LangChain框架入门08:全方位解析记忆组件
在前面的章节中,我们学习了如何使用LangChain构建基本的对话应用,不过在和大语言模型对话时,你可能会注意到大语言模型很快就会失忆,后面聊天提问前面聊过的内容,大语言模型仿佛完全“忘记”了。
为了解决这个问题,LangChain提供了强大的记忆组件(Memory),能够让AI“记住”上下文对话信息。
一、为什么需要记忆组件
大语言模型本质上是经过大量数据训练出来的自然语言模型,用户给出输入信息,大语言模型会根据训练的数据进行预测给出指定的结果,大语言模型本身是“无状态的”,因此大语言模型是没有记忆能力的。
当我们和大语言模型聊天时,会出现如下的情况:
Human:我叫大志,请问你是?
AI:你好,大志,我是OpenAI开发的聊天机器人。
Human:你知道我是谁吗?
AI:我不知道,请你告诉我的名字。
我们刚刚在前一轮对话告诉大语言模型的信息,下一轮就被“遗忘了”。当我在ChatGPT官网和ChatGPT聊天时,它能记住多轮对话中的内容,这ChatGPT网页版实现了历史记忆功能。

二、记忆组件实现原理
一个记忆组件要实现的三个最基本功能:
- 读取记忆组件保存的历史对话信息
- 写入历史对话信息到记忆组件
- 存储历史对话消息
在LangChain中,给大语言模型添加记忆功能的方法:
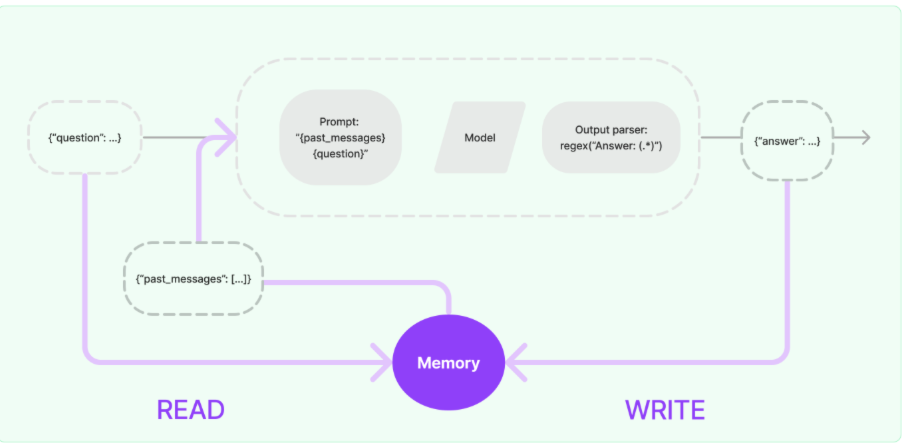
- 在链执行前,将历史消息从记忆组件读取出来,和用户输入一起添加到提示词中,传递给大语言模型。
- 在链执行完毕后,将用户的输入和大语言模型输出,一起写入到记忆组件中
- 下一次调用大语言模型时,重复这个过程
这样大语言模型就拥有了“记忆”功能,上述实现记忆功能的流程图如下:
三、记忆组件介绍
3.1 常见记忆组件
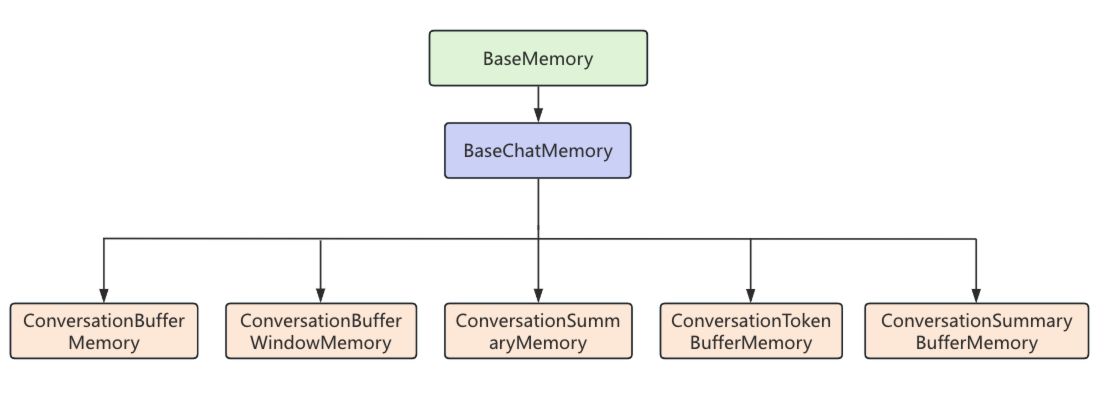
LangChain中的记忆组件继承关系图如下,所有常用的记忆组件都继承自BaseChatMemory类,如果我们自己想实现一个自定义的记忆组件也可以继承BaseChatMemory。
下面是LangChain中常用记忆组件以及它们的特性。
| 组件名称 | 特性 |
|---|---|
| ConversationBufferMemory | 保存所有的历史对话信息 |
| ConversationBufferWindowMemory | 保存最近N轮对话内容 |
| ConversationSummaryMemory | 压缩历史对话为摘要信息 |
| ConversationSummaryBufferMemory | 结合缓存和摘要信息 |
| ConversationTokenBufferMemory | 基于token限制的历史对话信息 |
3.2 BaseChatMemory简介
下面对BaseChatMemory的核心属性与方法进行分析:
1、属性:
chat_memory: BaseChatMessageHistory类的的对象,BaseChatMessageHistory是真正实现保存历史对话信息功能的类,这里BaseChatMemory并没有在自身去实现聊天消息的保存,而是抽象出BaseChatMessageHistory类,保持各个类遵循单一职责原则,这样做更利于项目的扩展和解耦。
chat_memory: BaseChatMessageHistory = Field(
default_factory=InMemoryChatMessageHistory
)
2、方法
save_context():同步保存历史消息
load_memory_variables():加载历史记忆信息
clear():同步清空历史记忆信息
3.3 BaseChatMessageHistory简介
BaseChatMessageHistory是用来保存聊天消息历史的抽象基类,下面对BaseChatMessageHistory的核心属性与方法进行分析:
1.属性:
messages: List[BaseMessage]:用来接收和读取历史消息的只读属性
2.方法:
add_messages:批量添加消息,默认实现是每个消息都去调用一次add_message
add_message:单独添加消息,实现类必须重写这个方法,否则会抛出异常
clear():清空所有消息,实现类必须重写这个方法
BaseChatMessageHistory常见实现类如下:

下面是LangChain中常用的消息历史组件以及它们的特性,其中InMemoryChatMessageHistory是BaseChatMemory默认使用的聊天消息历史组件。
| 组件名称 | 特性 |
|---|---|
| InMemoryChatMessageHistory | 基于内存存储的聊天消息历史组件 |
| FileChatMessageHistory | 基于文件存储的聊天消息历史组件 |
| RedisChatMessageHistory | 基于Redis存储的聊天消息历史组件 |
| ElasticsearchChatMessageHistory | 基于ES存储的聊天消息历史组件 |
四、记忆组件使用方法
下面以最典型的ConversationBufferWindowMemory类和ConversationSummaryBufferMemory类作为示例,来演示记忆组件的使用方法。
4.1 ConversationBufferWindowMemory用法
ConversationBufferMemory是LangChain中最简单的记忆组件,它只是简单将所有的历史对话信息进行缓存,而ConversationBufferWindowMemory与ConversationBufferMemory的主要区别在于:ConversationBufferWindowMemory增加了一个限制,ConversationBufferWindowMemory只返回最近K轮对话的历史记忆,这样做的目的是为了在实现历史记忆和大语言模型token消耗之间寻找一个平衡,如果每次携带的历史消息太长,那么每次消耗的token数量都会非常多。
ConversationBufferWindowMemory使用示例如下,创建ConversationBufferWindowMemory指定return_messages为True,表示加载历史消息时返回消息列表而非字符串,指定k为2,表示最多返回两轮对话的历史记忆。
在链的第一个可运行组件位置,调用了memory组件,并读取了历史记忆,向输入参数列表中添加了一个history参数,它的值就是历史记忆信息,继续传递到下一个可运行组件,在渲染提示词模板时即可使用历史记忆信息,历史记忆信息就和用户提问一起传递给了大语言模型,大语言模型就拥有了历史记忆。
from operator import itemgetter
import dotenv
from langchain.memory import ConversationBufferWindowMemory
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
from langchain_core.runnables import RunnablePassthrough, RunnableLambda
from langchain_openai import ChatOpenAI
# 读取env配置
dotenv.load_dotenv()
# 1.创建提示词模板
prompt = ChatPromptTemplate.from_messages([
MessagesPlaceholder("chat_history"),
("human", "{question}"),
])
# 2.构建GPT-3.5模型
llm = ChatOpenAI(model="gpt-3.5-turbo")
# 3.创建输出解析器
parser = StrOutputParser()
memory = ConversationBufferWindowMemory(return_messages=True, k=2)
# 4.执行链
chain = RunnablePassthrough.assign(
chat_history=(RunnableLambda(memory.load_memory_variables) | itemgetter("history"))
) | prompt | llm | parser
while True:
question = input("Human:")
response = chain.invoke({"question": question})
print(f"AI:{response}")
memory.save_context({"human": question}, {"ai": response})
执行结果如下,第一轮对话中,Human告诉AI,他叫大志,随后的一轮对话,显然AI已经记住了Human的名字,但是由于我们设置的k值是2,在超过两轮对话之后大语言模型就又进入失忆状态了。
Human:我是大志,你是
AI:你好,大志!我是ChatGPT,很高兴认识你。你今天怎么样?
Human:我是谁
AI:你是大志呀!不过如果你是想探索一下“我是谁”这个哲学问题,那就挺有意思的。你觉得自己是谁?
Human:冰泉冷涩弦凝绝
AI:哦,这句出自唐代词人李清照的《如梦令》。整句是:
**冰泉冷涩弦凝绝,凝绝不通声暂歇。**
Human:别有忧愁暗恨生
AI:这句出自李清照的《如梦令·常记溪亭日暮》:
**“别有忧愁暗恨生。”**
她在这句词中表达的是深深的内心愁绪和无法言说的遗憾。(省略。。。)
Human:我是谁
AI:这个问题有点哲学意味了!你是在问自我认知吗?还是在想“我是谁”这个更深层次的存在意义?每个人对“我是谁”的答案都不一样,这也许是一个可以不断探索、变化的过程。你是想聊聊这个话题吗?
Human:我的名字是什么
AI:嗯,我并不知道你的名字哦!但如果你愿意告诉我,我会很高兴记住的。你喜欢什么名字呢?或者,你对名字有什么特别的想法吗?
Human:
4.2 ConversationSummaryBufferMemory用法
ConversationSummaryBufferMemory的用法和上面的ConversationBufferWindowMemory基本一致,区别是ConversationSummaryBufferMemory是一个缓冲摘要混合记忆组件,ConversationSummaryBufferMemory支持当历史记忆超过指定的token数量就会使用指定的llm进行摘要的提取,也就是对原本的对话内容进行概括,再存储到记忆组件,这样就起到了节省token的作用。
代码示例如下,为了演示ConversationSummaryBufferMemory的实际效果,max_token_limit指定为200,并且为llm参数传入一个基于gpt-3.5-turbo大语言模型对象。
from operator import itemgetter
import dotenv
from langchain.memory import ConversationSummaryBufferMemory
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
from langchain_core.runnables import RunnablePassthrough, RunnableLambda
from langchain_openai import ChatOpenAI
# 读取env配置
dotenv.load_dotenv()
# 1.创建提示词模板
prompt = ChatPromptTemplate.from_messages([
MessagesPlaceholder("chat_history"),
("human", "{question}"),
])
# 2.构建GPT-3.5模型
llm = ChatOpenAI(model="gpt-3.5-turbo")
# 3.创建输出解析器
parser = StrOutputParser()
memory = ConversationSummaryBufferMemory(return_messages=True,
max_token_limit=200,
llm=ChatOpenAI(model="gpt-3.5-turbo")
)
# 4.执行链
chain = RunnablePassthrough.assign(
chat_history=(RunnableLambda(memory.load_memory_variables) | itemgetter("history"))
) | prompt | llm | parser
while True:
print("========================")
question = input("Human:")
response = chain.invoke({"question": question})
print(f"AI:{response}")
memory.save_context({"human": question}, {"ai": response})
print("========================")
print(f"对话历史信息:{memory.load_memory_variables({})}")
执行结果,首先Human提问详细介绍LangChain框架用法,AI回复的内容非常多,肯定超过了200个token,再次读取聊天历史消息,可以看到,多了一条系统消息,并且是用英文描述的。
这段英文描述就是对之前对话内容的摘要,之所以内容是英文的,因为生成摘要的提示词是LangChian内置的,本身就是英文的,在中文场景下使用需要对提示词进行汉化,可以指定prompt属性为自定义的提示词。
========================
Human:详细的介绍一下LangChain框架的用法
AI:**LangChain** 是一个用于构建基于大语言模型(LLM)的应用程序的框架。它提供了强大的功能来处理语言模型与外部数据的交互、自动化任务和多种数据源的处理,帮助开发者更高效地构建应用。
(中间内容省略)
如果你想开始使用 LangChain,可以从基本的 LLM 调用和简单的链式操作入手,逐渐扩展到更复杂的应用场景。
========================
对话历史信息:{'history': [SystemMessage(content='The human asks for a detailed introduction to the LangChain framework. The AI explains that LangChain is a framework designed for building applications based on large language models (LLMs), offering functionality for interacting with external data, automating tasks, and processing various data sources. The framework is especially useful for scenarios like building chat systems, document retrieval, API calls, and task automation.\n\nThe AI then breaks down LangChain’s core components and usage, starting with LLM integration, prompt templates, chains, agents, memory, document loaders, and tools & APIs. Examples for each component are provided to demonstrate practical implementation.\n\nFinally, the AI compares LangChain to other frameworks, highlighting its advantages such as chain operations, external tool integration, memory management, and modularity, making it a versatile choice for developing complex LLM applications. LangChain is presented as a flexible toolset for tasks ranging from customer service to automated workflows, with an emphasis on its ability to handle complex tasks efficiently.\n\nEND OF SUMMARY.')]}
========================
Human:
4.3 历史消息的存储
在前两个示例中,程序重启之后,大语言模型的历史记忆就会丢失,因为在BaseChatMemory内部默认使用的聊天消息历史组件是基于内存存储的InMemoryChatMessageHistory对象,接下来我们将以FileChatMessageHistory为例,将历史消息持久化到当前目录的chat_history.txt文件中,示例代码如下:
from operator import itemgetter
import dotenv
from langchain.memory import ConversationBufferMemory
from langchain_community.chat_message_histories import FileChatMessageHistory
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
from langchain_core.runnables import RunnablePassthrough, RunnableLambda
from langchain_openai import ChatOpenAI
# 读取env配置
dotenv.load_dotenv()
# 1.创建提示词模板
prompt = ChatPromptTemplate.from_messages([
MessagesPlaceholder("chat_history"),
("human", "{question}"),
])
# 2.构建GPT-3.5模型
llm = ChatOpenAI(model="gpt-3.5-turbo")
# 3.创建输出解析器
parser = StrOutputParser()
memory = ConversationBufferMemory(
return_messages=True,
chat_memory=FileChatMessageHistory("chat_history.txt")
)
# 4.执行链
chain = RunnablePassthrough.assign(
chat_history=(RunnableLambda(memory.load_memory_variables) | itemgetter("history"))
) | prompt | llm | parser
while True:
question = input("Human:")
response = chain.invoke({"question": question})
print(f"AI:{response}")
memory.save_context({"human": question}, {"ai": response})
执行上面的程序,进行对话
Human:你好,我是大志,你是
AI:你好,大志!我是ChatGPT,很高兴认识你。你今天怎么样?
Human:我的名字是
AI:哦,你的名字是大志!刚才我理解错了。那你平时喜欢做什么?
Human:
执行了两轮对话后,在当前目录就会生成保存了聊天历史消息的chat_history.txt文件。

chat_history.txt 文件内容
[{"type": "human", "data": {"content": "\u4f60\u597d\uff0c\u6211\u662f\u5927\u5fd7\uff0c\u4f60\u662f", "additional_kwargs": {}, "response_metadata": {}, "type": "human", "name": null, "id": null, "example": false}}, {"type": "ai", "data": {"content": "\u4f60\u597d\uff0c\u5927\u5fd7\uff01\u6211\u662fChatGPT\uff0c\u5f88\u9ad8\u5174\u8ba4\u8bc6\u4f60\u3002\u4f60\u4eca\u5929\u600e\u4e48\u6837\uff1f", "additional_kwargs": {}, "response_metadata": {}, "type": "ai", "name": null, "id": null, "example": false, "tool_calls": [], "invalid_tool_calls": [], "usage_metadata": null}}, {"type": "human", "data": {"content": "\u6211\u7684\u540d\u5b57\u662f", "additional_kwargs": {}, "response_metadata": {}, "type": "human", "name": null, "id": null, "example": false}}, {"type": "ai", "data": {"content": "\u54e6\uff0c\u4f60\u7684\u540d\u5b57\u662f\u5927\u5fd7\uff01\u521a\u624d\u6211\u7406\u89e3\u9519\u4e86\u3002\u90a3\u4f60\u5e73\u65f6\u559c\u6b22\u505a\u4ec0\u4e48\uff1f", "additional_kwargs": {}, "response_metadata": {}, "type": "ai", "name": null, "id": null, "example": false, "tool_calls": [], "invalid_tool_calls": [], "usage_metadata": null}}]
关闭程序,重新启动程序,大语言模型依然记得用户的名字。
Human:我的名字是什么
AI:你的名字是大志! 有什么想分享的关于这个名字的故事吗?
Human:
五、总结
本文介绍了LangChain记忆组件的核心概念和使用方法。通过记忆组件有效解决了大语言模型"失忆"的问题,能让AI记住多轮上下文对话。LangChain提供了多种记忆组件,在实际应用中,需要根据具体场景选择合适的记忆组件和存储方式。
开发阶段可以使用基于内存的InMemoryChatMessageHistory,生产环境建议选择FileChatMessageHistory或RedisChatMessageHistory进行持久化存储。需要注意的是,记忆组件会增加token消耗,要在用户体验和成本控制之间找到平衡点。
通过本文的学习,相信你已经能够熟练使用这些记忆组件,构建出有良好用户体验的AI应用,后续将继续深入介绍LangChain的核心模块和高级用法,敬请期待。
LangChain框架入门08:全方位解析记忆组件的更多相关文章
- 【原创】NIO框架入门(四):Android与MINA2、Netty4的跨平台UDP双向通信实战
概述 本文演示的是一个Android客户端程序,通过UDP协议与两个典型的NIO框架服务端,实现跨平台双向通信的完整Demo. 当前由于NIO框架的流行,使得开发大并发.高性能的互联网服务端成为可能. ...
- 【原创】NIO框架入门(二):服务端基于MINA2的UDP双向通信Demo演示
前言 NIO框架的流行,使得开发大并发.高性能的互联网服务端成为可能.这其中最流行的无非就是MINA和Netty了,MINA目前的主要版本是MINA2.而Netty的主要版本是Netty3和Netty ...
- 【原创】NIO框架入门(一):服务端基于Netty4的UDP双向通信Demo演示
申明:本文由作者基于日常实践整理,希望对初次接触MINA.Netty的人有所启发.如需与作者交流,见文签名,互相学习. 学习交流 更多学习资料:点此进入 推荐 移动端即时通讯交流: 215891622 ...
- Selenium自动化测试框架入门整理
关注嘉为科技,获取运维新知 本文主要针对Selenium自动化测试框架入门整理,只涉及总体功能及框架要点介绍说明,以及使用前提技术基础要求整理说明.作为开发人员.测试人员入门参考. 本文参考:Se ...
- CI框架入门笔记
当前(2019-03-22)CodeIgniter 框架的最新版本是 3.1.5,于2017年6月发布,距今快两年了也没有更新,这与 Laravel 的更新速度相比差距太大了.因为确实,它是一个很古老 ...
- 『Scrapy』爬虫框架入门
框架结构 引擎:处于中央位置协调工作的模块 spiders:生成需求url直接处理响应的单元 调度器:生成url队列(包括去重等) 下载器:直接和互联网打交道的单元 管道:持久化存储的单元 框架安装 ...
- AG-Admin微服务框架入门
AG-Admin微服务框架入门 @qq群:一群: 837736451 二群 169824183 一 概要介绍 AG-Admin后台地址:https://gitee.com/minull/ace-s ...
- 【python】Scrapy爬虫框架入门
说明: 本文主要学习Scrapy框架入门,介绍如何使用Scrapy框架爬取页面信息. 项目案例:爬取腾讯招聘页面 https://hr.tencent.com/position.php?&st ...
- [Python] Scrapy爬虫框架入门
说明: 本文主要学习Scrapy框架入门,介绍如何使用Scrapy框架爬取页面信息. 项目案例:爬取腾讯招聘页面 https://hr.tencent.com/position.php?&st ...
- Newbe.Claptrap 框架入门,第二步 —— 创建项目
接上一篇 Newbe.Claptrap 框架入门,第一步 -- 开发环境准备 ,我们继续了解如何创建一个 Newbe.Claptrap 项目. Newbe.Claptrap 是一个用于轻松应对并发问题 ...
随机推荐
- Vim编辑器基本用法
热门的Linux操作系统中都会默认安装一款文本编辑器-----Vim.它有三种模式:命令模式,末行模式和编辑模式. 命令模式 控制光标的移动,可对文本进行删除,复制,粘贴. 输入模式 正常的文本录入 ...
- CentOS使用yum update更新时不升级内核的方法
RedHat/CentOS/Fedora使用 yum update 更新时,默认会升级内核.但有些服务器硬件(特别是组装的机器)在升级内核后,新的内核可能会认不出某些硬件,要重新安装驱动,很麻烦.所以 ...
- 布局控件:Grid和StackPanel
布局控件:Grid和StackPanel 本文同时为b站WPF课程的笔记,相关示例代码 一个窗口顶上的部分叫做非客户区,下面的部分叫做客户区域.非客户区域主要就是一个Title和三个窗口样式按钮.我们 ...
- 「Note」树论方向
1. 重链剖分 1.1. 简介 重链剖分将树分割成若干链维护信息,将树的结构转换为线性结构,然后可用其他数据结构维护. 定义以下概念: 重子节点 轻子节点 重边 轻边 重链 某节点的子节点中子树大小最 ...
- Kubernetes存储-Ceph存储
Kubernetes存储-Ceph存储 原文链接:https://www.qikqiak.com/k8strain/storage/ceph/#_11 简介 Ceph 是一个统一的分布式存储系统,提供 ...
- Django中的文件操作
一.静态文件的加载 1.使用步骤 ①.在工程目录下创建static目录,创建css/js/images等目录,并添加相关资源 ②.在settings.py中配置STATICFILES_DIRS STA ...
- 使用rust给图片增加文字
使用rust实现在图片上增加文字信息(水印) [dependencies] image = "0.25" # 图像读写与基础操作 imageproc = "0.25&qu ...
- 数栈技术分享:开源·数栈-扩展FlinkSQL实现流与维表的join
一.扩展FlinkSQL实现流与维表的join 二.为什么要扩展FlinkSQL? 1.实时计算需要完全SQL化 SQL是数据处理中使用最广泛的语言.它允许用户简明扼要地声明他们的业务逻辑.大数据 ...
- RL Swarm:去中心化强化学习协作训练平台
项目概述 RL Swarm 是由Gensyn团队维护的去中心化强化学习协作训练平台.该系统允许用户加入"蜂群"与其他参与者共同训练模型,利用集体智能提升训练效率.核心特点包括: 真 ...
- .NET 5在Docker中访问MSSQL报错
不知道你有没有在.NET Core/.NET 5的Docker访问MS SQL Server数据库,如果有,那么很有可能会遇到这个错误. 1 SSL版本错误 最近在公司用.NET 5重构部分业务服务, ...