kafka各个版本的特性
1. kafka-0.8.2 新特性
1.1 异步发送
producer不再区分同步(sync)和异步方式(async),所有的请求以异步方式发送,这样提升了客户端效率。producer请求会返回一个应答对象,包括偏移量或者错误信。
这种异步方地批量的发送消息到kafka broker节点,因而可以减少server端资源的开销。新的producer和所有的服务器网络通信都是异步地,在
ack=-1模式下需要等待所有的replica副本完成复制时,可以大幅减少等待时间
1.2 偏移量保存方式
在0.8.2之前,comsumer定期提交已经消费的kafka消息的offset位置到zookeeper中保存。
对zookeeper而言,每次写操作代价是很昂贵的,而且zookeeper集群是不能扩展写能力的。在0.8.2开始,可以把comsumer提交的offset记录在compacted topic(__comsumer_offsets)中,该topic设置最高级别的持久化保证,即ack=-1。__consumer_offsets由一个三元组< comsumer group, topic, partiotion> 组成的key和offset值组成,在内存也维持一个最新的视图view,所以读取很快。
1.3 CheckPoint
kafka可以频繁的对offset做检查点checkpoint,即使每消费一条消息提交一次offset。
在0.8.1中,已经实验性的加入这个功能,0.8.2中可以广泛使用。
1.4 auto rebalancing
auto rebalancing的功能主要解决broker节点重启后,leader partition在broker节点上分布不均匀,比如会导致部分节点网卡流量过高,负载比其他节点高出很多。
auto rebalancing主要配置如下:
controlled.shutdown.enable ,是否在在关闭broker时主动迁移leader partition。
基本思想是每次kafka接收到关闭broker进程请求时,主动把leader partition迁移到其存活节点上,即follow replica提升为新的leader partition。如果没有开启这个参数,集群等到replica会话超时,controller节点才会重现选择新的leader partition,这些leader partition在这段时间内也不可读写。如果集群非常大或者partition 很多,partition不可用的时间将会比较长。
1)可以关闭unclean.leader.election,也就是不在ISR(IN-Sync Replica)列表中的replica,不会被提升为新的leader partition。unclean.leader.election=false时,kafka集群的持久化力大于可用性,如果ISR中没有其它的replica,会导致这个partition不能读写。
2)设置min.isr(默认值1)和 producer使用ack=-1,提高数据写入的持久性。当producer设置了ack=-1,如果broker发现ISR中的replica个数小于min.isr的值,broker将会拒绝producer的写入请求。max.connections.per.ip限制每个客户端ip发起的连接数,避免broker节点文件句柄被耗光。
2. kafka-0.9 新特性
2.1 安全特性
在0.9之前,Kafka安全方面的考虑几乎为0,在进行外网传输时,只好通过Linux的防火墙、或其他网络安全方面进行配置。相信这一点,让很多用户在考虑使用Kafka进行外网消息交互时有些担心。
在0.9之后,kafka集群提高了安全性,目前支持以下的安全措施:
- 客户端连接borker使用SSL或SASL进行验证
- borker连接ZooKeeper进行权限管理
- 数据传输进行加密(需要考虑性能方面的影响)
- 客户端读、写操作可以进行授权管理
- 可以对外部的可插拔模块的进行授权管理
当然,安全配置方面是可选的,可以混合使用。如:做过安全配置的的borkers和没有进行安全配置的borkers放在同一集群,授权的客户端和没有授权的客户端,也可以在同一个集群等等。具体配置详见官方文档。
2.2 Kafka Connect
这个功能模块,也是之前版本没有的。可以从名称看出,它可以和外部系统、数据集建立一个数据流的连接,实现数据的输入、输出。有以下特性:
- 使用了一个通用的框架,可以在这个框架上非常方面的开发、管理Kafka Connect接口
- 支持分布式模式或单机模式进行运行
- 支持REST接口,可以通过REST API提交、管理 Kafka Connect集群
- offset自动管理
同时,官方文档中,也给出了例子。通过配置,往一个文本文件中输入数据,数据可以实时的传输到Topic中。在进行数据流或者批量传输时,是一个可选的解决方案。
2.3 新的Comsumer API
新的Comsumer API不再有high-level、low-level之分了,而是自己维护offset。这样做的好处是避免应用出现异常时,数据未消费成功,但Position已经提交,导致消息未消费的情况发生。通过查看API,新的Comsumer API有以下功能:
- Kafka可以自行维护Offset、消费者的Position。也可以开发者自己来维护Offset,实现相关的业务需求。
- 消费时,可以只消费指定的Partitions
- 可以使用外部存储记录Offset,如数据库之类的。
- 自行控制Consumer消费消息的位置。
- 可以使用多线程进行消费
3. kafka-0.10 新特性
3.1 机架感知
和Hadoop一样,Kafka现在也实现了机架感知。如果所有备份都在单个机架上,那么一旦这个机架出问题,那么所有的备份都将失效。现在Kafka会让备份分布在不同的机架上,显著的提高了可用性。
3.2 Message中加入Timestamp
在Message中加入了Timestamp,如果没有被用户声明,该字段会被自动设为被发送的时间。这使得Kafka Streams实现了基于时间事件的流处理,你也可以使用Timestamp来实现消息的追踪查找。除次之外Message中还加入了checksum(但并不是保存在Kafka中,只是取出来之后计算),可以以比较小的代价比对Message。
3.3 引入新的安全特性
Apache Kafka 0.9.0.0版本引入了新的安全特性,包括通过SASL支持Kerberos。Apache Kafka 0.10.0.0现在支持更多的SASL特性,包括外部授权服务器,在一台服务器上支持多种类型的SASL认证以及其他的改进。
3.4 协议版本改进
Kafka brokers支持返回所有支持的协议版本的请求API,这个特点的好处就是以后将允许一个客户端支持多个broker版本。在Kafka 0.10.2.0之前,Kafka服务器端和客户端版本之间的兼容性是“单向”的,即高版本的broker可以处理低版本client的请求。反过来,低版本的broker不能处理高版本client的请求。
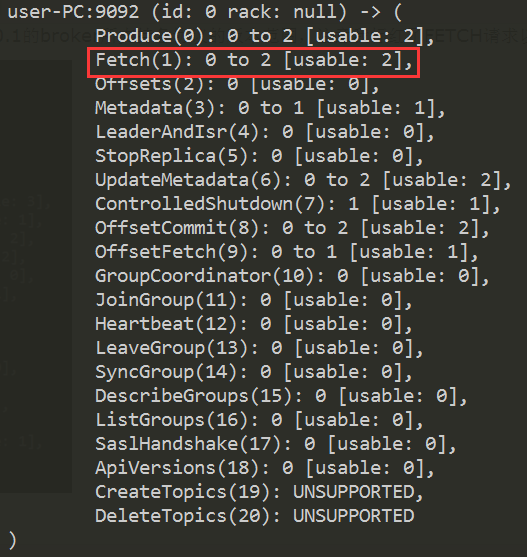
可以运行命令先查看当前broker支持的协议版本,然后再选择broker支持的最高版本封装请求即可。命令格式如下(在client端运行该命令):
/usr/hdp/2.3.4.0-3485/kafka/bin/kafka-broker-api-versions.sh --bootstrap-server broker_ip:port
下面两张图分别表示查看0.10.2.0和0.10.0.1的broker所支持各协议的版本范围,注意我标红了FETCH请求以示区别:
4. kafka-0.11 新特性
Apache Kafka近日推出0.11版本。这是一个里程碑式的大版本,特别是Kafka从这个版本开始支持“exactly-once”语义(下称EOS, exactly-once semantics)。本文简要介绍一下0.11版本主要的功能变更。
4.1 修改unclean.leader.election.enabled默认值
Kafka社区终于下定决心要把这个参数的默认值改成false,即不再允许出现unclean leader选举的情况,在正确性和高可用性之间选择了前者。如果依然要启用它,用户需要显式地设置server.properties=true
4.2 确保offsets.topic.replication.factor参数被正确应用
__consumer_offsets这个topic是Kafka自动创建的,在创建的时候如果集群broker数 < offsets.topic.replication.factor,原先的版本取其小者,但这会违背用户设置该参数的初衷。因此在0.11版本中这个参数会被强制遵守,如果不满足该参数设定的值,会抛出GROUP_COORDINATOR_NOT_AVAILABLE。
4.3 优化了对Snappy压缩的支持
之前由于源代码中硬编码了block size,使得producer使用Snappy时的表现比LZ4相差很多,但其实Snappy和LZ4两者之差距不应该很大。故此0.11版本中对Snappy的默认block size做了调整。不过这一点需要详尽的性能测试报告来证明此改动是有效的。
4.4 消息增加头部信息(Header)
Record增加了Header,每个header是一个KV存储。具体的header设计参见KIP-82
4.5 空消费者组延时rebalance
为了缩短多consumer首次rebalance的时间,增加了“group.initial.rebalance.delay.ms”用于设置group开启rebalance的延时时间。这段延时期间允许更多的consumer加入组,避免不必要的JoinGroup与SyncGroup之间的切换。当然凡事都是trade-off,引入这个必然带来消费延时。
4.6 消息格式变更
增加最新的magic值:2。增加了header信息。同时为了支持幂等producer和EOS,增加一些与事务相关的字段,使得单个record数据结构体积增加。但因为优化了RecordBatch使得整个batch所占体积反而减少,进一步降低了网络IO开销。
4.7 新的分配算法:StickyAssignor
比range和round-robin更加平衡的分配算法。指定partition.assignment.strategy = org.apache.kafka.clients.consumer.StickyAssignor可以尝尝鲜。不过根据我的经验,分配不均匀的情况通常发生在每个consumer订阅topic差别很大的时候。比如consumer1订阅topic1, topic2, topic4, consumer2订阅topic3, topic4这种情况
4.8 controller重设计
Controller原来的设计非常复杂,使得社区里面的人几乎不敢改动controller代码。老版本controller的主要问题在我看来有2个:1. controller需要执行1,2,3,4,5,6步操作,倘若第3步出错了,无法回滚前两步的操作;2. 多线程访问,多个线程同时访问Controller上下文信息。0.11版本部分重构了controller,采用了单线程+基于事件队列的方式。具体效果咱们拭目以待吧~~
4.9 支持EOS
0.11最重要的功能,没有之一!EOS是流式处理实现正确性的基石。主流的流式处理框架基本都支持EOS(如Storm Trident, Spark Streaming, Flink),Kafka streams肯定也要支持的。0.11版本通过3个大的改动支持EOS:1.幂等的producer(这也是千呼万唤始出来的功能);2. 支持事务;3. 支持EOS的流式处理(保证读-处理-写全链路的EOS)
kafka各个版本的特性的更多相关文章
- kafka各个版本特点介绍和总结
kafka各个版本特点介绍和总结 1.1 kafka的功能特点: 分布式消息队列 消息队列的数据模型, 形成流式数据. 提供Pub/Sub方式的海量消息处理.以高容错的方式存储海量数据流.保证数据流的 ...
- Atitit opencv版本新特性attilax总结
Atitit opencv版本新特性attilax总结 1.1. :OpenCV 3.0 发布,史上功能最全,速度最快的版1 1.2. 应用领域2 1.3. OPENCV2.4.3改进 2.4.2就有 ...
- Atitit mac os 版本 新特性 attilax大总结
Atitit mac os 版本 新特性 attilax大总结 1. Macos概述1 2. 早期2 2.1. Macintosh OS (系统 1.0) 1984年2 2.2. Mac OS 7. ...
- IOS第三天-新浪微博 - 版本新特性,OAuth授权认证
*********版本新特性 #import "HWNewfeatureViewController.h" #import "HWTabBarViewController ...
- 【开源】OSharp3.3框架解说系列:重新开源及3.3版本新特性
OSharp是什么? OSharp是个快速开发框架,但不是一个大而全的包罗万象的框架,严格的说,OSharp中什么都没有实现.与其他大而全的框架最大的不同点,就是OSharp只做抽象封装,不做实现.依 ...
- Atitit 发帖机系列(8) 词法分析器v5 版本新特性说明)
Atitit 发帖机系列(8) 词法分析器v5 版本新特性说明) v5 增加对sql单引号的内部支持.可以作为string 结构调整,使用递归法重构循环发..放弃循环发. V4 java dsl词 ...
- [iOS微博项目 - 1.7] - 版本新特性
A.版本新特性 1.需求 第一次使用新版本的时候,不直接进入app,而是展示新特性界面 github: https://github.com/hellovoidworld/HVWWeibo ...
- framework各版本新特性(为面试准备)
菜鸟D估计描述这些新特性的文章都是烂大街的货色,之所以拿出来分(e)享(xin)一下,有两个原因:1.当年面试的时候有人问到,我不知道该怎么回答:2.项目需要发布了,但是考虑到framework的版本 ...
- CAP 2.4版本发布,支持版本隔离特性
前言 自从上次 CAP 2.3 版本发布 以来,已经过去了几个月的时间,这几个月比较忙,所以也没有怎么写博客,趁着2019年到来之际(现在应该是2019年开始的时候),CAP也发布了2018年的最后一 ...
- flink引出的kafka不同版本的兼容性
参考: 官网协议介绍:http://kafka.apache.org/protocol.html#The_Messages_Fetch kafka协议兼容性 http://www.cnblogs.c ...
随机推荐
- 通过脚手架 npx 创建 react 项目
npx create-react-app create-react --template typescript 使用 ts 模板
- feign在服务间传递header
场景: 用户登陆后,再次访问网页,将用户信息loginToken放在request的header中,首先经过网关,然后到达A服务,然后A服务调用B服务时如何把loginToken传递给B服务 1.修改 ...
- 操作系统_MPI程序设计
一.实验环境搭建 本次MPI集群环境是在电脑中安装mpi的sdk和应用程序后在visual studio 2022 上配置MPI环境. VC++目录--->包含目录--->添加MPI的in ...
- javap和字节码
javap 字节码的基本信息 public class Test { private int age = 10; public int getAge() { return age; } } 在 cla ...
- Unreal RecastNavigation 开源项目详解
0 前言 Recastnavigation是一个游戏AI导航库,像Unity,UE引擎中都集成了这个开源项目, HALO中使用的也是这个开源库.导航最重要的就是为NPC寻路,以及其他的寻路需求. 需要 ...
- AI五子棋_06 坐标表示到图形表示的算法 Python实现
AI五子棋 第六步 恭喜你到达第六步! 你已经成功实现了公钥体系最为关键的部分.现在服务器相信你就是你了,下面开始你的战斗. 五子棋的棋盘有15×15个交点,一共有225个交点,我们可以在每一个交点上 ...
- 项目中maven依赖无法自动下载
[解决方法]: 安装目录conf--修改settting.xml文件在mirrors标签下添加子节点 <mirrors> <!-- mirror | Specifies a repo ...
- 手写MSMQ微软消息队列收发工具类
一.MSMQ介绍 MSMQ(Microsoft Message Queuing)是微软开发的消息队列技术,支持事务,支持异步发送和接收消息. 两个重要的概念:队列和消息.队列是存放消息的容器和传输消息 ...
- html 根据配置项统一检查文本框数据规范
<div> 中文名:<input id="txtName" type="text" /><br /> 身份证号:<in ...
- Bootstrap 栅栏布局中 col-xs-*、col-sm-*、col-md-*、col-lg-* 区别及使用方法 _2021-11-10
Bootstrap 栅栏布局中 col-xs-.col-sm-.col-md-.col-lg- 区别及使用方法 全文转自:https://www.cnblogs.com/tangbohu2008/p/ ...