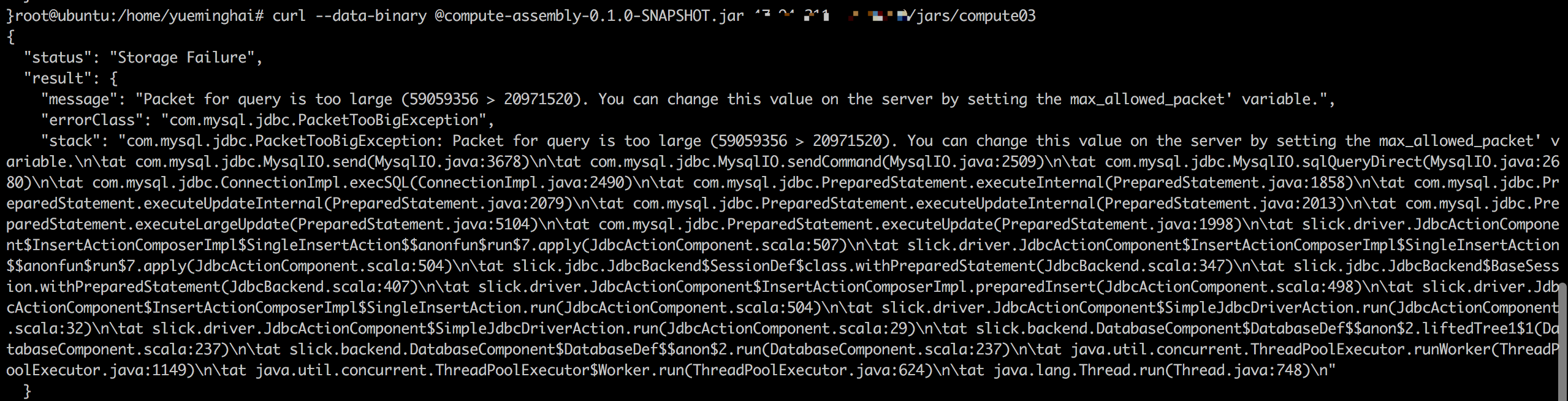
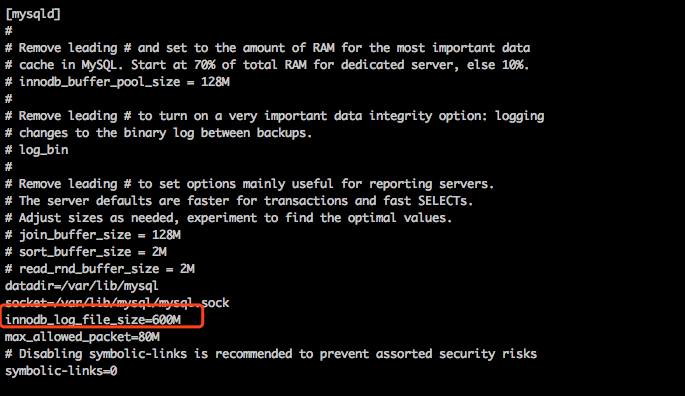
解决方法:vim /etc/my.cnf 添加max_allowed_packet=80M 添加后重启mysql服务
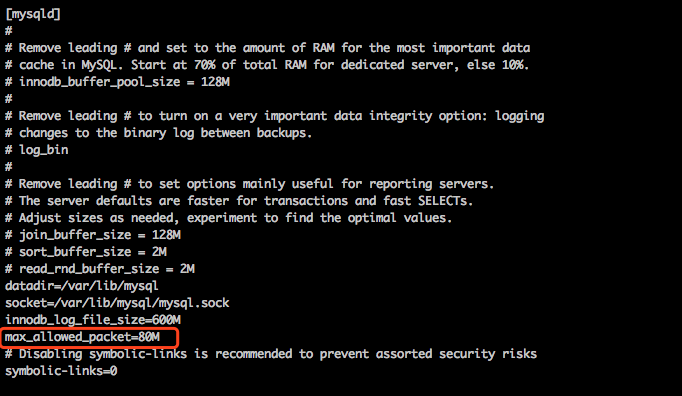
2)innodb_log_file_size大小问题
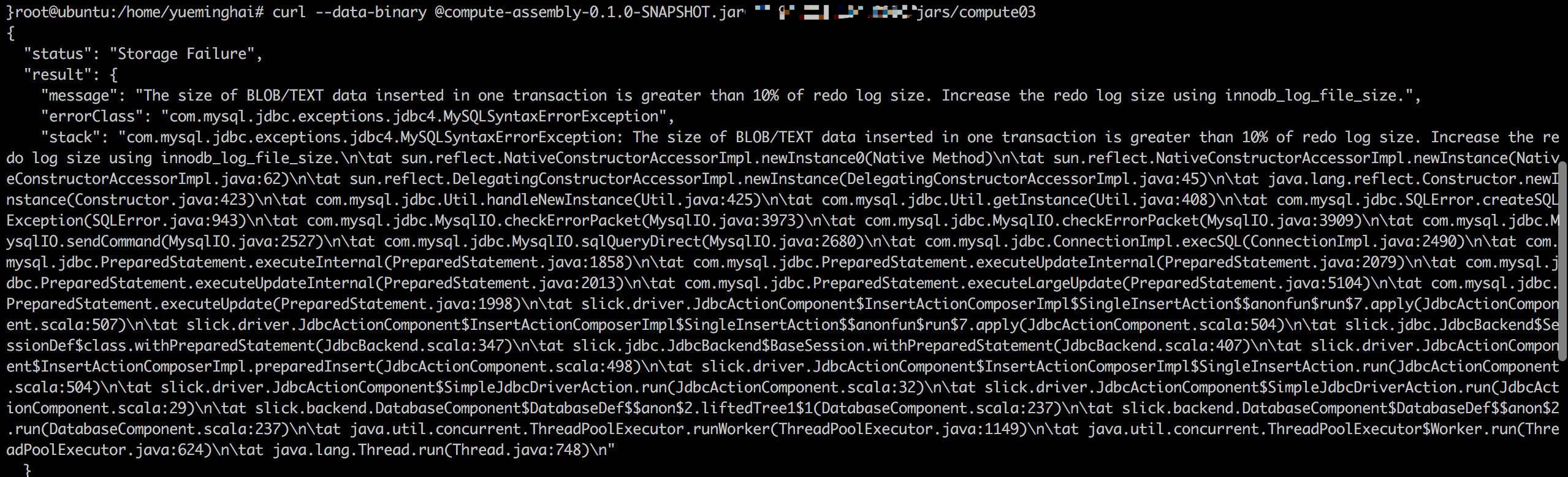
解决方法:vim /etc/my.cnf 添加innodb_log_file_size=600M 添加后重启mysql服务
3)健康检测超时时间问题

解决方法: vim /usr/local/spark/spark-2.3.1-bin-hadoop2.6/spark-jobserver/job-server/src/main/resources/application.conf

修改failure-detector.acceptable-heartbeat-pause = 30s
问题解决 :jar包成功上传!

完成~
如有问题欢迎加入qq群讨论 群号:340939208
原文:https://www.cnblogs.com/yueminghai/p/10413171.html
版权声明:本文为博主原创文章,转载请附上博文链接!
spark-jobserver安装实践 (centos7.4)的更多相关文章
- 《Spark MLlib机器学习实践》内容简介、目录
http://product.dangdang.com/23829918.html Spark作为新兴的.应用范围最为广泛的大数据处理开源框架引起了广泛的关注,它吸引了大量程序设计和开发人员进行相 ...
- Spark standlone安装与配置
spark的安装简单,去官网下载与集群hadoop版本相一致的文件即可. 解压后,主要需要修改spark-evn.sh文件. 以spark standlone为例,配置dn1,nn2为master,使 ...
- 5分钟windows wamp php安装phpunit 2015最新安装实践
16:11 2015/11/235分钟windows wamp php安装phpunit 2015最新安装实践我花了一个下午和一个上午的时间注意:步骤中添加环境变量多的时候要保存很多步,知道窗口都自动 ...
- Spark standalone安装(最小化集群部署)
Spark standalone安装-最小化集群部署(Spark官方建议使用Standalone模式) 集群规划: 主机 IP ...
- 使用Xshell5连接虚拟机VMware中安装的CentOS7系统
使用Xshell5连接VMware中安装的CentOS7系统 准备材料 Xshell 下载地址 VMware Workstation 12 Pro 下载地址 CentOS 7 64位系统 下载地址 安 ...
- NAT 模式下虚拟机安装的centos7 ping主机显示connect: Network is unreachable
在虚拟机下安装的centos7使用的网络是NAT模式,安装成功后ping主机地址显示 Network is unreachable 解决方案: 1)使用ifconfig命令查看网卡信息 2)进入/et ...
- Spark简介安装和简单例子
Spark简介安装和简单例子 Spark简介 Spark是一种快速.通用.可扩展的大数据分析引擎,目前,Spark生态系统已经发展成为一个包含多个子项目的集合,其中包含SparkSQL.Spark S ...
- CentOS 6.5下PXE+Kickstart无人值守安装操作系统centos7.3
CentOS 6.5下PXE+Kickstart无人值守安装操作系统centos7.3 一.简介 1.1 什么是PXE PXE(Pre-boot Execution Environment,预启动执行 ...
- k8s1.4.3安装实践记录(2)-k8s安装
前面一篇已经安装好了ETCD.docker与flannel(k8s1.4.3安装实践记录(1)),现在可以开始安装k8s了 1.K8S 目前centos yum上的kubernetes还是1.2.0, ...
- spark 单机版安装
jdk-8u73-linux-x64.tar.gz hadoop-2.6.0.tar.gz scala-2.10.6.tgz spark-1.6.0-bin-hadoop2.6.tgz 1.安装jdk ...
随机推荐
- cmd 命令 net start mongodb 启动不了,提示 net 不是内部命令或者外部命令
1.要管理员的身份进入 cmd 2.右击我的电脑-->属性-->高级系统设置 3.选择高级-->环境变量 4.找到系统变量-->Path-->编辑 5.把 C:\wind ...
- JBPM工作流(八)——流程实例(PI)Process Instance
/** * 流程实例 * * 启动流程实例 * * 完成任务 * * 查询 * * 查询流程实例 * * 查询任务 * * 查询正在 ...
- JSON.stringify 语法实例讲解+easyui data-options属性+expires【申明:来源于网络】
JSON.stringify 语法实例讲解+easyui data-options属性+expires[申明:来源于网络] JSON.stringify 语法实例讲解:http://www.jb51. ...
- DocX Xceed.Words.NET操作Word,插入特殊符号
x 传送门,我们走... DocX的Github传送门 介绍一 介绍二 写入特殊符号 开始... 自己做一个工具,要导出Word的,当时刚开始想使用Xceed.Words.NET.dll第三方插件进行 ...
- C#获取项目程序及运行路径的方
1.asp.net webform用“Request.PhysicalApplicationPath获取站点所在虚拟目录的物理路径,最后包含“\”: 2.c# winform用 A:“Applic ...
- 屏蔽登录QQ后总是弹出的QQ网吧页面
不知道从什么时候开始的,每次登录QQ的时候,有个叫qq网吧的页面都会弹出来,腾讯你是撒吗?这个公司真是死性不改.按照它的提示,已经设置了好几次这是我家,这特么不是网吧,然并卵.你说它技术不行吧,它堪称 ...
- debug_backtrace
<?php one(); function one() { two(); } function two() { three(); } function three() { print_r( de ...
- Kafka: Exactly-once Semantics
https://www.confluent.io/blog/enabling-exactly-kafka-streams/ https://cwiki.apache.org/confluence/di ...
- python之str字符串
字符串是python非常重要的数据类型,它是一个序列(列表和元组也是序列),有下标,可以通过下标遍历字符串序列:同时字符串也是一个不可变数据类型,每次使用"+"拼接字符串时都会产生 ...
- xmanager 开启X11转发失败问题解决
安装相关rpm包 yum -y install xorg-x11-xauth xorg-x11-utils xorg-x11-fonts-* yum install dejavu-lgc-sans-f ...