【Spark篇】---Spark中Master-HA和historyServer的搭建和应用
一、前述
本节讲述Spark Master的HA的搭建,为的是防止单点故障。
Spark-UI 的使用介绍,可以更好的监控Spark应用程序的执行。
二、具体细节
1、Master HA
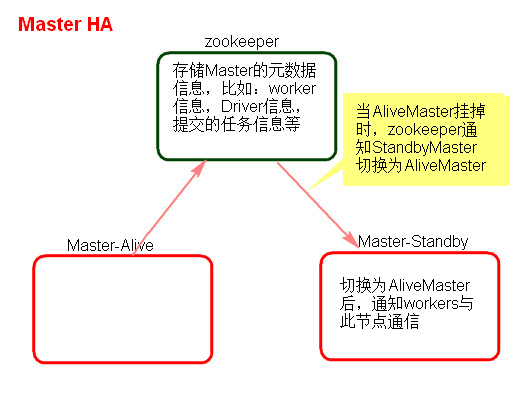
1、Master的高可用原理
Standalone集群只有一个Master,如果Master挂了就无法提交应用程序,需要给Master进行高可用配置,Master的高可用可以使用fileSystem(文件系统)和zookeeper(分布式协调服务)。
fileSystem只有存储功能,可以存储Master的元数据信息,用fileSystem搭建的Master高可用,在Master失败时,需要我们手动启动另外的备用Master,这种方式不推荐使用。
zookeeper有选举和存储功能,可以存储Master的元素据信息,使用zookeeper搭建的Master高可用,当Master挂掉时,备用的Master会自动切换,推荐使用这种方式搭建Master的HA。
2、Master高可用搭建
1) 在Spark Master节点上配置主Master,配置spark-env.sh
命令如下:-D指明配置
export SPARK_DAEMON_JAVA_OPTS="-Dspark.deploy.recoveryMode=ZOOKEEPER -Dspark.deploy.zookeeper.url=node02:2181,node03:2181,node04:2181 -Dspark.deploy.zookeeper.dir=/sparkmaster0821

2) 发送到其他worker节点上
scp spark-env.sh root@node03:`pwd`
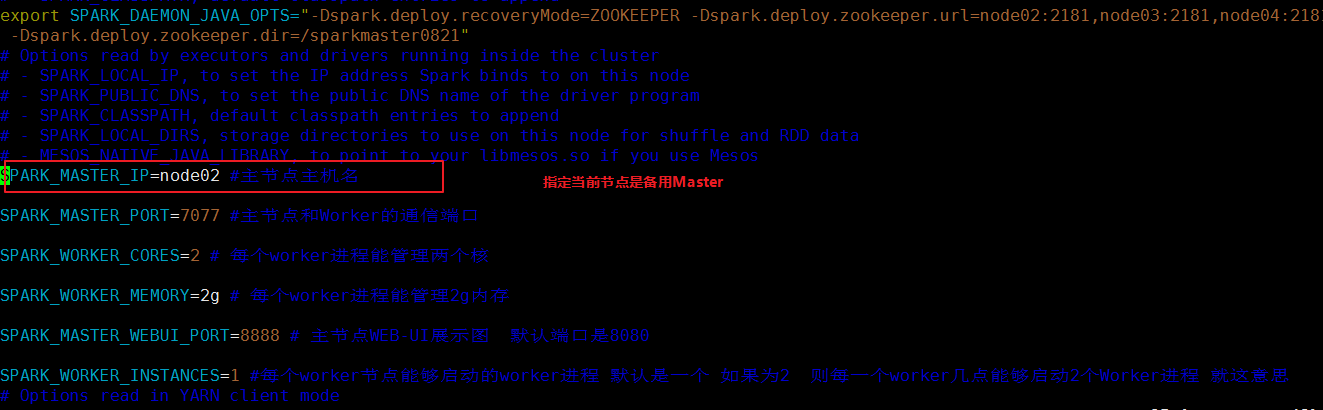
3) 找一台节点(非主Master节点)配置备用 Master,修改spark-env.sh配置节点上的MasterIP:
4) 启动集群之前启动zookeeper集群
5) 在主节点上启动spark Standalone集群:./start-all.sh 在从节点上(node02)启动备用集群:在saprk的Sbin目录下启动备用节点:./start-master.sh
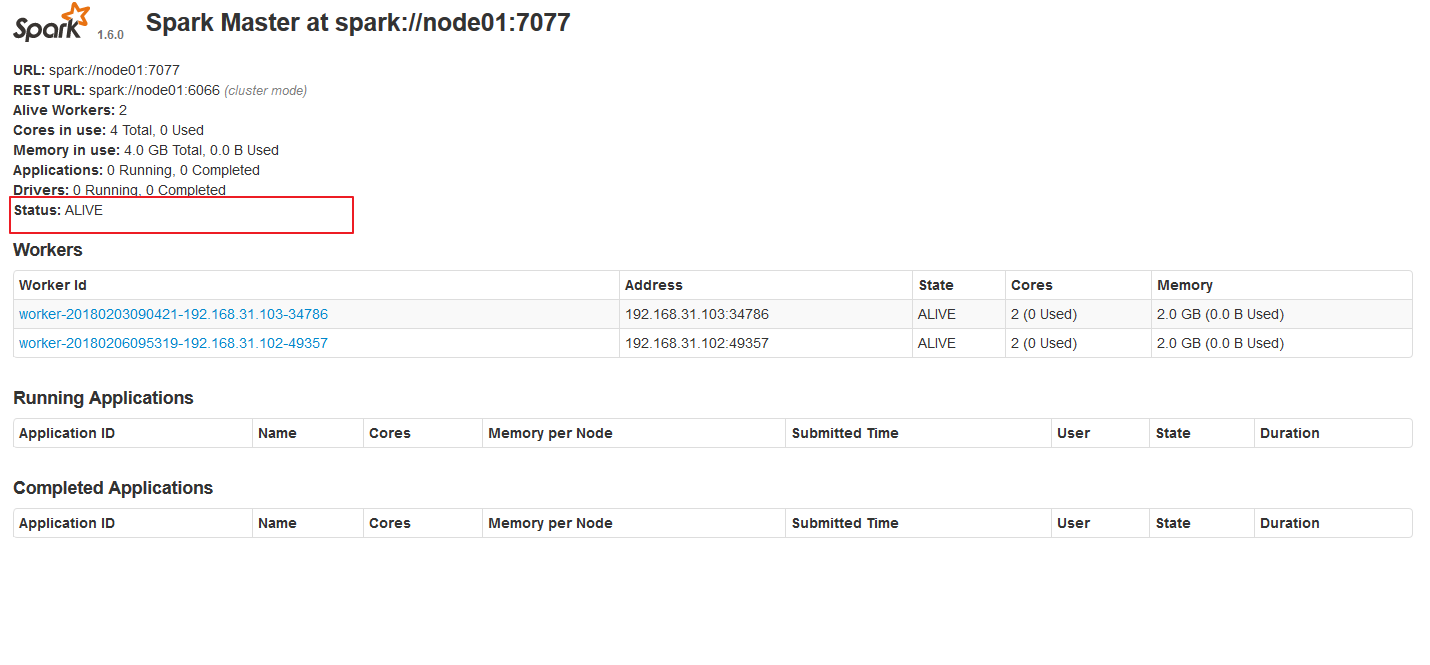
6) 打开主Master和备用Master WebUI页面,观察状态。
主master :
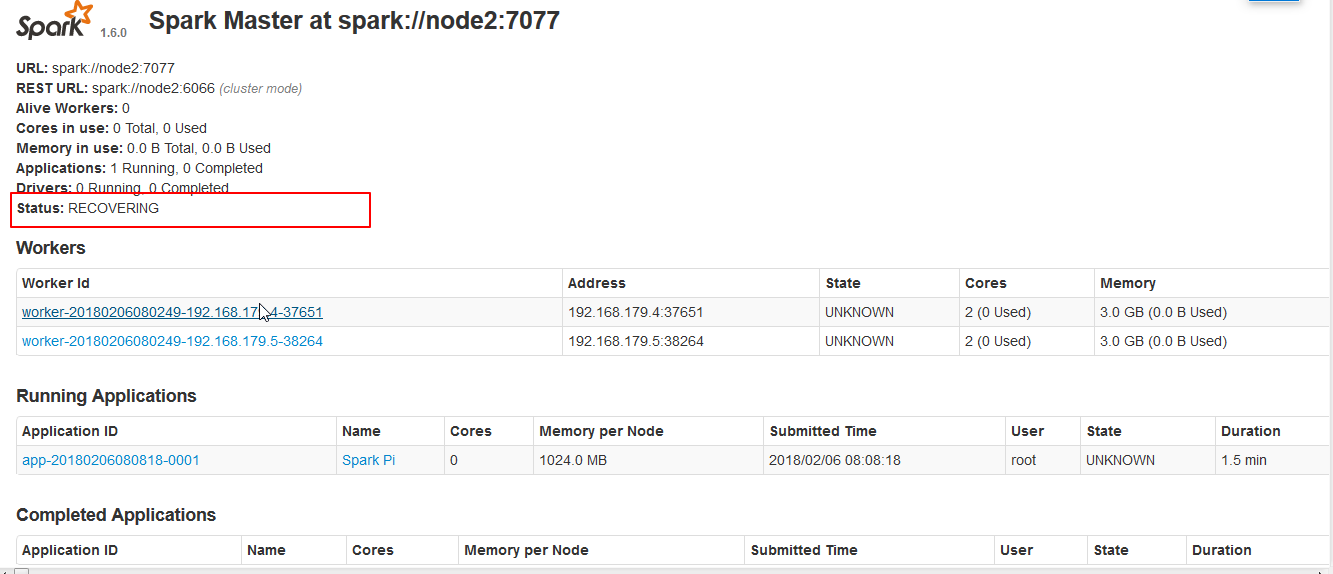
备用Master

切换过程中的Master的状态:
注意:
- 主备切换过程中不能提交Application。
- 主备切换过程中不影响已经在集群中运行的Application。因为Spark是粗粒度资源调,二主要task运行时的通信是和Driver 与Driver无关。
提交SparkPi程序应指定主备Master
./spark-submit --master spark://node01:7077,node02:7077 --class org.apache.spark.examples.SparkPi ../lib/spark-examples-1.6.0-hadoop2.6.0.jar 10000
2、配置historyServer
1、临时配置,对本次提交的应用程序起作用
./spark-shell --master spark://node1:7077
--name myapp1
--conf spark.eventLog.enabled=true
--conf spark.eventLog.dir=hdfs://node1:9000/spark/test
停止程序,在Web Ui中Completed Applications对应的ApplicationID中能查看history。
2、spark-default.conf配置文件中配置HistoryServer,对所有提交的Application都起作用
在客户端节点!!!,进入../spark-1.6.0/conf/ spark-defaults.conf最后加入:
//开启记录事件日志的功能
spark.eventLog.enabled true
//设置事件日志存储的目录
spark.eventLog.dir hdfs://node1:9000/spark/test
//设置HistoryServer加载事件日志的位置
spark.history.fs.logDirectory hdfs://node1:9000/spark/test
//日志优化选项,压缩日志
spark.eventLog.compress true
3、启动HistoryServer:./start-history-server.sh
访问HistoryServer:node4:18080,之后所有提交的应用程序运行状况都会被记录。
4040 Driver-web-UI对应端口
8081 Worker对应端口
【Spark篇】---Spark中Master-HA和historyServer的搭建和应用的更多相关文章
- [Spark内核] 第29课:Master HA彻底解密
本课主题 Master HA 解析 Master HA 解析源码分享 [引言部份:你希望读者看完这篇博客后有那些启发.学到什么样的知识点] 更新中...... Master HA 解析 生产环境下一般 ...
- Spark技术内幕:Master基于ZooKeeper的High Availability(HA)源码实现
如果Spark的部署方式选择Standalone,一个采用Master/Slaves的典型架构,那么Master是有SPOF(单点故障,Single Point of Failure).Spark可以 ...
- 【Spark-core学习之三】 Spark集群搭建 & spark-shell & Master HA
环境 虚拟机:VMware 10 Linux版本:CentOS-6.5-x86_64 客户端:Xshell4 FTP:Xftp4 jdk1.8 scala-2.10.4(依赖jdk1.8) spark ...
- Spark技术内幕:Master基于ZooKeeper的High Availability(HA)源代码实现
假设Spark的部署方式选择Standalone,一个採用Master/Slaves的典型架构,那么Master是有SPOF(单点故障,Single Point of Failure).Spark能够 ...
- 【原】Spark中Master源码分析(二)
继续上一篇的内容.上一篇的内容为: Spark中Master源码分析(一) http://www.cnblogs.com/yourarebest/p/5312965.html 4.receive方法, ...
- 【Spark 深入学习 -09】Spark生态组件及Master节点HA
----本节内容------- 1.Spark背景介绍 2.Spark是什么 3.Spark有什么 4.Spark部署 4.1.Spark部署的2方面 4.2.Spark编译 4.3.Spark St ...
- 【Spark篇】---Spark中yarn模式两种提交任务方式
一.前述 Spark可以和Yarn整合,将Application提交到Yarn上运行,和StandAlone提交模式一样,Yarn也有两种提交任务的方式. 二.具体 1.yarn-clien ...
- <spark> error:启动spark后查看进程,进程中master和worker进程冲突
启动hadoop再启动spark后jps,发现master进程和worker进程同时存在,调试了半天配置文件. 测试发现,当我关闭hadoop后 worker进程还是存在, 但是,当我再关闭spark ...
- Spark中文指南(入门篇)-Spark编程模型(一)
前言 本章将对Spark做一个简单的介绍,更多教程请参考:Spark教程 本章知识点概括 Apache Spark简介 Spark的四种运行模式 Spark基于Standlone的运行流程 Spark ...
随机推荐
- sqlserver2008 批量插入数据
private DataTable GetTableSchema() { DataTable dt = new DataTable(); dt.Columns.AddRange(new DataCol ...
- js中比较两个数组中是否含有相同的元素,可去重,可删除合并为新数组(转载)
//做比较的两个数组 var array1 = ['a','b','c','d','e'];//数组1 var array2 = ['d','f','e','a','p'];//数组2 //临时数组存 ...
- windows jdk安装
先去官网下载安装包 x86 32位 x64 64位 下载地址 安装jdk 安装目录默认c盘 配置系统环境 JAVA_HOME环境变量.作用:它指向jdk的安装目录,Eclipse/NetBeans/T ...
- pycharm 记录
一.pycharm字体放大.缩小的设置 File —> setting —> Keymap —>在搜寻框中输入:increase —> Increase Font Size(双 ...
- java使用Jedis远程访问CentOs7linux时出现拒绝连接的错误
使用Jedis出现Connection refused的解决方案 当我们利用Jedis操作服务器的Redis数据库时,需要先将远程服务器的端口(默认端口是6379)开放,命令如下: #/sbin/ ...
- BZOJ5465 : [APIO 2018] 选圆圈
假设最大的圆半径为$R$,以$2R$为大小将地图划分为一个个格子,那么每个圆只需要检查圆心在附近$9$个格子内部的所有圆. 在当前圆的半径不足$\frac{R}{2}$时重构网格,那么最多重构$O(\ ...
- WinForm的.Designer.cs代码内抛反射异常
今天在项目内一个Winform增加控件后,无法打开,抛如下异常. System.Reflection.TargetInvocationException: Exception has been thr ...
- react-router路由地址变了页面却没有跳转的解决办法
最近,自己在摸索react的时候,遇到一个很奇葩的问题,大概是这样的: 我从列表页使用Link跳转到详情页面,列表页面的路由是'/list',详情页面的路由是'/list/detail',由于详情页面 ...
- 微信小程序中的AJAX——POST,GET区别
注意:发送服务器时的DATA 最终发送给服务器的数据是 String 类型,如果传入的 data 不是 String 类型,会被转换成 String .转换规则如下: 对于 GET 方法的数据,会将数 ...
- iptables安装
1.安装iptable iptable-service #先检查是否安装了iptables service iptables status #安装iptables yum install -y ipt ...