Scrapy-redis<数据库篇>
scrapy-redis爬虫数据库连接部分——windows准备做salve,Linux准备做master开展工作
首先处理简单的windows熟悉的环境——安装Redis服务和Redis可视化~可视化也可以省略,但作为新手推荐使用:
1、安装redis服务:链接: https://pan.baidu.com/s/1EA0I-gx9NEU78vjZeZVqJA 提取码: 4s4i ——直接next下去
2、安装redis可视化:链接: https://pan.baidu.com/s/1KQh_g2o0tQijHQRFpKjcng 提取码: ny9c
安装redis可视化~:
1、确保redis安装完成,确保redis服务正常开启
2、正常打开界面:
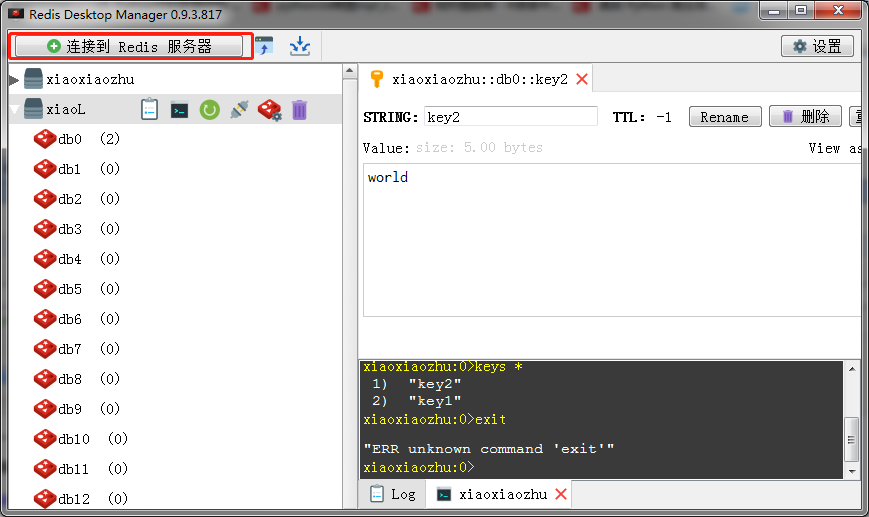

名字自定义~
验证为redis的密码~安装之后默认是空的就是这个——requirepass,直接连接,即可连接上windows本地的redis数据库
然后进行测试即可,测试详细内容百度。
不安装可视化的~就直接redis操作即可。
接下来是Linux服务里面安装redis:https://redis.io/download

安装完之后~直接进入redis-5.0.4文件夹:cd redis-5.0.4——>修改redis.conf文件:gedit redis.conf
修改三个属性:1.注释bind 127.0.0.1,以便其它ip访问,2.修改protected-mode yes,该改为no,3.设置密码 requirepass,默认是注释掉的,打开后设置密码。Over!
然后开始服务:sec/redis-server redis.conf
如果访问不了:
1、在linux下的防火墙中开放6379端口(与centos7以下版本开放端口的方式有区别):firewall-cmd --zone=public --add-port=6379/tcp --permanent
2、重启防火墙:systemctl restart firewalld
3、启动redis:src/redis-server redis.conf
此时开始测试:打开另一个黑窗口,进入redis文件夹,输入:src/redis-cli,回车,先输入keys *,出现: ,则输入你的密码即可:auth "密码";
,则输入你的密码即可:auth "密码";
这时候无错误情况下Linux下的Redis安装完成。
直接进入RedisDesktop里面连接服务,需要输入Linux的ip地址,Linux的ip地址查询:ifconfig -a ,windows的ip地址查询:ipconfig;
名字自取——ip地址输入——端口输入正确,无改变的情况下是6379——输入redis设置的密码;
结束windows下连接Linux下redis服务
Scrapy-redis<数据库篇>的更多相关文章
- 基于Python,scrapy,redis的分布式爬虫实现框架
原文 http://www.xgezhang.com/python_scrapy_redis_crawler.html 爬虫技术,无论是在学术领域,还是在工程领域,都扮演者非常重要的角色.相比于其他 ...
- Scrapy+redis实现分布式爬虫
概述 什么是分布式爬虫 需要搭建一个由n台电脑组成的机群,然后在每一台电脑中执行同一组程序,让其对同一网络资源进行联合且分布的数据爬取. 原生Scrapy无法实现分布式的原因 原生Scrapy中调度器 ...
- scrapy+redis去重实现增量抓取
class ProjectnameDownloaderMiddleware(object): # Not all methods need to be defined. If a method is ...
- 爬虫--scrapy+redis分布式爬取58同城北京全站租房数据
作业需求: 1.基于Spider或者CrawlSpider进行租房信息的爬取 2.本机搭建分布式环境对租房信息进行爬取 3.搭建多台机器的分布式环境,多台机器同时进行租房数据爬取 建议:用Pychar ...
- Redis与Scrapy
Redis与Scrapy Redis与Scrapy Redis is an open source, BSD licensed, advanced key-value cache and store. ...
- python - scrapy 爬虫框架 ( redis去重 )
1. 使用内置,并加以修改 ( 自定义 redis 存储的 keys ) settings 配置 # ############### scrapy redis连接 ################# ...
- Python分布式爬虫打造搜索引擎完整版-基于Scrapy、Redis、elasticsearch和django打造一个完整的搜索引擎网站
Python分布式爬虫打造搜索引擎 基于Scrapy.Redis.elasticsearch和django打造一个完整的搜索引擎网站 https://github.com/mtianyan/Artic ...
- scrapy简单分布式爬虫
经过一段时间的折腾,终于整明白scrapy分布式是怎么个搞法了,特记录一点心得. 虽然scrapy能做的事情很多,但是要做到大规模的分布式应用则捉襟见肘.有能人改变了scrapy的队列调度,将起始的网 ...
- 第三百六十五节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的基本查询
第三百六十五节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的基本查询 1.elasticsearch(搜索引擎)的查询 elasticsearch是功能 ...
- 四十四 Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的基本查询
1.elasticsearch(搜索引擎)的查询 elasticsearch是功能非常强大的搜索引擎,使用它的目的就是为了快速的查询到需要的数据 查询分类: 基本查询:使用elasticsearch内 ...
随机推荐
- SpringBoot 同时整合thymeleaf html、vue html和jsp
问题描述 SpringBoot如何同时访问html和jsp SpringBoot访问html页面可以,访问jsp页面报错 SpringBoot如何同时整合thymeleaf html.vue html ...
- Windows平台软件推荐:神器小工具(骨灰级)
底层工具 "If you know how to use Process Monitor competently, people of both sexes will immediately ...
- vue.js小总结
Vue.js 的核心是一个允许采用简洁的模板语法来声明式地将数据渲染进 DOM 的系统; 指令带有前缀 v-,以表示它们是 Vue 提供的特殊特性; v-for 指令可以绑定数组的数据来渲染一个项目列 ...
- 运行yum时出现/var/run/yum.pid已被锁定,PID为xxxx的另一个程序正在运行的问题解决
出现问题 [root@localhost ~]#yum update 已加载插件: fastestmirror,security /var/run/yum.pid已被锁定,PID为1610的另一个程序 ...
- 判断系统是64位还是32位的bat方法
if "%PROCESSOR_ARCHITECTURE%"=="x86" goto x86 if "%PROCESSOR_ARCHITECTURE%& ...
- bzoj 1210 [HNOI2004] 邮递员 插头dp
插头dp板子题?? 搞了我一晚上,还tm全是抄的标程.. 还有高精,哈希混入,还是我比较弱,orz各种dalao 有不明白的可以去看原论文.. #include<cstdio> #incl ...
- struts2 上传与下载
1.Struts.xml <action name="addfileAction" class="Action.addfileAction"> &l ...
- 一个优秀团队leader应该具备的几点素质
首先,技术要过硬.毕竟一个团队是在靠技术为别人创造价值的,一定程度上,团队leader的技术能力决定了整个团队的技术上限.leader对技术的坚持和追求很可能会影响团队成员对技术的坚持和追求,至少le ...
- PyQt5嵌入matplotlib动画
# -*- coding: utf-8 -*- import sys from PyQt5 import QtWidgets import numpy as np from matplotlib.ba ...
- Helm学习笔记
Helm学习笔记 Helm 是 Kubernetes 生态系统中的一个软件包管理工具.本文将介绍 Helm 中的相关概念和基本工作原理,并通过一个具体的示例学习如何使用 Helm 打包.分发.安装.升 ...