HDFS 重要机制之 checkpoint
核心概念
hdfs checkpoint 机制对于 namenode 元数据的保护至关重要, 是否正常完成检查点是评估 hdfs 集群健康度和风险的重要指标
- editslog : 对 hdfs 操作的事务记录,类似于 wal ,edit log文件以 edits_ 开头,后面跟一个txid范围段,并且多个edit log之间首尾相连,正在使用的 edit log 名字为 edits_inprogress_txid(dfs.namenode.edits.dir)
- fsimage:文件系统的元数据,snn会定时合并将内存中的元数据落盘生成新的fsimage,默认会保存两个fsimage文件,文件格式为fsimage_txid(dfs.namenode.name.dir)
- seen_txid:记录了最后一次 checkpoint 或者 edit 回滚(将 edits_inprogress_xxx 文件回滚成一个新的 Edits 文件)之后的 transaction ID。主要用来检查 NameNode 启动过程中 Edits 文件是否有丢失的情况
检查点将从旧的 fsimage 和编辑日志进行合并,创建一个新的 fsimage
checkpoint 触发由三个参数控制
dfs.namenode.checkpoint.period
dfs.namenode.checkpoint.txns
dfs.namenode.checkpoint.check.periodHA 集群的 checkpoint 过程
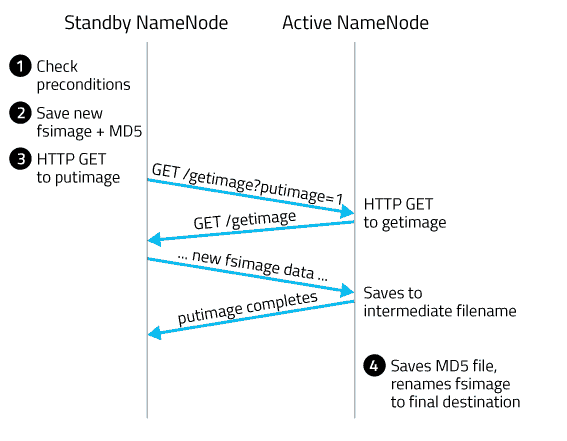
这里 standby namenode 称为 SBNN,active namenode 称为 ANN
- SBNN 查看是否满足创建检查点的条件(距离上次 checkpoint 的时间间隔大于等于 dfs.namenode.checkpoint.period
edits log 中的事务条数达到 dfs.namenode.checkpoint.txns 限制) - SBNN 将内存中当前的状态保存成一个新的文件,命名为fsimage.ckpt_txid。其中 txid 是最后一个 edit log 中的最后一条事务的 ID(transaction ID,不包括 inprogress)。然后为该 fsimage 文件创建一个MD5 文件,并将 fsimage 文件重命名为 fsimage_txid。
- SBNN 向 ANN 发送一条 HTTP GET 请求。请求中包含了 SBNN 的域名,端口以及新 fsimage 的 txid。
ANN 收到请求后,用获取到的信息反过来向 SBNN 再发送一条 HTTP GET 请求,获取新的 fsimage 文件。这个新的 fsimage 文件传输到 ANN 上后,也是先命名为 fsimage.ckpt_txid,并为它创建一个 MD5 文件。然后再改名为 fsimage_txid,checkpoint过程完成。
生产实践
对于大规模的集群,如果长期未成功完成 checkpoint ,那么会积累非常多的 editlog 文件.重启 namenode 的时候,必须要回放 editlog ,以使内存中的目录树恢复到最新状态.回放 editlog 必然是逐个文件来回放的,此时如果积累了大量的 editlog 文件,那么这个过程会长达三个小时以上.增大 namenode 的内存可以适当加快这个过程.
- edit 文件堆积处理
如果长期 edit 日志文件有堆积,可以进入安全模式后,手动运行 saveNamespace 命令来进行一次合并. 但是线上环境中,不能进入安全模式,这个时候可以通过重启 standynamenode 来触发一次 checkpoint
遇到过一次线上问题,由于 ann 锁的问题导致 sbnn 无法 put fsimage 到 ann,重启 sbnn 也无法完成最终完成 checkpoint ,这个时候可以等 sbnn namespace 正常启动后,然后进行一次主备切换,使之前锁住的 ann 变成了 sbnn,然后重启这个节点,此时就能够完成 checkpoint 了,堆积的 edit 文件也能够被清理了
- 手动 checkpoint 方法
hdfs dfsadmin -fs 10.0.0.26:4007 -safemode enter
hdfs dfsadmin -fs 10.0.0.26:4007 -saveNamespace
hdfs dfsadmin -fs 10.0.0.26:4007 -safemode leave
hdfs dfsadmin -safemode forceExit //强制退出安全模式
- 监控 checkpoint
有两个重要指标:
- TransactionsSinceLastCheckpoint 表示距离上次checkpoint的事务数,建议超过3000000 告警
- LastCheckpointTime 上次checkpoint的时间,建议距离当前时间超过12小时告警
- 谨慎重启 NameNode
hdfs 在重启流程需要加载 edit logs,如果 edit logs 遗留有没被注意到的错误, hdfs 将会无法启动完成,导致生产事故
比较常见的原因是:
误删editslog、JournalNode节点有断电、数据目录磁盘占满、网络持续异常等
常见报错如下:
java.io.IOException: Gap in transactions. Expected to be able to read up until at least txid 813248390 but unable to find any edit logs containing txid 363417469可以动态开启DEBUG 日志级别定位报错位置
解决办法:
- 查看其它的JournalNode的数据目录或NameNode数据目录中,有没有连续的该序号相关的连续的edits文件。如果可以找到,复制一个连续的片段到该JournalNode
- 使用namenode recovery 模式 跳过 edits 错误
- 使用 edits viewer 修复错误 edit 文件
- 从 active nn 恢复 standy nn
- 以上如不能解决,只能从fsimage恢复namenode 来上线 namenode
HDFS 重要机制之 checkpoint的更多相关文章
- 60、Spark Streaming:缓存与持久化机制、Checkpoint机制
一.缓存与持久化机制 与RDD类似,Spark Streaming也可以让开发人员手动控制,将数据流中的数据持久化到内存中.对DStream调用persist()方法,就可以让Spark Stream ...
- Hadoop(七)HDFS容错机制详解
前言 HDFS(Hadoop Distributed File System)是一个分布式文件系统.它具有高容错性并提供了高吞吐量的数据访问,非常适合大规模数据集上的应用,它提供了一个高度容错性和高吞 ...
- Elasticsearch和HDFS 容错机制 备忘
1.Elasticsearch 横向扩容以及容错机制http://www.bubuko.com/infodetail-2499254.html 2.HDFS容错机制详解https://www.cnbl ...
- HDFS写机制
HDFS写机制: 1.client客户端调用分布式文件系统对象DistributedFileSystem对象的create方法,创建一个文件输出流FSDataOutputStream对象. 2.Dis ...
- 深刻理解HDFS工作机制
深入理解一个技术的工作机制是灵活运用和快速解决问题的根本方法,也是唯一途径.对于HDFS来说除了要明白它的应用场景和用法以及通用分布式架构之外更重要的是理解关键步骤的原理和实现细节.在看这篇博文之前需 ...
- HDFS副本机制&负载均衡&机架感知&访问方式&健壮性&删除恢复机制&HDFS缺点
副本机制 1.副本摆放策略 第一副本:放置在上传文件的DataNode上:如果是集群外提交,则随机挑选一台磁盘不太慢.CPU不太忙的节点上:第二副本:放置在于第一个副本不同的机架的节点上:第三副本:与 ...
- HDFS深度历险 之 从客户端逻辑看HDFS写入机制
说明 除了标注之外,本文纯属原创,转载请注明出处:https://www.jianshu.com/p/ea6ef5f5b868, https://www.cnblogs.com/monkeyteng/ ...
- hdfs运行机制
hdfs:分布式文件系统 hdfs有着文件系统共同的特征: 1.有目录结构,顶层目录是: / 2.系统中存放的就是文件 3.系统可以提供对文件的:创建.删除.修改.查看.移动等功能 hdfs跟普通的 ...
- Hadoop框架:HDFS读写机制与API详解
本文源码:GitHub·点这里 || GitEE·点这里 一.读写机制 1.数据写入 客户端访问NameNode请求上传文件: NameNode检查目标文件和目录是否已经存在: NameNode响应客 ...
- HDFS 02 - HDFS 的机制:副本机制、机架感知机制、负载均衡机制
目录 1 - HDFS 的副本机制 2 - HDFS 的机架感知机制 3 - HDFS 的负载均衡机制 参考资料 版权声明 1 - HDFS 的副本机制 HDFS 中的文件,在物理上都是以分块(blo ...
随机推荐
- ChatGPT的训练费用以及成功原因
参考: https://baijiahao.baidu.com/s?id=1772914234034992726&wfr=spider&for=pc ================= ...
- Tensorflow1.14中placeholder.shape和tf.shape(placeholder)的区别
最近在看TensorFlow的代码,还是1.14版本的TensorFlow的,代码难度确实比pytorch的难上不是多少倍,pytorch的代码看一遍基本能看懂个差不多,TensorFlow的代码看一 ...
- 再探 游戏 《 2048 》 —— AI方法—— 缘起、缘灭(7) —— Python版本实现的《2048》游戏的TDL算法
<2048>游戏在线试玩地址: https://play2048.co/ 如何解决<2048>游戏源于外网的一个讨论帖子,而这个帖子则是讨论如何解决该游戏的最早开始,可谓是&q ...
- java多线程之ReentrantLock详解
1.背景 2.基本语法 public class Test01 { // 定义锁 static ReentrantLock reentrantLock = new ReentrantLock(); p ...
- java:找不到符号(使用lombok)
1.背景 启动报错: Error:(76, 34) java: 找不到符号 符号: 方法 getOrderNo() 位置: 类型为XXXXX.request.coupon.SubmitOrderObj ...
- 洛谷P1226 【模板】快速幂
1.快速幂模板 前置知识 一个数字n,它的二进制位数一定是log2n向下取整+1: 快速幂模板代码 这段代码实现了快速幂算法(Exponentiation by squaring),用来计算 ( an ...
- DolphinScheduler 3.3.0版本更新一览
Apache DolphinScheduler即将迎来3.3.0版本的发布,届时将有一系列重要的更新和改进.在近期的社区5月份用户线上分享会上,项目PMC 阮文俊为大家介绍了3.3.0版本将带来的主要 ...
- [学习笔记] 单调队列优化DP - DP
单调队列优化DP 简单好想的DP优化 真正的教育是把学过的知识忘掉后剩下的东西 -- *** 对于一个转移方程类似于 \(dp[i]=max(min)\{dp[j]+b[j]+a[i]\}\ \ x_ ...
- MFC对话框程序:实现程序启动画面
MFC对话框程序:实现程序启动画面 对于比较大的程序,在启动的时候都会显示一个画面,以告诉用户程序正在加载,或者显示一些关于软件的信息,如Visual C++,Word, PhotoShop等.那么对 ...
- StarNet:关于 Element-wise Multiplication 的高性能解释研究 | CVPR 2024
论文揭示了star operation(元素乘法)在无需加宽网络下,将输入映射到高维非线性特征空间的能力.基于此提出了StarNet,在紧凑的网络结构和较低的能耗下展示了令人印象深刻的性能和低延迟 来 ...