CCNet: Criss-Cross Attention for Semantic Segmentation 里的Criss-Cross Attention计算方法
论文地址:https://arxiv.org/pdf/1811.11721v1.pdf code address: https://github.com/speedinghzl/CCNet
相关论文:https://arxiv.org/pdf/1904.09229.pdf 《XLSor: A Robust and Accurate Lung Segmentor on ChestX-Rays Using Criss-Cross Attention and CustomizedRadiorealistic Abnormalities Generation》
扩展论文:https://github.com/NVlabs/MUNIT https://arxiv.org/abs/1804.04732 《Multimodal Unsupervised Image-to-Image Translation》
看第二个论文时,使用了论文一作为分割网路,论文三作为数据增强的手段。其实论文三是 style transform, pixel2pixel 最新工作,以后再看。
论文二中使用了CCNet这个新的网络结构,为了搞清楚CCA到底是怎么计算的,只能肯原始论文一:
 这就是CCA的计算方式
这就是CCA的计算方式
H是一个 C通道 宽高 W,H的特征图
从出发有四条路径,最上边的是 残差结构 或者叫shortcut path(高速通道) 目的地是和Aggregation相加 那么这里 Aggregrateion就必须和H通样的形状 C*H*W
残差结构就是公式(2)。 那个求和就是 符号部分就是Aggregation做的

要理解Aggregation就要看从H 分出的下三路
最下边一路V没什么好看的 直接对 H做1*1的卷积,输出还是 和H相同的形状 C*H*W
Q,K也是1*1卷积 只不过 通道数量是: C' < C 。
Q和K都是 C'*H*W 大小的特征图
下边就是高能的Affinity, 可以看到affinity后softmax得到A ,而A的结构是 (W+H-1)*W*H
A有 W+H-1个通道,所以Affinit后的结构也是 (W+H-1)*W*H
因为 A 和 Q K 的宽度和高度相同。每个位置u,u可以认为是二维特征图w,h上的一个像素。
由于CNN的对称性。只需要关注某一个位置u的计算方式即可。
这时候我们拿Q 上的一个位置 u ,我们知道在u这个位置看下去 是一个 C' 维度的向量。 记作Qu 维度 C‘
这时候要A中对应u的地方应该是由 Qu 和 K作用而来 ,由于A对应的维度是 (W+H-1)维
W+H-1 刚好是位置u 所在 行数+列数 方向的像元总数,自己算了两次减去一次。 就是下图中十字的形状。这个十字形状
就是H+W-1
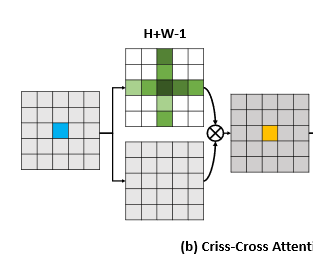
那么从向量 Qu 和 K中的 H+W-1个向量 需要得到一个 (H+w-1)的向量
因为 Qu 和 K中的向量维度相同 我们把K中的H+W-1个向量 编号为 Ku1 ku2, ku(h+w-1)
那么 Au= ((Qu* Ku1 , Qu*Ku2, Qu*Ku3, Qu*Ku4, ... ,... Qu*Ku(h+w-1)) 就是这样 Qu*Kui 表示 Qu和Kui的内积
其实这样算完之后还在通道方向做了个softmax。
这样就算把A算完了
A最终得到的形状是 (H+W-1)*H*W 每个通道表示attention 因为经过softmax了,就是概率了。
接下来就是A和V的结合 Aggregation ,就是公式2的 求和部分
V的通道数是 C
那么这个和上边的操作有点像,这次只不过从内积变成了 线性组合
这里方便起见以A为中心,
对应于位置u
从A看下去是 H+W-1维的向量
V中对应位置 u,同样找到过他的横竖两条线段,同样是个十字形状有 H+W-1个向量 每个向量是 C维
这时候 用A中的 向量作为系数, 作用到 V中的H+W-1个向量 加起来,就是线性组合啊。 得到一个 C维的向量,这个向量是V中十字领域向量的线性组合
这样Aggreation就是2是中的 求和一项做的完成 Aggreation。
以上就是CCA, 作者还证明了 两个CCA就能够获取全局视野。不看了我。
效果很好,取得很好的结果。
CNN发明以来,各种矩阵操作。
问题是Aggregation部分不就是个卷积吗,十字形状的卷积。
通常的卷积是同位置不同通道的卷积的参数不同。
这个整的是不同位置的卷积核不同,但是在通道上相同。
汗啊,CNN快要被玩坏了。
CCNet: Criss-Cross Attention for Semantic Segmentation 里的Criss-Cross Attention计算方法的更多相关文章
- Semantic Segmentation on Remotely Sensed Images Using an Enhanced Global Convolutional Network with Channel Attention and Domain Specific Transfer Learning
创新点: 1.在GCN(global convolutional network)基础上,把他的backbone替换成更多层的,使其适应中分辨率影像,resnet50,101,152 2.利用 cha ...
- Fully Convolutional Networks for semantic Segmentation(深度学习经典论文翻译)
摘要 卷积网络在特征分层领域是非常强大的视觉模型.我们证明了经过端到端.像素到像素训练的卷积网络超过语义分割中最先进的技术.我们的核心观点是建立"全卷积"网络,输入任意尺寸,经过有 ...
- 目标检测--Rich feature hierarchies for accurate object detection and semantic segmentation(CVPR 2014)
Rich feature hierarchies for accurate object detection and semantic segmentation 作者: Ross Girshick J ...
- Adversarial Examples for Semantic Segmentation and Object Detection 阅读笔记
Adversarial Examples for Semantic Segmentation and Object Detection (语义分割和目标检测中的对抗样本) 作者:Cihang Xie, ...
- Decoders Matter for Semantic Segmentation:Data-Dependent Decoding Enables Flexible Feature Aggregation
Decoders Matter for Semantic Segmentation:Data-Dependent Decoding Enables Flexible Feature Aggregati ...
- semantic segmentation 和instance segmentation
作者:周博磊链接:https://www.zhihu.com/question/51704852/answer/127120264来源:知乎著作权归作者所有,转载请联系作者获得授权. 图1. 这张图清 ...
- 【Semantic Segmentation】 Instance-sensitive Fully Convolutional Networks论文解析(转)
这篇文章比较简单,但还是不想写overview,转自: https://blog.csdn.net/zimenglan_sysu/article/details/52451098 另外,读这篇pape ...
- 【Semantic segmentation】Fully Convolutional Networks for Semantic Segmentation 论文解析
目录 0. 论文链接 1. 概述 2. Adapting classifiers for dense prediction 3. upsampling 3.1 Shift-and-stitch 3.2 ...
- Convolutional Networks for Image Semantic Segmentation
本系列文章由 @yhl_leo 出品,转载请注明出处. 文章链接: http://blog.csdn.net/yhl_leo/article/details/52857657 把前段时间自己整理的一个 ...
随机推荐
- 查询数据库游标使用情况以及sql
----查询游标使用情况以及游标最大数---- SELECT MAX(A.VALUE) AS HIGHEST_OPEN_CUR, P.VALUE AS MAX_OPEN_CUR FROM V$SESS ...
- linux 清理几天前的日志或文件
执行清理1天前的 war 包 find . -ctime +1 -name "*.war" -exec rm {} \;
- Shell test 命令
Shell中的 test 命令用于检查某个条件是否成立,它可以进行数值.字符和文件三个方面的测试. 数值测试 参数 说明 -eq 等于则为真 -ne 不等于则为真 -gt 大于则为真 -ge 大于等于 ...
- Java面试题集锦(持续更新)
1.面向对象的特征有哪些方面? 答:面向对象的特征主要有以下几个方面: -抽象:抽象是将一类对象的共同特征总结出来构造类的过程,包括数据抽象和行为抽象两方面.抽象只关注对象有哪些属性和行为,并不关注这 ...
- tcl实现批量压缩文件夹
tcl脚本本身对字符串的处理比较简单,所以想着用这个也实现下: proc main {} { puts "请输入路径:" set strpath "E:\\123&quo ...
- Mysql 设置远程连接
一.问题分析 有时候使用数据库远程连接工具连接MySQL的时候总是连接不上,确认过账号密码正确,端口telnet端口又是通的. Navicat Premium报错如下: 1130 - Host '19 ...
- re模块基本用法和字符集
import re # . 能够替代任意字符 r= re.findall("a..c","abbcsd") print(r) # ^ 找最前面的 r_1 = r ...
- LimeSDR 无线信号重放攻击和逆向分析
原文链接:https://mp.weixin.qq.com/s/TBYKZR3n3ADo4oDkaDUeIA
- CSS效果:checkbox点选效果
HTML: <html lang="en"> <head> <meta charset="UTF-8"> <meta ...
- My new Blog on cnblogs
My New Blog 这是菜鸡Herself32在博客园新开的Blog,一部分文章会同时加载到这里. 也欢迎访问主站:https://herself32.github.io QwQ