Java集合框架体系JCF
Java 集合框架体系作为Java 中十分重要的一环, 在我们的日常开发中扮演者十分重要的角色, 那么什么是Java集合框架体系呢?
- 在Java语言中,Java语言的设计者对常用的数据结构和算法做了一些规范(接口)和实现(具体实现接口的类)。所有抽象出来的数据结构和操作(算法)统称为Java集合框架(Java CollectionFramework)。
- Java程序员在具体应用时,不必考虑数据结构和算法实现细节,只需要用这些类创建出来一些对象,然后直接应用就可以了,这样就大大提高了编程效率。
我们来看个Java 的集合体系框架图 :
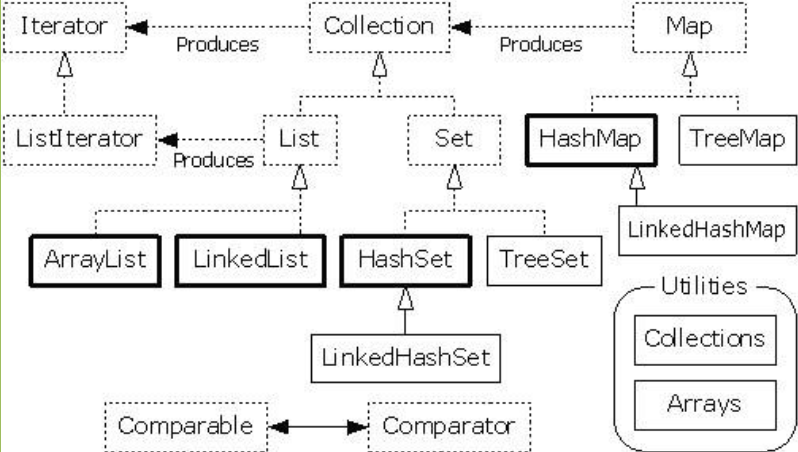
加粗的部分是我们常用的比较重要的集合类型。 集合体系我们常常有一个大的层次 叫Collection 。
Collection 为层次结构中的根接口。Collection 表示一组对象,这些对象也称为 collection 的元素。一些 collection 允许有重复的元素,而另一些则不允许。一些 collection 是有序的,而另一些则是无序的。JDK 不提供此接口的任何直接 实现:它提供更具体的子接口(如 Set 和 List)实现。此接口通常用来传递 collection,并在需要最大普遍性的地方操作这些 collection。
Colltction 为根接口 其下有四个常用子接口 分别为 List ,Set ,Map,Collections。
List
API 上 是这样表示的

特征:
list 是一种有序的(存储顺序和取出顺序一致)允许重复的集合类,有序的 collection(也称为序列)。此接口的用户可以对列表中每个元素的插入位置进行精确地控制。用户可以根据元素的整数索引(在列表中的位置)访问元素,并搜索列表中的元素。
List的常用实现类可分为:
1. ArrayList
其底层是基于动态数组的序列。基于线程不安全的,底层使用数组实现,所以查询快(下标直接定位),增删慢(数组特性,所以要挨个修改下标)。效率高。每次容量不足时,自增长度的一半。初始长度java6为10,java7更改为0。 底层增长方式源码为:
int newCapacity = oldCapacity + (oldCapacity >> 1);
ArrayList是一个基于数组的可变长度的容器,实现了所有可选列表操作,并允许包括 null 在内的所有元素。除了实现 List 接口外,此类还提供一些方法来操作内部用来存储列表的数组的大小。(此类大致上等同于 Vector 类,除了此类是不同步的)。
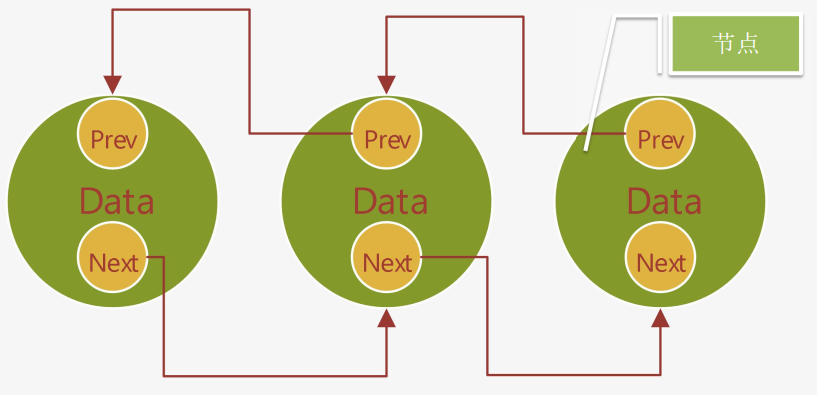
2. LinkedList
线程不安全,底层使用双向链表实现,所以查询慢(挨个一层一层的查找),增删快(只需要修改指针)。效率高。
我们来看一个双向链表结构图 :
int newCapacity = oldCapacity + ((capacityIncrement > 0) ?
capacityIncrement : oldCapacity);
Set
还是看看API 的表述;

特征:
核心 是 : 集
无序,去重,允许一个null 。
SET 是元素唯一的 ,不包含重复元素的 Collection类 。更确切地讲,Set不包含满足 e1.equals(e2) 的元素对 e1 和 e2,并且最多包含一个 null 元素。
Set 常用实现类可分为:
1. HashSet
底层是HashMap的key,所以特点是:
1 . 不会按照存放顺序排序,但会按照自己的算法排序,
2 . 去重
3 . 允许一个null 。
其增长方式,默认大小,最大长度和HashMap一致。
元素无下标。
HashSet 的去重问题:
我们知道HashSet在存放对象的时候会判断对象时候是同一对象。
默认引用类型比较的是地址值,如果地址值相同,那么这是一模一样的对象,那么判断肯定是同一对象,就不再重复的往里放。
如果对象重写了hashcode和equals方法,就比较这二者是否相等。
如果hashcode相等,那么比较equals方法,如果equals再相等,那么证明这是同一个对象;如果equals不相等,那么及时hashcode相等,也是两个对象。
所以得证:
如果equals不相等,那么hashcode可能相等;
如果equals相等,那么hashcode一定相等。
如果hashcode相等,那么equals可能相等;
如果hashcode不相等,那么equals一定不相等。
去重条件: 1. 两个对象的HashCode一致。 2 .两个对象的equals方法返回true 。
Set里的元素是不能重复的,所以我们 用iterator()方法来区分重复与否。equals()是判读两个Set是否相等。
=是用来判断两者是否是同一对象(同一事物),而equals是用来判断是否引用同一个对象。
equals()和==方法决定引用值是否指向同一对象 equals()在类中被覆盖,为的是当两个分离的对象的内容和类型相配的话,返回真值。
==号在比较基本数据类型时比较的是值,而用==号比较两个对象(引用)时比较的是两个对象的地址值:
equals()方法存在于Object类中,因为Object类是所有类的直接或间接父类,也就是说所有的类中的equals()方法都继承自Object类,而通过源码我们发现,Object类中equals()方法底层依赖的是==号,那么,在所有没有重写equals()方法的类中,调用equals()方法其实和使用==号的效果一样,也是比较的地址值,然而,Java提供的所有类中,绝大多数类都重写了equals()方法,重写后的equals()方法一般都是比较两个对象的值。
判断两个对象在逻辑上是否相等,如根据类的成员变量来判断两个类的实例是否相等,而继承Object中的equals方法只能判断两个引用变量是否是同一个对象。这样我们往往需要重写equals()方法。我们向一个没有重复对象的集合中添加元素时,集合中存放的往往是对象,我们需要先判断集合中是否存在已知对象,这样就必须重写equals方法。
值相同,指的应该是equals()方法返回的是true ,可以说,值相同决定不了hashcode相同;但hashcode相同则可以决定值相同。
当向集合Set中增加对象时,首先集合计算要增加对象的hashCode码,根据该值来得到 一个位置用来存放当前对象。 如果在该位置没有一个对象存在的话,那么集合Set认为该对象在集合中不存在,直接 增加进去。 如果在该位置有一个对象存在的话,接着将准备增加到集合中的对象与该位置上的对象 进行equals方法比较。 如果该equals方法返回false,那么集合认为集合中不存在该对象,再进行一次散列, 将该对象放到散列后计算出来的地址中。 如果equals方法返回true,那么集合认为集合中已经存在该对象了,不再将该对象增加到集合中。 2 重写equals方法的时候必须重写hashCode方法。如果一个类的两个对象,使用equals 方法比较时,结果为true,那么这两个对象具有相同的hashCode。原因是equals方法为true,表明是同一个对象,它们的hashCode当然相同。(Object类的equals方法比较的是地址) 3 Object类的hashCode方法返回的是Object对象的内存地址。我们可以通过Integer.toHexString(newObject().hashCode());来得到。
所以Java里面的hashSet中,如何判断两个对象是否相等?
a. 判断两个对象的hashCode是否相等。 如果不相等,认为两个对象不相等。完毕 如果相等,转入下面一步
b. 判断两个对象是否equals 如果不相等,认为两个对象不相等。 如果相等,认为两个对象相等hashcode 相同 一定值相同,一定是同一个对象, 值相同(equals方法为true) ,不一定对象相同,指向的不一定是同一个对象。
2 .TreeSet
底层实现二叉树,由于二叉树的特性,所以TreeSet 是一个有序的集。
特征:
1 . 按照字典排序,
2. 去重
3. 元素无下标
Map
- 将键映射到值的对象。一个映射不能包含重复的键;每个键最多只能映射一个值。
- 此接口代替 Dictionary 类,后者完全是一个抽象类,而不是一个接口。
- Map 接口提供三种collection 视图,允许以键集、值集合或键-值映射关系集的形式查看某个映射的内容。映射的顺序 定义为迭代器在映射的 collection 视图中返回其元素的顺序。某些映射实现可明确保证其顺序,如 TreeMap 类;某些映射实现则不保证顺序,如 HashMap类。
Map核心实现为接口中的接口 :

Entry方法摘要

Map 中的常用实现类:
1 .HashMap
底层实现:依赖于实现了Map.Entry接口的节点
特征:允许一个空键和多个空值,非线程同步,默认大小16
增长方式:取决于增长因子,默认增长因子为0.75F,增长方式: newThr = oldThr << 1;
最大长度:MAXIMUM_CAPACITY = 1 << 30
2. HashTable
特征: 不允许空键和空值,线程同步, 默认大小11
增长方式: 增长方式:old*2+1;
最大长度: MAXIMUM_CAPACITY = 1 << 30
Collections
此类完全由在 collection 上进行操作或返回 collection 的静态方法组成。它包含在 collection 上操作的多态算法,即“包装器”,包装器返回由指定 collection 支持的新 collection,以及少数其他内容。
换个说法:Collections是个java.util下的类,它包含有各种有关集合操作的静态方法。 Collection是个java.util下的接口,它是各种集合结构的父接口。
下面演示一下Map集合的遍历:
因为Map 的特性使得我们不能像数组那样进行for 循环遍历, 那么Map 集合我们如何遍历呢?
举个栗子:
public class collectionMap {
public static void main(String[] args) {
Map<String,Student> studentmap = new HashMap<String,Student>();
System.out.println("添加元素前长度: "+studentmap.size());
studentmap.put("001", new Student("张三", 22, "man"));
studentmap.put("002", new Student("李四", 21, "man"));
studentmap.put("003", new Student("王五", 23, "woman"));
System.out.println("添加元素后长度: "+studentmap.size());
// 遍历 key
for(String key:studentmap.keySet()){
System.out.println(key);
}
// 遍历map的value
for(Student stu:studentmap.values()){
System.out.println(stu);
}
// 遍历键值对 entry 是map的方法 ,是一个key,对应一个value 数组
Set<Map.Entry<String, Student>>entries =studentmap.entrySet();
for(Entry<String, Student> stu:entries){
System.out.println(stu.getKey()+"\t"+stu.getValue());
}
}
Map遍历的集中方式:
public class TestMap {
public static void main(String[] args) {
Map<Integer, String> map = new HashMap<Integer, String>();
map.put(1, "a");
map.put(2, "b");
map.put(3, "ab");
map.put(4, "ab");
map.put(4, "ab");
// 和上面相同 , 会自己筛选 System.out.println(map.size());
// 第一种:
Set<Integer> set = map.keySet(); //得到所有key的集合
for (Integer in : set) {
String str = map.get(in);
System.out.println(in + " " + str);
}
System.out.println("第一种:通过Map.keySet遍历key和value:");
for (Integer in : map.keySet()) {
//map.keySet()返回的是所有key的值
String str = map.get(in);//得到每个key多对用value的值
System.out.println(in + " " + str);
}
// 第二种:
System.out.println("第二种:通过Map.entrySet使用iterator遍历key和value:");
Iterator<Map.Entry<Integer, String>> it =map.entrySet().iterator();
while (it.hasNext()) {
Map.Entry<Integer, String> entry = it.next();
System.out.println("key= " + entry.getKey() + " and value= " + entry.getValue());
}
// 第三种:推荐,尤其是容量大时35
System.out.println("第三种:通过Map.entrySet遍历key和value");
for (Map.Entry<Integer, String> entry : map.entrySet()) {
//Map.entry<Integer,String> 映射项(键-值对) 有几个方法:用上面的名字entry
//entry.getKey() ;entry.getValue(); entry.setValue();
//map.entrySet() 返回此映射中包含的映射关系的 Set视图。
System.out.println("key= " + entry.getKey() + " and value= "+ entry.getValue());
}
// 第四种: System.out.println("第四种:通过Map.values()遍历所有的value,但不能遍历key");
for (String v : map.values()) {
System.out.println("value= " + v);
}
}
}
Java集合框架体系JCF的更多相关文章
- Java 集合框架体系总览
尽人事,听天命.博主东南大学硕士在读,热爱健身和篮球,乐于分享技术相关的所见所得,关注公众号 @ 飞天小牛肉,第一时间获取文章更新,成长的路上我们一起进步 本文已收录于 「CS-Wiki」Gitee ...
- Java集合框架体系详细梳理,含面试知识点。
一.集合类 集合的由来: 面向对象语言对事物都是以对象的形式来体现,为了方便对多个对象的操作,就需要将对象进行存储,集合就是存储对象最常用的一种方式. 集合特点: 1,用于存储对象的容器.(容器本身就 ...
- Java入门系列(七)Java 集合框架(JCF, Java Collections Framework)
Java 集合概述 List.Set.Map可以看做集合的三大类 java集合就像一个容器,可以将多个对象的引用丢进该容器中. Collection和Map是java集合的根接口. List List ...
- java集合框架体系
Collection接口: 1.单列集合类的根接口. 2.定义了可用于操作List.Set的方法——增删改查: 3.继承自Iterable<E>接口,该接口中提供了iterator() 方 ...
- Java集合框架使用总结
Java集合框架使用总结 前言:本文是对Java集合框架做了一个概括性的解说,目的是对Java集合框架体系有个总体认识,如果你想学习具体的接口和类的使用方法,请参看JavaAPI文档. 一.概述数据结 ...
- Java集合框架之Set接口浅析
Java集合框架之Set接口浅析 一.java.util.Set接口综述: 这里只对Set接口做一简单综述,其具体实现类的分析,朋友们可关注我后续的博文 1.1Set接口简介 java.util.se ...
- Java集合框架(常用类) JCF
Java集合框架(常用类) JCF 为了实现某一目的或功能而预先设计好一系列封装好的具有继承关系或实现关系类的接口: 集合的由来: 特点:元素类型可以不同,集合长度可变,空间不固定: 管理集合类和接口 ...
- Java集合框架介绍。Java Collection Frameworks = JCF
Java集合框架 = Java Collection Frameworks = JCF . 为了方便理解,我画了一张思维脑图.
- java集合类-集合框架体系
集合框架体系 集合框架体系是由Collection.Map和 Iterator(迭代器) 实线边框的是实现类,折线边框的是抽象类,而点线边框的是接口 Collection体系 Set接口:元素无序且不 ...
随机推荐
- powerDesigner生成数据结构图以及对应sql导出方法
1.下载powerDesigner 链接地址为http://soft.onlinedown.net/soft/577763.htm 2.打开软件,file -> new project,新建一个 ...
- 微信小程序去除Button默认样式
在小程序开发过程中,使用率蛮高的组件button,因为经常要去除默认样式,然后再自定义样式,所以经常写,自己也总结分享一下简单的实现步骤. (一)实现效果1.实现前(默认样式): 2.实现后(去除默认 ...
- 使用 docker-compose 快速安装Jenkins
本文分享在 docker 环境中,使用 docker-compose.yml 快速安装 Jenkins,以及使用主机中的 docker 打包推送镜像到阿里云 博客园的第100篇文章达成,2019的第一 ...
- linux中使用docker-compose部署软件配置分享
本篇将分享一些 docker-compose 的配置,可参考其总结自己的一套基于docker的开发/生产环境配置. 安装docker及docker-compose install docker cur ...
- Activity 之使用
Activity 之使用 本文内容 1. 使用 Activity 显式简单界面 2. Activity 之间的跳转 2.1 startActivity 2.3 startActivityForResu ...
- CentOS7 安装mysql 5.7
一.安装准备 检查系统中是否安装了mysqlrpm -qa|grep mysql如果有安装mysql,则需要先卸载之前安装的mysqlyum -y remove mysql然后再查看mysql是否都卸 ...
- [翻译]Java排错指南 - 5 确定崩溃何地发生
原文地址: https://docs.oracle.com/javase/8/docs/technotes/guides/troubleshoot/crashes001.html 这几天公司其他组遇到 ...
- MacBook IDEA激活码(附视频)
Windows激活请看这里:IDEA激活码 此教程实时更新,请放心使用:如果有新版本出现猪哥都会第一时间尝试激活: idea官网下载地址:https://www.jetbrains.com/idea/ ...
- python学习第八讲,python中的数据类型,列表,元祖,字典,之字典使用与介绍
目录 python学习第八讲,python中的数据类型,列表,元祖,字典,之字典使用与介绍.md 一丶字典 1.字典的定义 2.字典的使用. 3.字典的常用方法. python学习第八讲,python ...
- 只需两步!Eclipse+Maven快速构建第一个Spring Boot项目
随着使用Spring进行开发的个人和企业越来越多,Spring从一个单一简介的框架变成了一个大而全的开源软件,最直观的变化就是Spring需要引入的配置也越来越多.配置繁琐,容易出错,让人无比头疼, ...