AI应用实战课学习总结(12)Transformer
大家好,我是Edison。
最近入坑黄佳老师的《AI应用实战课》,记录下我的学习之旅,也算是总结回顾。
今天是我们的第12站也是最后一站,一起了解下在DNN/CNN/RNN之后横空出世的Transformer,作为大语言模型的基础架构,它到底有什么样的优势?
从CNN到Transformer
在之前的两篇内容中,我们了解了深度学习和基于CNN发展出来的神经网络模型如RNN等,经过了多年的发展,现在已经发展到了Transformer,突破了自然语言处理的瓶颈,从而真正开始能够理解语言然后开始和人类聊天对话。
Transformer也是一种深度学习模型,具有Encoder(编码器)和 Decoder(解码器)的架构,有的模型只用了Encoder(如BERT),有的模型只用了Decoder(如GPT),还有的模型Encoder和Decoder都有使用到(如T5)。
它最初是为了解决从序列到序列(Seq2Seq)的任务,比如说机器翻译,它先给语言做一个编码,然后再解码,就能够实现完成这个机器的翻译。

Transformer架构中最核心的内容就是引入了自注意力机制,通过自注意力和多头自注意力机制实现了并行处理,通过多层具有自注意机制的网络层叠加来实现模式的学习,进而大幅提高了处理效率。
从Transformer演化出了GPT,或者说GPT是基于Transformer的一个自回归的模型,它只用到了Transformer的Decoder(解码器)。所谓自回归任务,就是专注于预测序列中的下一个字(严谨点说是Token),如下图所示:
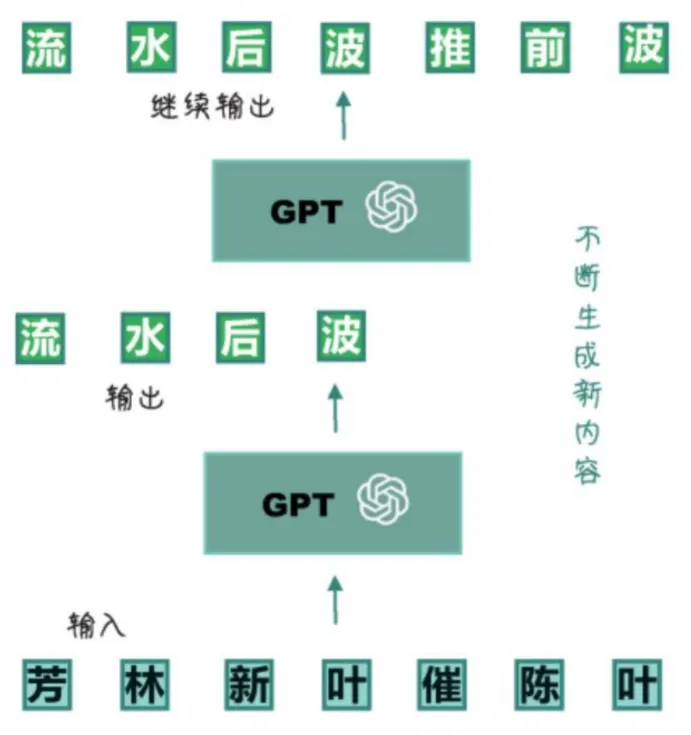
GPT通过自回归模型进行预训练,在进行预训练的时候,模型会被输入大量的文本数据,然后开始预测每一个词的下一个词,如此往复,直到整个句子说的差不多了,不断生成新内容。通过这种方式,GPT学习到了语言规律、语法、词法、词汇搭配等等,然后生成的都是自然流畅的文本。


Transformer为何有效?
还记得上一篇RNN中举得例子吗?老师给学生传纸条,一个学生看一个字,再通过Hidden节点将前面的字记下来,这是一种非常低效的记忆方式。

在Transformer中,则是通过自注意力机制并行计算互相注意的方式实现高效便捷的处理,进而将编码器和解码器串联起来。
因此,Transformer相较于RNN更加有效的原因在于:
(1)自注意力机制
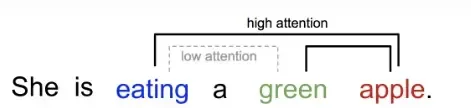
Transformer会将整个序列一次性导入,并将整个序列中的元素分配不同的注意力权重。换句话说,在考虑上下文时为每一个单词(严格来说是Token)都分配一个适当的重要性,这就可以让模型可以在一个序列中捕捉长距离的依赖关系。而这个依赖关系,其实就可以帮助模型理解句子中的各种语法和语义的模式。
如下图所示,当聚焦到前面一列头部的某个 Token 时,它会在后面一列(也是同一个句子中的 Token 序列)找到与该 Token 更相关的其它 Token,或者可以说句子中的每个 Token 都与前面当前所聚焦 Token 有一个相关数值,值越大表示越相关,对应的注意力权重也越大。当然,同一个 Token 与它自己最相关,通常相关值最大。

(2)多头注意力
所谓多头注意力就是指它不仅仅一组一组地寻找注意力,而是融合多个注意力,进而学到更多的行为。人类的语言非常微妙,一个句子可能有多种含义,因此只找一组是不够的。
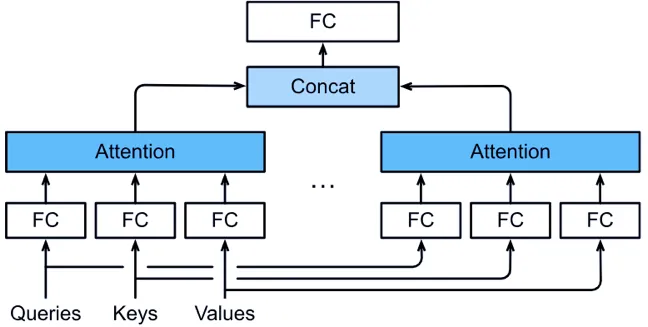
比如,在机器翻译任务中,使用多头注意力能够学习并捕捉到输入序列中的不同类型信息:一个注意力头可能学习句子的语法结构,而另一个注意力头可能学习句子中的于语义信息,这样更有利于模型生成准确、自然的翻译结果,从而提高了模型的性能。
(3)并行性和可扩展性
因为Transformer是并行处理本身具有并行性,因此可以通过简单地增加它的层数,隐藏单元数或者注意力的头数,实现可扩展性,获得更好的处理效率。
大语言模型的训练方式
不同的大语言模型使用了不同的预训练方式,这里以BERT和GPT为例说明:
BERT采取的是 抠字完形填空 的方式:

如果模型猜对了,损失函数就低,相反损失函数就高。因此,通过这种猜词的方式调整参数,慢慢让其形成猜词能力。猜词这种方式是双向关注,而下面GPT是单项关注。
GPT采取的是 猜测下一句 的方式:

如上图,如果生成的准确,损失函数就低,相反损失函数就大,慢慢调参形成下个句子的预测能力。
大语言模型的使用方式
目前主流的大语言模型的使用方式为:预训练 + 微调。
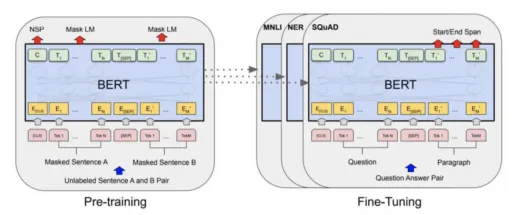
预训练 (Pre-Training) 相当于盖一座房子的地基和框架,经过预训练之后的大语言模型通常称为基线模型(Base Model)。
微调(Fine-Tuning)则相当于根据业务需求做精装修,借助基线模型我们不用每次都从做起,只需要用少量的特定业务场景的领域数据进行二次训练或迁移训练,使其适应具体业务任务即可。
通过结合预训练和微调,既节省训练资源又能专业化应用。
小结
本文介绍了Transformer的基本概念和架构,它相对于RNN的优势主要就在于自注意力机制,实现了并行性和可扩展性,进而催生了GPT等大语言模型的诞生。
目前我们可以通过对预训练好的大语言模型进行微调,进而让其适应我们的业务任务,节省资源又能保证质量。
参考文章
简单之美,《理解注意力机制》
CoCoML,《详解深度学习中的“注意力机制”》
推荐学习
黄佳,《AI应用实战课》(课程)

黄佳,《图解GPT:大模型是如何构建的》(图书)
黄佳,《动手做AI Agent》(图书)

AI应用实战课学习总结(12)Transformer的更多相关文章
- DDD实战课--学习笔记
目录 学好了DDD,你能做什么? 领域驱动设计:微服务设计为什么要选择DDD? 领域.子域.核心域.通用域和支撑域:傻傻分不清? 限界上下文:定义领域边界的利器 实体和值对象:从领域模型的基础单元看系 ...
- 《即时消息技术剖析与实战》学习笔记12——IM系统如何提升图片、音视频消息发送、浏览的体验
IM系统如何提升用户发送.浏览图片和音视频消息的体验呢?一是保证图片.音视频消息发送得又快又稳,二是保证用户浏览播放图片.音视频消息时流畅不卡顿. 一.提升用户发送图片.音视频的体验 1. 多上传接入 ...
- 量子化学Gaussian技术实战课 2021年4月9号--12号 远程在线教学
材料模拟分子动力学课程 3月19号--22号 远程在线课 lammps分子动力学课程 3月12号--15号 远程在线课 第一性原理VASP实战课 3月25号-28号 远程在线课 量子化学Gaussia ...
- 《Angular4从入门到实战》学习笔记
<Angular4从入门到实战>学习笔记 腾讯课堂:米斯特吴 视频讲座 二〇一九年二月十三日星期三14时14分 What Is Angular?(简介) 前端最流行的主流JavaScrip ...
- AI面试必备/深度学习100问1-50题答案解析
AI面试必备/深度学习100问1-50题答案解析 2018年09月04日 15:42:07 刀客123 阅读数 2020更多 分类专栏: 机器学习 转载:https://blog.csdn.net ...
- 实战 迁移学习 VGG19、ResNet50、InceptionV3 实践 猫狗大战 问题
实战 迁移学习 VGG19.ResNet50.InceptionV3 实践 猫狗大战 问题 参考博客:::https://blog.csdn.net/pengdali/article/detail ...
- 第1课 - 学习 Lua 的意义
第1课 - 学习 Lua 的意义 1.Lua 简介 (1) 1993年.巴西 (2) 小巧精致的脚本语言,大小只有 200K (3) 用标准C语言写成,能够在所有的平台上编译运行 (4) 发明的目标是 ...
- JavaEE精英进阶课学习笔记《博学谷》
JavaEE精英进阶课学习笔记<博学谷> 第1章 亿可控系统分析与设计 学习目标 了解物联网应用领域及发展现状 能够说出亿可控的核心功能 能够画出亿可控的系统架构图 能够完成亿可控环境的准 ...
- Ext.Net学习笔记12:Ext.Net GridPanel Filter用法
Ext.Net学习笔记12:Ext.Net GridPanel Filter用法 Ext.Net GridPanel的用法在上一篇中已经介绍过,这篇笔记讲介绍Filter的用法. Filter是用来过 ...
- [AI开发]将深度学习技术应用到实际项目
本文介绍如何将基于深度学习的目标检测算法应用到具体的项目开发中,体现深度学习技术在实际生产中的价值,算是AI算法的一个落地实现.本文算法部分可以参见前面几篇博客: [AI开发]Python+Tenso ...
随机推荐
- Effective Java理解笔记系列-第1条-何时考虑用静态工厂方法替代构造器?
为什么写这系列博客? 在阅读<Effective Java>这本书时,我发现有许多地方需要仔细认真地慢慢阅读并且在必要时查阅相关资料才能彻底搞懂,相信有些读者在阅读此书时也有类似感受:同时 ...
- Asp.net mvc基础(六)TempData
在客户端重定向或验证码等情况下,由于要跨请求的存取数据,是不能放到ViewBag.Model中,需要"暂时存到Session中,用完了删除"的需求:使用TempData可以做到. ...
- 在win nginx下配置symfony3.4,并隐藏项目名称 .php入口
在win nginx下配置symfony3.4,并隐藏项目名称 .php入口 记录下 # power by www.php.cn #user nobody; worker_processes 1; ...
- windows快速开启【程序和功能】
程序和功能一般常用的操作是对软件进行卸载. 方式一: 1. Win+R打开运行 2. 输入appwiz.cpl命令 方式二: 1.Win+X打开快捷开关 2. F进去应用和功能 3.点击右侧程序和功能 ...
- OSCP靶场练习从零到一之TR0LL: 1
本系列为 OSCP 证书学习训练靶场的记录,主要涉及到 vulnhub.HTB 上面的 OSCP 靶场,后续慢慢更新 1.靶场介绍 名称: TR0LL: 1 下载地址: https://www.vul ...
- 【HUST】网络攻防实践|6_物联网设备固件安全实验|实验三 FreeRTOS-MPU 保护绕过
文章目录 实验三 FreeRTOS-MPU 保护绕过 实验要求 子任务1 逆向分析StartFreeRTOS 打印 Flag 函数名称和地址 用于提权的函数名称和地址 填写的代码 模拟运行截图 **附 ...
- 【HUST】网安|操作系统实验|实验四 设备管理、文件管理
文章目录 任务 任务1 编写一个Linux内核模块,并完成安装/卸载等操作. 1. 提示 2. 任务代码 3. 结果及说明 任务2 编写Linux驱动程序并编程应用程序测试. 1. 提示 2. 任务代 ...
- Excel 拼接为 SQL 并打包 exe
关于 Excel 拼接 sql 这个操作, 我已经整过好几篇了, 当然在工作中也是蛮常用的, 今天主要是来写个终篇, 彻底结束它, 然后将代码进行打包为 exe 这样的桌面小软件, 除了自己用, 也可 ...
- Ubuntu安装部署Zabbix网络监控平台和设备配置添加
概述 Zabbix 由 Alexei Vladishev 创建,目前由 Zabbix SIA 主导开发和支持. Zabbix 是一个企业级的开源分布式监控解决方案. Zabbix 是一款监控众多参数的 ...
- Python中的模块包
dir0/dir1/dir2/mod.py,dir0必须在环境变量中,可以import dir1,import dir1.dir2.mod.但在python3.3之前,dir1和dir2下必须存放一个 ...