【SparkStreaming学习之三】 SparkStreaming和kafka整合
环境
虚拟机:VMware 10
Linux版本:CentOS-6.5-x86_64
客户端:Xshell4
FTP:Xftp4
jdk1.8
scala-2.10.4(依赖jdk1.8)
spark-1.6
一、receiver模式
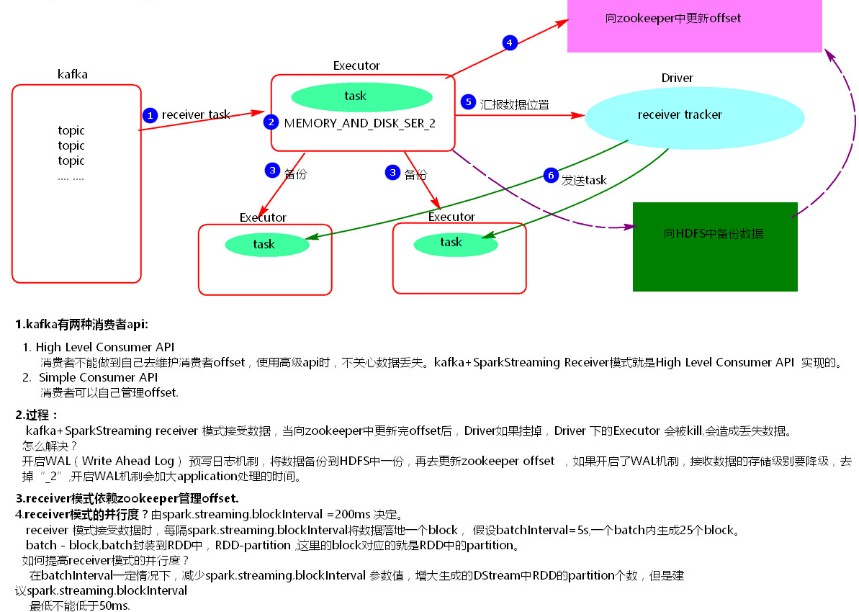
1、receiver模式理解
在SparkStreaming程序运行起来后,Executor中会有receiver tasks接收kafka推送过来的数据。数据会被持久化,默认级别为MEMORY_AND_DISK_SER_2,这个级别也可以修改。receiver task对接收过来的数据进行存储和备份,这个过程会有节点之间的数据传输。备份完成后去zookeeper中更新消费偏移量,然后向Driver中的receiver tracker汇报数据的位置。最后Driver根据数据本地化将task分发到不同节点上执行。
2、receiver模式中存在的问题
当Driver进程挂掉后,Driver下的Executor都会被杀掉,当更新完zookeeper消费偏移量的时候,Driver如果挂掉了,就会存在找不到数据的问题,相当于丢失数据。
如何解决这个问题?
开启WAL(write ahead log)预写日志机制,在接受过来数据备份到其他节点的时候,同时备份到HDFS上一份(我们需要将接收来的数据的持久化级别降级到MEMORY_AND_DISK),这样就能保证数据的安全性。不过,因为写HDFS比较消耗性能,要在备份完数据之后才能进行更新zookeeper以及汇报位置等,这样会增加job的执行时间,这样对于任务的执行提高了延迟度。
3、receiver模式代码
package com.wjy.ss; import java.util.Arrays;
import java.util.HashMap;
import java.util.Map; import org.apache.spark.SparkConf;
import org.apache.spark.api.java.function.FlatMapFunction;
import org.apache.spark.api.java.function.Function2;
import org.apache.spark.api.java.function.PairFunction;
import org.apache.spark.storage.StorageLevel;
import org.apache.spark.streaming.Durations;
import org.apache.spark.streaming.api.java.JavaPairDStream;
import org.apache.spark.streaming.api.java.JavaPairReceiverInputDStream;
import org.apache.spark.streaming.api.java.JavaStreamingContext;
import org.apache.spark.streaming.kafka.KafkaUtils; import scala.Tuple2; public class SparkStreamingOnKafkaReceiver { public static void main(String[] args) {
SparkConf conf = new SparkConf().setAppName("SparkStreamingOnKafkaReceiver").setMaster("local[2]");
//开启预写日志 WAL机制
conf.set("spark.streaming.receiver.writeAheadLog.enable", "true");
JavaStreamingContext jsc = new JavaStreamingContext(conf,Durations.seconds(5));
//可以保存接收的数据
jsc.checkpoint("./receivedata"); /**
* 设置读取的topic和接受数据的线程数
*/
Map<String, Integer> topicConsumerConcurrency = new HashMap<String, Integer>();
topicConsumerConcurrency.put("MYTOPIC", 1); /**
* 第一个参数是StreamingContext
* 第二个参数是ZooKeeper集群信息(接受Kafka数据的时候会从Zookeeper中获得Offset等元数据信息)
* 第三个参数是Consumer Group 消费者组
* 第四个参数是消费的Topic以及并发读取Topic中Partition的线程数
* 第五个参数设置receiver的存储级别 开启WAL机制 接收的数据存储级别要降级
* 注意:
* KafkaUtils.createStream 使用五个参数的方法,设置receiver的存储级别
*/
JavaPairReceiverInputDStream<String, String> receiverDStream = KafkaUtils.createStream(jsc,
"node3:2181,node4:2181,node5:2181",
"MyFirstConsumerGroup",
topicConsumerConcurrency,
StorageLevel.MEMORY_AND_DISK()); receiverDStream.flatMap(new FlatMapFunction<Tuple2<String,String>, String>() {
private static final long serialVersionUID = 1L; @Override
public Iterable<String> call(Tuple2<String, String> tuple)
throws Exception {
return Arrays.asList(tuple._2.split("\t"));
}
}).mapToPair(new PairFunction<String, String, Integer>() {
private static final long serialVersionUID = 1L; @Override
public Tuple2<String, Integer> call(String word) throws Exception {
return new Tuple2<String, Integer>(word,1);
}
}).reduceByKey(new Function2<Integer, Integer, Integer>() {
private static final long serialVersionUID = 1L;
@Override
public Integer call(Integer v1, Integer v2) throws Exception {
return v1+v2;
}
}).print(100); jsc.start();
jsc.awaitTermination();
jsc.close();
} }
4、receiver的并行度设置
receiver的并行度是由spark.streaming.blockInterval来决定的,默认为200ms,假设batchInterval为5s,那么每隔blockInterval就会产生一个block,这里就对应每批次产生RDD的partition,这样5秒产生的这个Dstream中的这个RDD的partition为25个,并行度就是25。如果想提高并行度可以减少blockInterval的数值,但是最好不要低于50ms。

由于receiver模式存在的问题,目前这种模式在实际生产中用的较少。
二、Driect模式
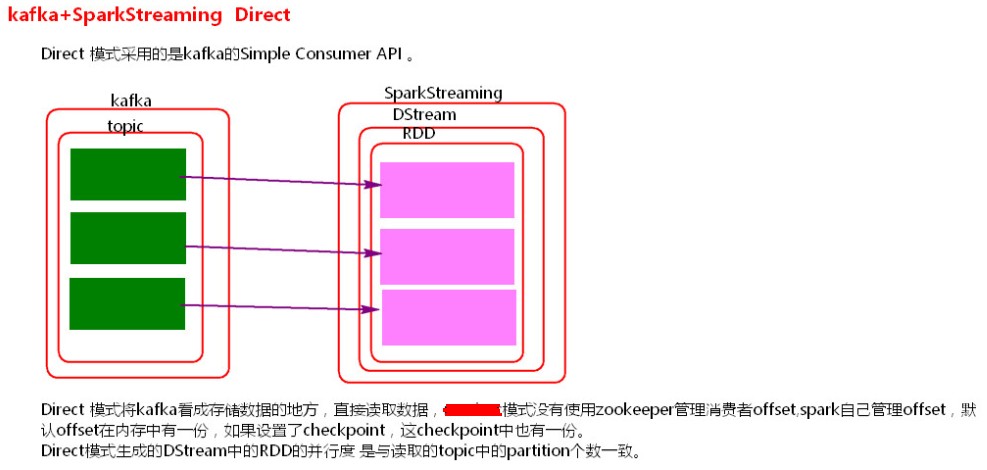

1、Direct模式理解
SparkStreaming+kafka 的Driect模式就是将kafka看成存数据的一方,不是被动接收数据,而是主动去取数据。消费者偏移量也不是用zookeeper来管理,而是SparkStreaming内部对消费者偏移量自动来维护,默认消费偏移量是在内存中,当然如果设置了checkpoint目录,那么消费偏移量也会保存在checkpoint中。当然也可以实现用zookeeper来管理。
2、Direct模式并行度设置
Direct模式的并行度是由读取的kafka中topic的partition数决定的。
3、Direct模式代码
package com.wjy.ss; import java.util.Arrays;
import java.util.HashMap;
import java.util.HashSet;
import java.util.Map; import kafka.serializer.StringDecoder; import org.apache.spark.SparkConf;
import org.apache.spark.api.java.function.FlatMapFunction;
import org.apache.spark.api.java.function.Function2;
import org.apache.spark.api.java.function.PairFunction;
import org.apache.spark.streaming.Durations;
import org.apache.spark.streaming.api.java.JavaPairInputDStream;
import org.apache.spark.streaming.api.java.JavaStreamingContext;
import org.apache.spark.streaming.kafka.KafkaUtils; import scala.Tuple2; public class SparkStreamingOnKafkaDirected { public static void main(String[] args) {
SparkConf conf = new SparkConf().setMaster("local").setAppName("SparkStreamingOnKafkaDirected");
conf.set("spark.streaming.backpressure.enabled", "false");
conf.set("spark.streaming.kafka.maxRatePerPartition ", "100");
JavaStreamingContext jsc = new JavaStreamingContext(conf, Durations.seconds(5));
/**
* 可以不设置checkpoint 不设置不保存offset,offset默认在内存中有一份,如果设置checkpoint在checkpoint也有一份offset, 一般要设置。
*/
jsc.checkpoint("./checkpoint");
Map<String, String> kafkaParameters = new HashMap<String, String>();
kafkaParameters.put("metadata.broker.list", "node1:9092,node2:9092,node3:9092");
kafkaParameters.put("auto.offset.reset", "smallest");
HashSet<String> topics = new HashSet<String>();
topics.add("Mytopic"); JavaPairInputDStream<String, String> lines =
KafkaUtils.createDirectStream(jsc,
String.class,
String.class,
StringDecoder.class,
StringDecoder.class,
kafkaParameters,
topics); lines.flatMap(new FlatMapFunction<Tuple2<String,String>, String>() {
//如果是Scala,由于SAM转换,所以可以写成val words = lines.flatMap { line => line.split(" ")}
private static final long serialVersionUID = 1L; public Iterable<String> call(Tuple2<String,String> tuple) throws Exception {
return Arrays.asList(tuple._2.split("\t"));
}
}).mapToPair(new PairFunction<String, String, Integer>() {
private static final long serialVersionUID = 1L; public Tuple2<String, Integer> call(String word) throws Exception {
return new Tuple2<String, Integer>(word, 1);
}
}).reduceByKey(new Function2<Integer, Integer, Integer>() { //对相同的Key,进行Value的累计(包括Local和Reducer级别同时Reduce)
private static final long serialVersionUID = 1L;
public Integer call(Integer v1, Integer v2) throws Exception {
return v1 + v2;
}
}).print(); jsc.start();
jsc.awaitTermination();
jsc.close(); } }
三、相关配置
1、反压机制:
spark.streaming.backpressure.enabled 默认false
2、blockInterval:
spark.streaming.blockInterval 默认200ms
3、接收数据速率:
spark.streaming.receiver.maxRate 默认没有设置
4、预写日志:
spark.streaming.receiver.writeAheadLog.enable 默认false没有开启
5、该参数决定是否需要以Gracefully方式来关闭Streaming程序(详情请参见SPARK-7776)。Spark会在启动 StreamingContext 的时候注册这个钩子
spark.streaming.stopGracefullyOnShutdown
6、每个分区每秒钟接收的消息数量
spark.streaming.kafka.maxRatePerPartition
参考:
Spark
【SparkStreaming学习之三】 SparkStreaming和kafka整合的更多相关文章
- WebService学习之三:spring+cxf整合
步骤一:spring项目(java web项目)引入CXF jar包 步骤二:创建webservice服务器 1)创建一个服务接口 package com.buss.app.login; import ...
- 【Spring Boot学习之三】Spring Boot整合数据源
环境 eclipse 4.7 jdk 1.8 Spring Boot 1.5.2 一.Spring Boot整合Spring JDBC 1.pom.xml <project xmlns=&quo ...
- 大数据学习day32-----spark12-----1. sparkstreaming(1.1简介,1.2 sparkstreaming入门程序(统计单词个数,updateStageByKey的用法,1.3 SparkStreaming整合Kafka,1.4 SparkStreaming获取KafkaRDD的偏移量,并将偏移量写入kafka中)
1. Spark Streaming 1.1 简介(来源:spark官网介绍) Spark Streaming是Spark Core API的扩展,其是支持可伸缩.高吞吐量.容错的实时数据流处理.Sp ...
- SparkStreaming+Kafka整合
SparkStreaming+Kafka整合 1.需求 使用SparkStreaming,并且结合Kafka,获取实时道路交通拥堵情况信息. 2.目的 对监控点平均车速进行监控,可以实时获取交通拥堵情 ...
- SparkStreaming直连方式读取kafka数据,使用MySQL保存偏移量
SparkStreaming直连方式读取kafka数据,使用MySQL保存偏移量 1. ScalikeJDBC 2.配置文件 3.导入依赖的jar包 4.源码测试 通过MySQL保存kafka的偏移量 ...
- spark第十篇:Spark与Kafka整合
spark与kafka整合需要引入spark-streaming-kafka.jar,该jar根据kafka版本有2个分支,分别是spark-streaming-kafka-0-8和spark-str ...
- 【转】Spark Streaming和Kafka整合开发指南
基于Receivers的方法 这个方法使用了Receivers来接收数据.Receivers的实现使用到Kafka高层次的消费者API.对于所有的Receivers,接收到的数据将会保存在Spark ...
- Spring Kafka整合Spring Boot创建生产者客户端案例
每天学习一点点 编程PDF电子书.视频教程免费下载:http://www.shitanlife.com/code 创建一个kafka-producer-master的maven工程.整个项目结构如下: ...
- jackson学习之三:常用API操作
欢迎访问我的GitHub https://github.com/zq2599/blog_demos 内容:所有原创文章分类汇总及配套源码,涉及Java.Docker.Kubernetes.DevOPS ...
随机推荐
- Chapter 2 Basic Elements of JAVA
elaborate:详细说明 Data TypesJava categorizes data into different types, and only certain operationscan ...
- python traceback获取详细的异常信息
运行结果 : 用try except 会报出报错信息,但是没有具体哪个地方报错,多少行,这样不利于查找报错信息 这时我们就可以使用traceback模块 运行结果: 如上图,报错信息会具体 ...
- [BZOJ1984][Luogu4315]月下“毛景树”
题目大意 给出一棵 n 个点的无根树,待边权,要求维护一下操作: 修改某条边的边权 修改点 u 到点 v 路径上所有边的边权 点 u 到点 v 路径上所有边的边权加上某个值 查询点 u 到点 v 路径 ...
- Egret--添加一个精灵事件
class Hello extends egret.DisplayObjectContainer{ //入口函数 private onAddStage(event:egret.Event){ //打开 ...
- 使用Object.prototype.toString.call()方法精确判断对象的类型
在JavaScript里使用typeof判断数据类型,只能区分基本类型,即:number.string.undefined.boolean.object. 对于null.array.function. ...
- [LeetCode] Valid Tic-Tac-Toe State 验证井字棋状态
A Tic-Tac-Toe board is given as a string array board. Return True if and only if it is possible to r ...
- Java作业三(2017-9-25)
/*程序员龚猛*/ 作业1 public class Variable_Demo$Long{ public static void main(String[]args { int i=3; long ...
- 工厂参观记:.NET Core 中 HttpClientFactory 如何解决 HttpClient 臭名昭著的问题
在 .NET Framework 与 .NET Core 中 HttpClient 有个臭名昭著的问题,HttpClient 实现了 IDispose 接口,但当你 Dispose 它时,它不会立即关 ...
- 在多个平台如何安装Python
最近的一个项目,架构师米洛需要用的mqtt,服务器开发的时候,竟然用的python脚本.运行python就需要安装开发环境,好吧,百度一下就知道了大神廖雪峰.以下部分测试通过,转载记录如下. 因为Py ...
- C博客作业01--分支,顺序结构
1.本章学习总结 1.1 思维导图 1.2本章学习体会及代码量学习体会 1.2.1学习体会 因为暑假的时候没有事先了解过C语言这门课程,翁恺老师的学习视频没看,pta习题也没有刷,所以开学后学得也蛮吃 ...