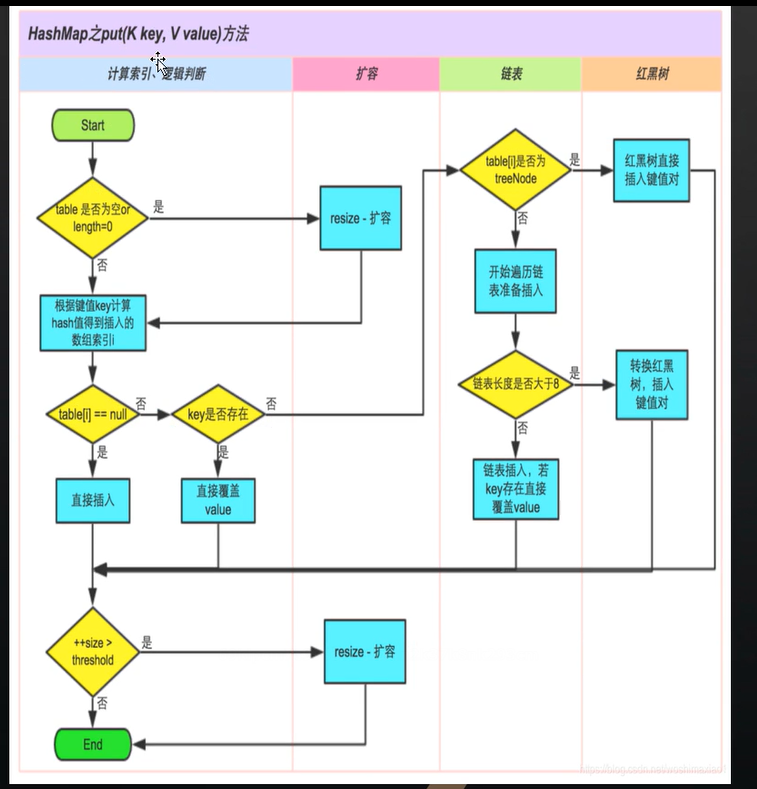
HashMap的put方法的扩容流程
final Node<K,V>[] resize() {
// [1,2,3,4,5,6,7,8,9,10,11,,,,]
Node<K,V>[] oldTab = table;
// 16
int oldCap = (oldTab == null) ? 0 : oldTab.length;
// 12
int oldThr = threshold;
int newCap, newThr = 0;
if (oldCap > 0) {
if (oldCap >= MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return oldTab;
}
// 新的容量是 原来容量的两倍
else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&
oldCap >= DEFAULT_INITIAL_CAPACITY)
// 扩容的临界值 原来的两倍 24
newThr = oldThr << 1; // double threshold
}
else if (oldThr > 0) // initial capacity was placed in threshold
newCap = oldThr;
else { // zero initial threshold signifies using defaults
newCap = DEFAULT_INITIAL_CAPACITY;
newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);
}
if (newThr == 0) {
float ft = (float)newCap * loadFactor;
newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ?
(int)ft : Integer.MAX_VALUE);
}
threshold = newThr;
@SuppressWarnings({"rawtypes","unchecked"})
// 创建的数组的长度是32
Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap];
table = newTab;
if (oldTab != null) { // 初始的时候是不需要复制的
for (int j = 0; j < oldCap; ++j) {
Node<K,V> e;
if ((e = oldTab[j]) != null) {
oldTab[j] = null;
if (e.next == null)
// 数组中的元素就一个 找到元素在新的数组中的位置 赋值
newTab[e.hash & (newCap - 1)] = e;
else if (e instanceof TreeNode)
// 移动红黑树节点
((TreeNode<K,V>)e).split(this, newTab, j, oldCap);
else { // preserve order
// 普通的链表的移动
Node<K,V> loHead = null, loTail = null;
Node<K,V> hiHead = null, hiTail = null;
Node<K,V> next;
do {
next = e.next;
if ((e.hash & oldCap) == 0) {
if (loTail == null)
loHead = e;
else
loTail.next = e;
loTail = e;
}
else {
if (hiTail == null)
hiHead = e;
else
hiTail.next = e;
hiTail = e;
}
} while ((e = next) != null);
if (loTail != null) {
loTail.next = null;
newTab[j] = loHead;
}
if (hiTail != null) {
hiTail.next = null;
newTab[j + oldCap] = hiHead;
}
}
}
}
}
return newTab;
}
final Node<K,V>[] resize() {
// [1,2,3,4,5,6,7,8,9,10,11,,,,]
Node<K,V>[] oldTab = table;
// 16
int oldCap = (oldTab == null) ? 0 : oldTab.length;
// 12
int oldThr = threshold;
int newCap, newThr = 0;
if (oldCap > 0) {
if (oldCap >= MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return oldTab;
}
// 新的容量是 原来容量的两倍
else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&
oldCap >= DEFAULT_INITIAL_CAPACITY)
// 扩容的临界值 原来的两倍 24
newThr = oldThr << 1; // double threshold
}
else if (oldThr > 0) // initial capacity was placed in threshold
newCap = oldThr;
else { // zero initial threshold signifies using defaults
newCap = DEFAULT_INITIAL_CAPACITY;
newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);
}
if (newThr == 0) {
float ft = (float)newCap * loadFactor;
newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ?
(int)ft : Integer.MAX_VALUE);
}
threshold = newThr;
@SuppressWarnings({"rawtypes","unchecked"})
// 创建的数组的长度是32
Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap];
table = newTab;
if (oldTab != null) { // 初始的时候是不需要复制的
for (int j = 0; j < oldCap; ++j) {
Node<K,V> e;
if ((e = oldTab[j]) != null) {
oldTab[j] = null;
if (e.next == null)
// 数组中的元素就一个 找到元素在新的数组中的位置 赋值
newTab[e.hash & (newCap - 1)] = e;
else if (e instanceof TreeNode)
// 移动红黑树节点
((TreeNode<K,V>)e).split(this, newTab, j, oldCap);
else { // preserve order
// 普通的链表的移动
Node<K,V> loHead = null, loTail = null;
Node<K,V> hiHead = null, hiTail = null;
Node<K,V> next;
do {
next = e.next;
if ((e.hash & oldCap) == 0) {
if (loTail == null)
loHead = e;
else
loTail.next = e;
loTail = e;
}
else {
if (hiTail == null)
hiHead = e;
else
hiTail.next = e;
hiTail = e;
}
} while ((e = next) != null);
if (loTail != null) {
loTail.next = null;
newTab[j] = loHead;
}
if (hiTail != null) {
hiTail.next = null;
newTab[j + oldCap] = hiHead;
}
}
}
}
}
return newTab;
}
HashMap的put方法的扩容流程的更多相关文章
- HashMap之put方法流程解读
说明:本文中所谈论的HashMap基于JDK 1.8版本源码进行分析和说明. HashMap的put方法算是HashMap中比较核心的功能了,复杂程度高但是算法巧妙,同时在上一版本的基础之上优化了存储 ...
- ArrayList的add(E e)方法与扩容
ArrayList是Java开发中经常用到的集合类,它是List接口的实现类,具有很高的查询性能,但不是线程安全的.本文主要讲述了ArrayList的add(E e)方法及该方法中涉及到的容量扩容技术 ...
- Java基础:HashMap中putAll方法的疑惑
最近回顾了下HashMap的源码(JDK1.7),当读到putAll方法时,发现了之前写的TODO标记,当时由于时间匆忙没来得及深究,现在回顾到了就再仔细思考了下 @Override public v ...
- HashMap底层实现原理及扩容机制
HashMap的数据结构:数组+链表+红黑树:Java7中的HashMap只由数组+链表构成:Java8引入了红黑树,提高了HashMap的性能:借鉴一张图来说明,原文:https://www.jia ...
- hashMap的get()方法,错用并发造成cpu和负载高
一次线上问题的解决 线上发现服务cpu使用达到98%,负载高达200多,64核心cpu,下面介绍解决过程: 1.top命令查出占用cpu高的进程pid 2.使用jstack -l pid >du ...
- 从源码角度看finish()方法的执行流程
1. finish()方法概览 首先我们来看一下finish方法的无参版本的定义: /** * Call this when your activity is done and should be c ...
- jdk1.8 HashMap的keySet方法详解
我在看HashMap源码的时候有一个问题让我产生了兴趣,那就是HashMap的keySet方法,没有调用HashMap的有关数据的任何方法就能获取到map的所有的键,他是怎么做到的,然后我就通过模拟k ...
- HashMap的put方法返回值问题
API文档中的描述: 先看一个例子 Map<Character, Integer> map = new HashMap<Character, Integer>(); Syste ...
- HashMap的clear方法
我们都知道HashMap的clear()方法会清楚map的映射关系,至于怎么实现的呢? 下面先看一下clear()方法的源码 public void clear() { Node<K,V> ...
- HashMap集合-遍历方法
# HashMap集合-遍历方法 先定义好集合: public static void main(String[] args) { Map<String,String> onemap=ne ...
随机推荐
- Groovy基础语法!
Groovy是什么语言? Groovy是一种基于JVM(Java虚拟机)的敏捷开发语言,它结合了Python.Ruby和Smalltalk的许多强大的特性,Groovy 代码能够与 Java 代码很好 ...
- GIt分布式管理工具
Git(分布式版本控制工具) Git的学习是不依赖我们前面学习的知识,就算没有学习java也可以学习 Git就是一个类似于百度云盘的仓库 重点是要掌握使用idea操作Git,企业用的最多,一般不会去使 ...
- vite3+vue3 实现前端部署加密混淆 javascript-obfuscator
安装 pnpm install javascript-obfuscator 安装之后 在项目根目录新建一个 obfuscator.js 在 obfuscator.js 写入以下代码 直接复制粘贴 ` ...
- Manjaro/Arch用怎么安装天翼云电脑(Ctyun-cloud-desk)?感谢信创,感谢国家
最近微信出了linux版,用vmware装linux不过瘾,把一台闲置的笔记本装上了Manjaro KDE Plasma,经过一段时间的发展,Linux桌面可用性大大提高. Kindle->Ki ...
- Nuxt.js 应用中的 vite:serverCreated 事件钩子
title: Nuxt.js 应用中的 vite:serverCreated 事件钩子 date: 2024/11/18 updated: 2024/11/18 author: cmdragon ex ...
- ubuntu安装使用mydumper
apt搜索一下 $ sudo apt search mydumper [sudo] password for zhaoyao: Sorting... Done Full Text Search... ...
- 符合ASTM标准的雨流计数法及其不同的改进方法
随着研究的深入,人们发现采用时间序列计算载荷谱太麻烦了,处理的工作量太大,我们不需要将每个时刻点的载荷都做运算,疲劳计算只需要提供幅值.均值和循环次数,鉴于此发展出了很多不同的计数方法,雨流法是最常见 ...
- 使用 Antlr 处理文本
高 尚 (gaoshang1999@163.com), 软件工程师, 中国农业银行软件开发中心 简介: Antlr 是一个基于 Java 开发的功能强大的语言识别工具,其主要功能原本是用于识别编程语言 ...
- 在vue中使用XLSX导出表格
安装依赖 npm install file-saver xlsx -S 然后在需要的页面中引入依赖包 import FileSaver from 'file-saver'; import XLSX f ...
- redis教程(Mac)
1.首先,检查是否已经安装Homebrew,如果没有安装Homebrew,请先安装 2.使用Homebrew安装命令,在终端输入以下命令 brew install redis 当前默认安装5.0.8版 ...