第三届LitCTFmisc详解
Misc
Cropping
随波逐流伪加密,得到一堆图片,把图片拼接起来
脚本
import os
from PIL import Image
def stitch_tiles_horizontally_with_wrap(tiles_folder, output_file, tiles_per_row=10):
"""
横向拼接图片,达到指定数量后自动换行
参数:
tiles_folder: 包含拼图块的文件夹路径
output_file: 输出拼接后图片的文件路径
tiles_per_row: 每行拼接的图片数量(默认为10)
"""
# 获取所有拼图块文件并按数字顺序排序
tile_files = sorted(
[f for f in os.listdir(tiles_folder) if f.startswith('tile_') and f.endswith('.png')],
key=lambda x: int(x.split('_')[1].split('.')[0]))
if not tile_files:
print("未找到任何拼图块文件(tile_*.png)")
return
# 打开所有图片
images = []
tile_width = 0
tile_height = 0
for file in tile_files:
try:
img = Image.open(os.path.join(tiles_folder, file))
images.append(img)
# 假设所有图片尺寸相同,取第一张的尺寸
if tile_width == 0:
tile_width = img.width
tile_height = img.height
print(f"已加载: {file}")
except Exception as e:
print(f"无法加载图片 {file}: {e}")
if not images:
print("没有有效的图片可拼接")
return
# 计算画布尺寸
rows = (len(images) + tiles_per_row - 1) // tiles_per_row # 计算需要的行数
result_width = tile_width * min(tiles_per_row, len(images)) # 画布宽度
result_height = tile_height * rows # 画布高度
# 创建空白画布
result = Image.new('RGB', (result_width, result_height))
# 开始拼接
for index, img in enumerate(images):
# 计算当前图片应该放在哪一行哪一列
row = index // tiles_per_row
col = index % tiles_per_row
# 计算粘贴位置
x = col * tile_width
y = row * tile_height
result.paste(img, (x, y))
# 保存结果
result.save(output_file)
print(f"拼接完成! 共拼接了 {len(images)} 张图片,排列为 {rows} 行")
print(f"结果已保存到: {output_file} (尺寸: {result_width}x{result_height})")
# 使用示例
if __name__ == "__main__":
tiles_folder = "C:\\Users\\11141\\Desktop\\tiles" # 拼图块所在的文件夹
output_file = "stitched_with_wrap.jpg" # 输出文件
tiles_per_row = 10 # 每行10个图片
stitch_tiles_horizontally_with_wrap(tiles_folder, output_file, tiles_per_row)
扫二维码得flag
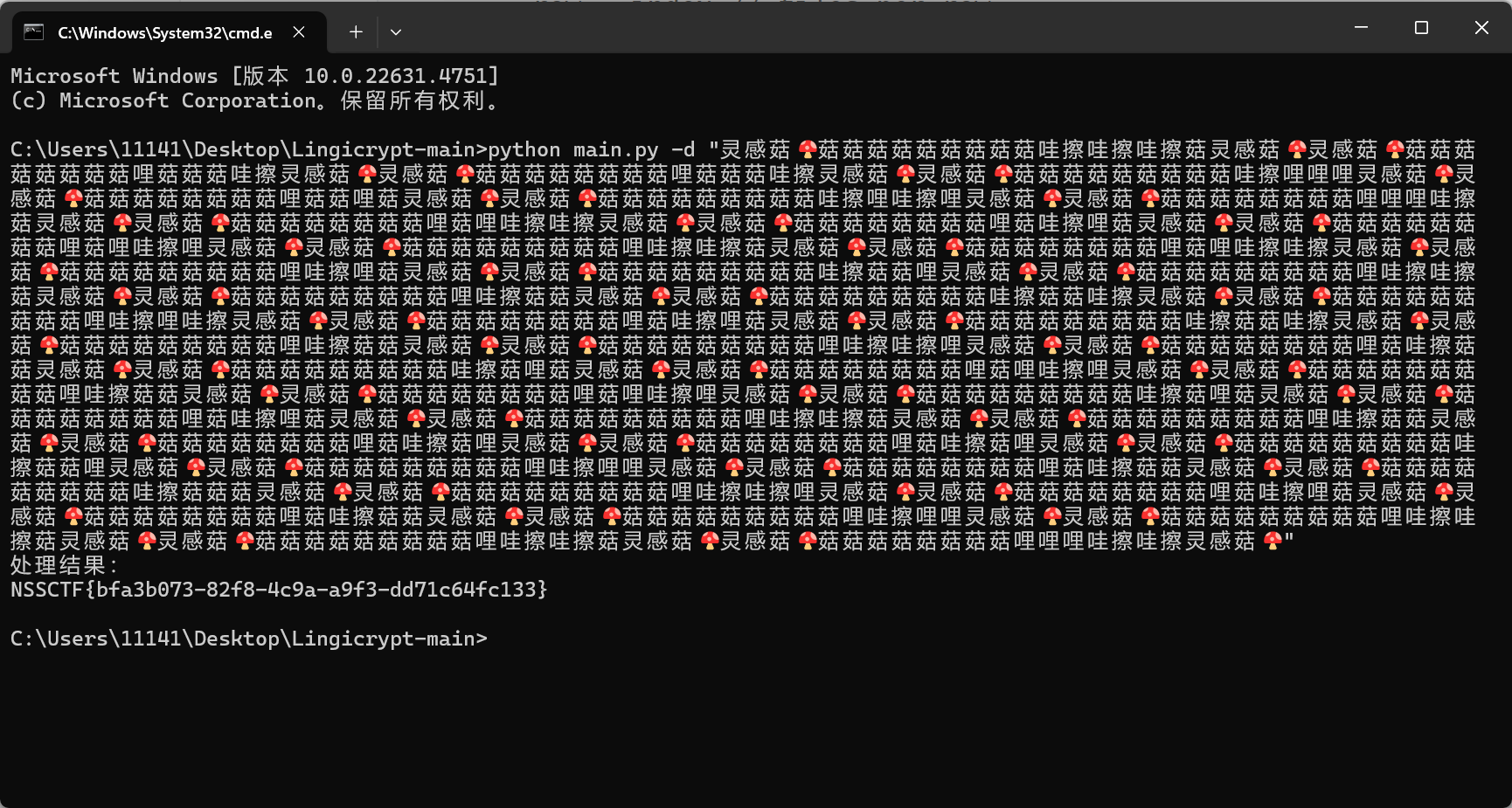
灵感菇哩菇哩菇哩哇擦灵感菇灵感菇
之前在交流群见过,没想到这么快就在比赛见到了
查看源代码,https://github.com/ProbiusOfficial/Lingicrypt
下载解密得flag
问卷题
扫码答题得flag
LitCTF{W3_Need_You_Next_Year==}
消失的文字
下载附件
usb流量一把梭

得到密码
868F-83BD-FF
解压zip得到txt
010发现嵌入隐藏字符

根据名字搜到
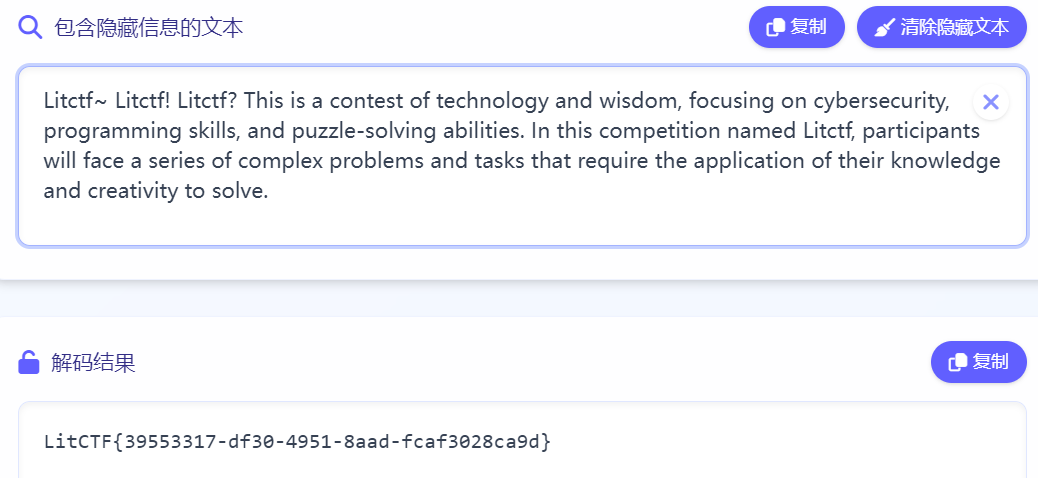
LitCTF{39553317-df30-4951-8aad-fcaf3028ca9d}
像素中的航班
下载图片
我们推理一下,长城杯决赛在4月底,决赛地在福州,litctf主办单位为郑州轻工业大学
搜郑州出发到福州的航班
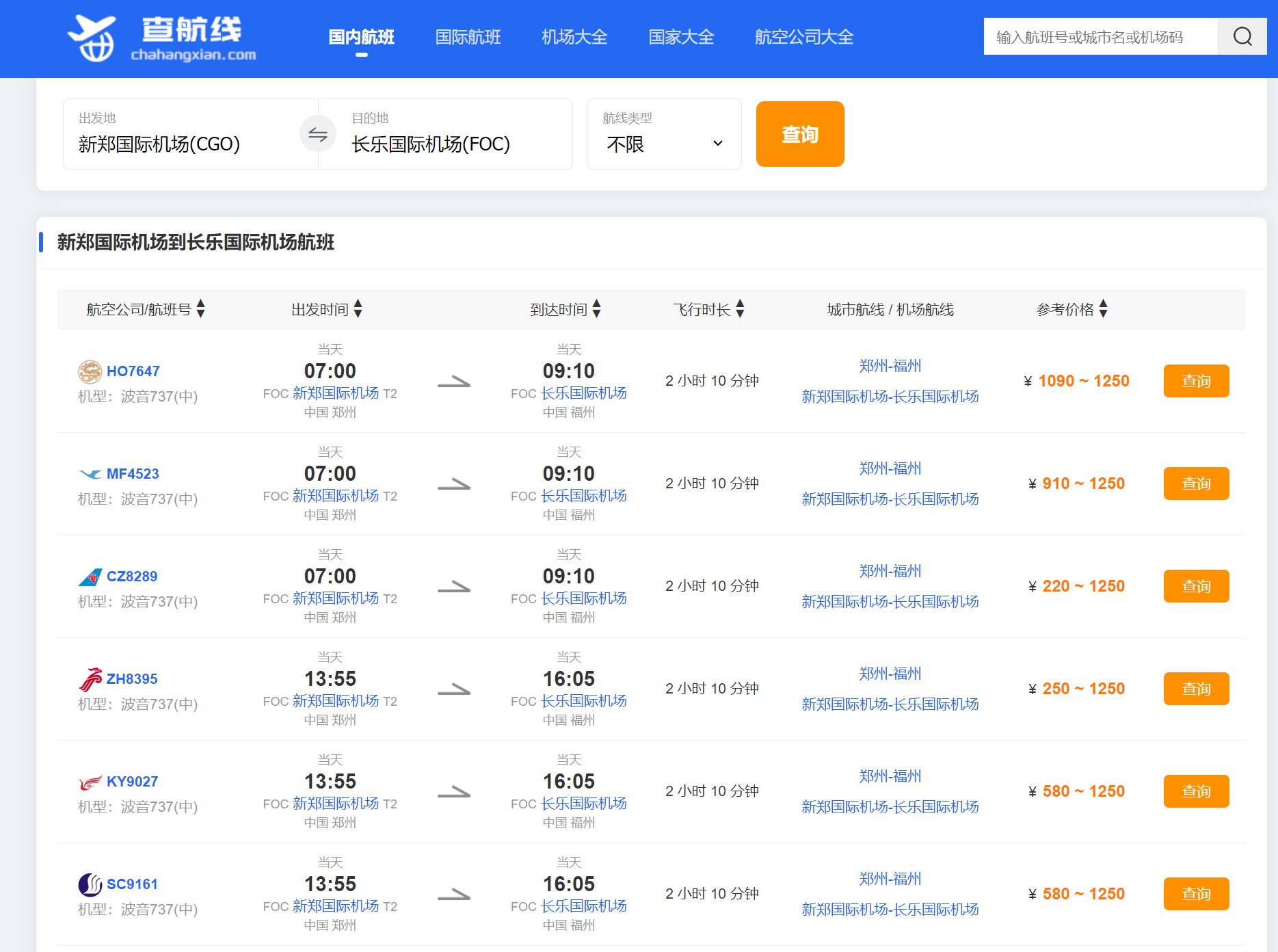
一个一个试,结束
LitCTF{CZ8289}
洞妖洞妖
解压ppt
改为zip后缀并解压,查看vbaPeoject.bin宏代码
工具github地址: https://github.com/decalage2/oletools
pip install -U oletools
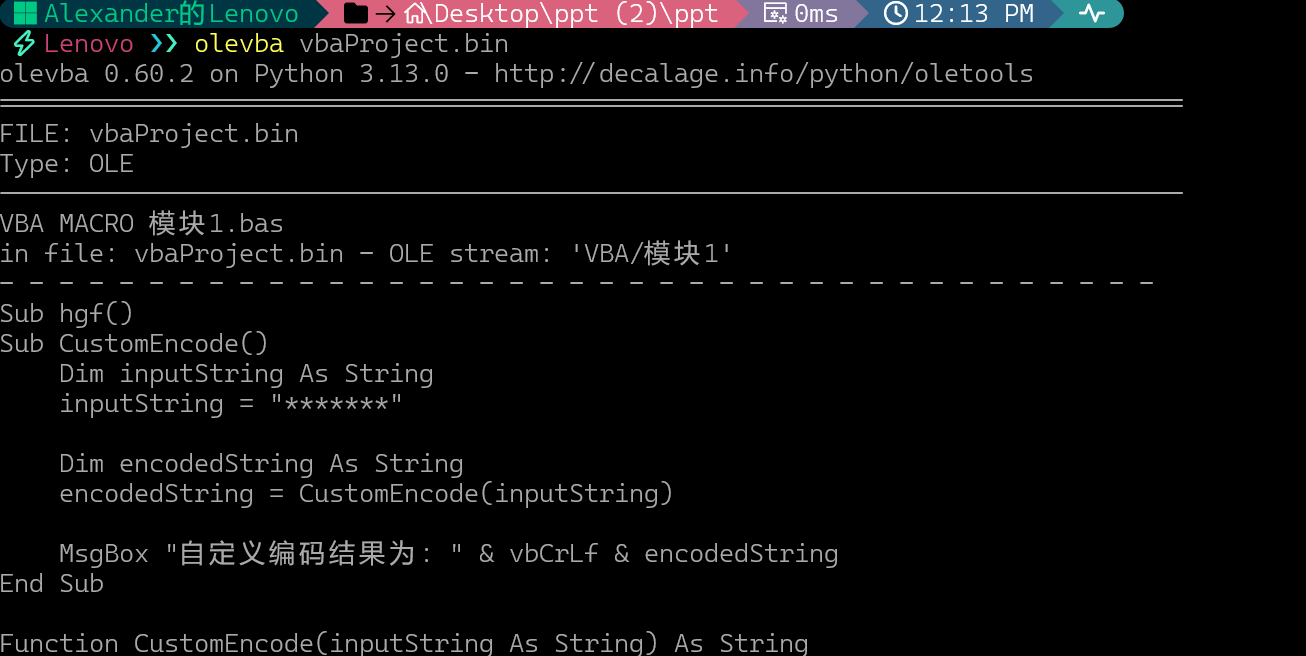
olevba 0.60.2 on Python 3.13.0 - http://decalage.info/python/oletools
===============================================================================
FILE: vbaProject.bin
Type: OLE
-------------------------------------------------------------------------------
VBA MACRO 模块1.bas
in file: vbaProject.bin - OLE stream: 'VBA/模块1'
- - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
Sub hgf()
Sub CustomEncode()
Dim inputString As String
inputString = "*******"
Dim encodedString As String
encodedString = CustomEncode(inputString)
MsgBox "自定义编码结果为: " & vbCrLf & encodedString
End Sub
Function CustomEncode(inputString As String) As String
Dim charSet As String
charSet = "*******************"
Dim byteArray() As Byte
byteArray = StrConv(inputString, vbFromUnicode)
Dim encodedString As String
encodedString = ""
Dim i As Integer
Dim n As Long
For i = 1 To LenB(byteArray) Step 3
n = 0
n = (n Or (ByteToInt(MidB(byteArray, i, 1)) << 16))
If i + 1 <= LenB(byteArray) Then
n = (n Or (ByteToInt(MidB(byteArray, i + 1, 1)) << 8))
End If
If i + 2 <= LenB(byteArray) Then
n = (n Or ByteToInt(MidB(byteArray, i + 2, 1)))
End If
encodedString = encodedString & Mid(charSet, (n >> 18) + 1, 1)
encodedString = encodedString & Mid(charSet, ((n >> 12) And &H3F) + 1, 1)
If (i + 1) <= LenB(byteArray) Then
encodedString = encodedString & Mid(charSet, ((n >> 6) And &H3F) + 1, 1)
Else
encodedString = encodedString & "="
End If
If (i + 2) <= LenB(byteArray) Then
encodedString = encodedString & Mid(charSet, (n And &H3F) + 1, 1)
Else
encodedString = encodedString & "="
End If
Next i
CustomEncode = encodedString
End Function
Function ByteToInt(byteVal As Byte) As Long
ByteToInt = CLng(byteVal)
End Function
End Function
"5uESz7on4R8eyC//"
+----------+--------------------+---------------------------------------------+
|Type |Keyword |Description |
+----------+--------------------+---------------------------------------------+
|Suspicious|Base64 Strings |Base64-encoded strings were detected, may be |
| | |used to obfuscate strings (option --decode to|
| | |see all) |
+----------+--------------------+---------------------------------------------+
换表base64加密

ppt帧间隔隐写
import os
import re
import argparse
from pathlib import Path
from typing import List, Dict, Set, Optional
import logging
from tqdm import tqdm
def setup_logging(log_file: Optional[str] = None) -> None:
"""配置日志记录"""
logging.basicConfig(
level=logging.INFO,
format="%(asctime)s - %(levelname)s - %(message)s",
handlers=[
logging.FileHandler(log_file) if log_file else logging.StreamHandler()
]
)
def find_slide_files(directory: str, slide_count: int = 456) -> Dict[int, str]:
"""查找并验证幻灯片文件"""
slide_files = {}
missing_files = []
for i in range(1, slide_count + 1):
file_name = f'slide{i}.xml'
file_path = os.path.join(directory, file_name)
if os.path.isfile(file_path):
slide_files[i] = file_path
else:
missing_files.append(file_name)
if missing_files:
logging.warning(f"找不到以下{len(missing_files)}个文件: {', '.join(missing_files[:10])}" +
(", ..." if len(missing_files) > 10 else ""))
return slide_files
def extract_advTm_values(file_path: str) -> Set[str]:
"""从单个文件中提取唯一的advTm值"""
try:
with open(file_path, 'r', encoding='utf-8') as f:
content = f.read()
# 使用非贪婪匹配确保正确提取每个值
return set(re.findall(r'advTm="(.*?)"', content))
except Exception as e:
logging.error(f"处理文件 {file_path} 时出错: {str(e)}")
return set()
def process_slide_files(slide_files: Dict[int, str]) -> Dict[int, List[str]]:
"""处理所有幻灯片文件并提取advTm值"""
results = {}
# 使用tqdm显示进度条
for slide_num, file_path in tqdm(slide_files.items(), desc="处理幻灯片"):
unique_values = extract_advTm_values(file_path)
if unique_values:
# 排序确保结果一致
results[slide_num] = sorted(unique_values)
return results
def write_results(results: Dict[int, List[str]], output_file: str) -> None:
"""将结果写入输出文件"""
try:
with open(output_file, 'w', encoding='utf-8') as f_out:
# 写入标题行
f_out.write("幻灯片编号, advTm值\n")
# 按幻灯片编号排序
for slide_num in sorted(results.keys()):
values = results[slide_num]
f_out.write(f"slide{slide_num}.xml, {', '.join(values)}\n")
logging.info(f"结果已保存到 {output_file}")
except Exception as e:
logging.error(f"写入结果文件时出错: {str(e)}")
def main():
"""主函数"""
parser = argparse.ArgumentParser(description='从PPT幻灯片文件中提取唯一的advTm值')
parser.add_argument('--directory', default='./slides', help='幻灯片文件所在目录')
parser.add_argument('--output', default='result.csv', help='输出结果文件')
parser.add_argument('--slide-count', type=int, default=456, help='预期的幻灯片数量')
parser.add_argument('--log-file', help='日志文件路径')
args = parser.parse_args()
setup_logging(args.log_file)
# 验证输入目录
if not os.path.isdir(args.directory):
logging.error(f"目录不存在: {args.directory}")
return
logging.info(f"开始处理幻灯片文件,目录: {args.directory}")
slide_files = find_slide_files(args.directory, args.slide_count)
if not slide_files:
logging.error("未找到有效的幻灯片文件")
return
results = process_slide_files(slide_files)
if not results:
logging.warning("未找到任何advTm值")
else:
write_results(results, args.output)
logging.info(f"处理完成。共处理 {len(slide_files)} 个文件,找到 {len(results)} 个包含advTm值的文件")
if __name__ == '__main__':
main()

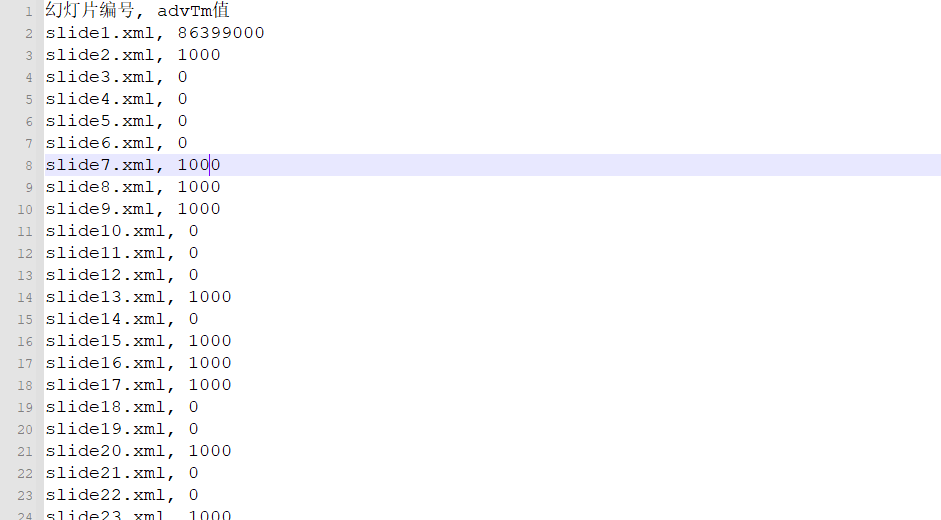
把1000替换成1,0不变,组成二进制数据
10000111000101110010011000111110111111011010110101110101100111011011011101100110101110010101110100111001111100101110001110000110101100111001011001101111010110111100001011110101111001111100001101100110101011010010110011011000101011110001101110000011000011011100101011100110110011001001011110101011010011001000110011111001101000100100000111000101010101110010110101001010011100111110100101010001101000011011111001001110100010001110111000011001001100010101111
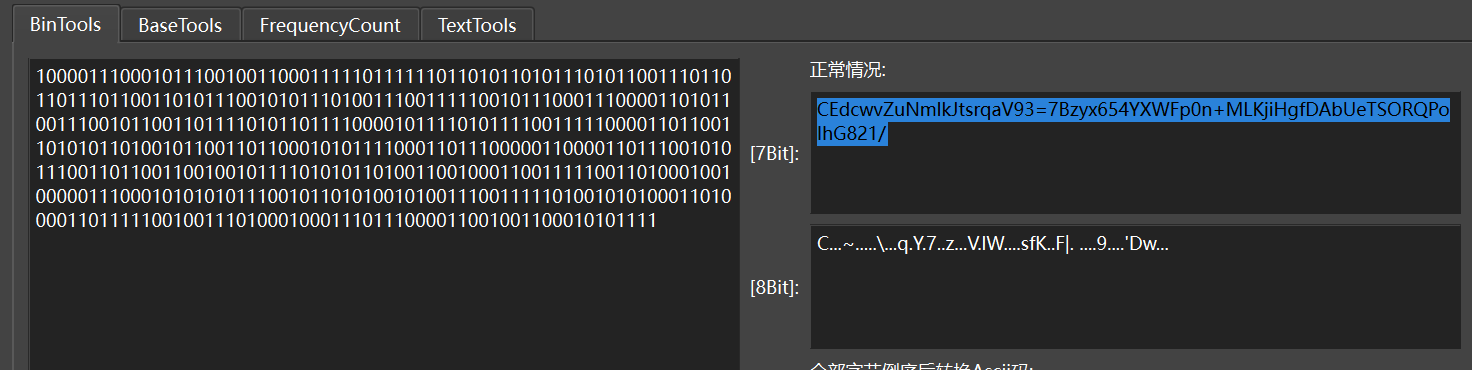
CEdcwvZuNmlkJtsrqaV93=7Bzyx654YXWFp0n+MLKjiHgfDAbUeTSORQPoIhG821/
得到表解密
def custom_decode(encoded_str):
# 自定义Base64字符表(包含填充字符)
custom_charset = "CEdcwvZuNmlkJtsrqaV93=7Bzyx654YXWFp0n+MLKjiHgfDAbUeTSORQPoIhG821/"
# 标准Base64字符表(不含填充字符)
standard_charset = "ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/"
# 先移除填充字符,后续再统一处理
encoded_str = encoded_str.replace('=', '')
# 将自定义Base64字符映射为标准Base64字符
standard_encoded = ''
for char in encoded_str:
# 查找字符在自定义字符表中的索引
idx = custom_charset.index(char)
# 处理特殊情况:自定义字符表中的填充字符(索引18)
if idx == 18: # 自定义表中的'='
continue # 跳过,后续统一添加填充
# 处理超出标准字符表范围的索引
if idx >= 64:
# 对索引取模,避免越界(这是一种简化处理方式)
idx = idx % 64
standard_encoded += standard_charset[idx]
# 补齐填充字符,使长度是4的倍数
while len(standard_encoded) % 4 != 0:
standard_encoded += '='
# 用标准Base64解码
import base64
try:
decoded_bytes = base64.b64decode(standard_encoded)
return decoded_bytes.decode('utf-8', errors='replace')
except Exception as e:
return f"解码失败: {str(e)}"
# 要解密的字符串
encoded_str = "5uESz7on4R8eyC//"
decoded_str = custom_decode(encoded_str)
print(f"解密结果: {decoded_str}")
pptandword
在ppt\media\image2.jpeg中有个倒转的zip
提取
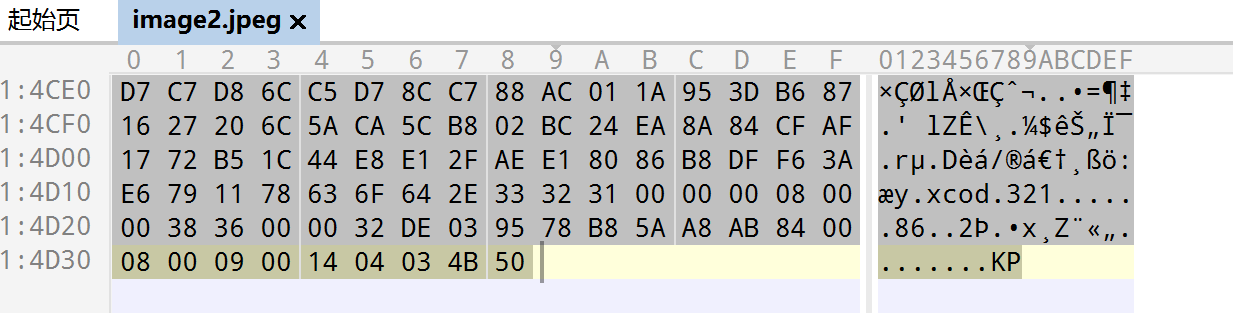
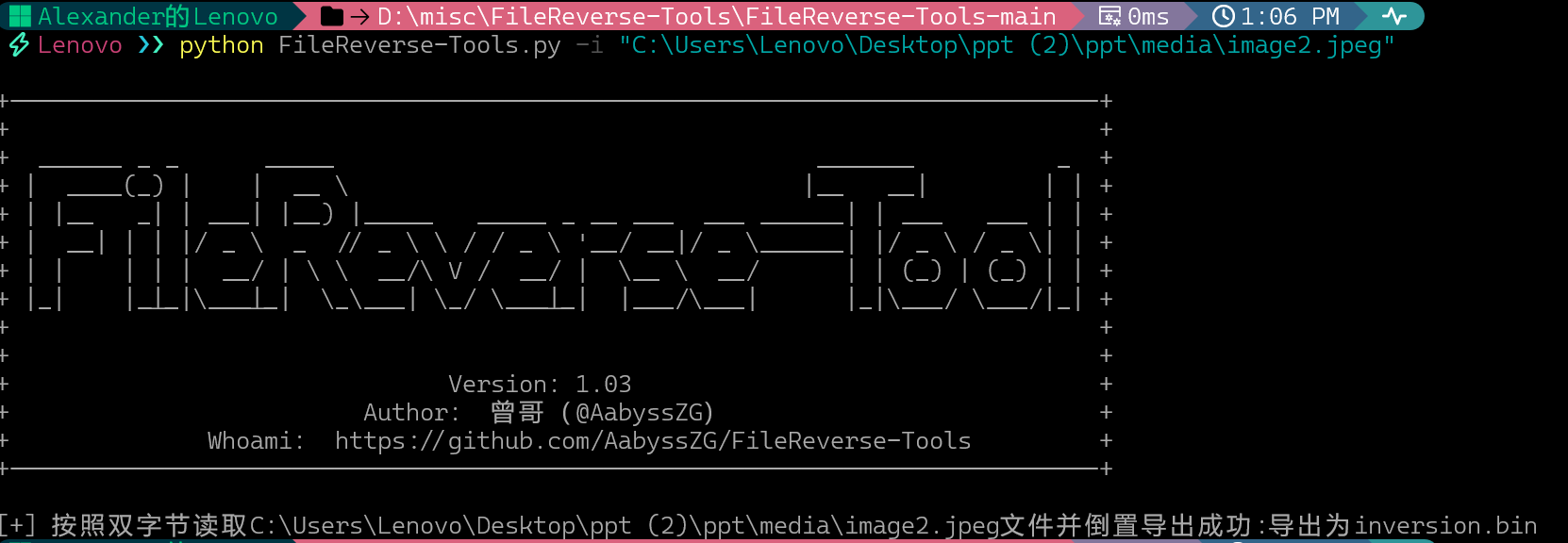
解压,打开docx

LitCTF{cfbff0d1-9345-5685-968c-48ce8b15ae17}
第三届LitCTFmisc详解的更多相关文章
- Linq之旅:Linq入门详解(Linq to Objects)
示例代码下载:Linq之旅:Linq入门详解(Linq to Objects) 本博文详细介绍 .NET 3.5 中引入的重要功能:Language Integrated Query(LINQ,语言集 ...
- 架构设计:远程调用服务架构设计及zookeeper技术详解(下篇)
一.下篇开头的废话 终于开写下篇了,这也是我写远程调用框架的第三篇文章,前两篇都被博客园作为[编辑推荐]的文章,很兴奋哦,嘿嘿~~~~,本人是个很臭美的人,一定得要截图为证: 今天是2014年的第一天 ...
- EntityFramework Core 1.1 Add、Attach、Update、Remove方法如何高效使用详解
前言 我比较喜欢安静,大概和我喜欢研究和琢磨技术原因相关吧,刚好到了元旦节,这几天可以好好学习下EF Core,同时在项目当中用到EF Core,借此机会给予比较深入的理解,这里我们只讲解和EF 6. ...
- Java 字符串格式化详解
Java 字符串格式化详解 版权声明:本文为博主原创文章,未经博主允许不得转载. 微博:厉圣杰 文中如有纰漏,欢迎大家留言指出. 在 Java 的 String 类中,可以使用 format() 方法 ...
- Android Notification 详解(一)——基本操作
Android Notification 详解(一)--基本操作 版权声明:本文为博主原创文章,未经博主允许不得转载. 微博:厉圣杰 源码:AndroidDemo/Notification 文中如有纰 ...
- Android Notification 详解——基本操作
Android Notification 详解 版权声明:本文为博主原创文章,未经博主允许不得转载. 前几天项目中有用到 Android 通知相关的内容,索性把 Android Notificatio ...
- Git初探--笔记整理和Git命令详解
几个重要的概念 首先先明确几个概念: WorkPlace : 工作区 Index: 暂存区 Repository: 本地仓库/版本库 Remote: 远程仓库 当在Remote(如Github)上面c ...
- Drawable实战解析:Android XML shape 标签使用详解(apk瘦身,减少内存好帮手)
Android XML shape 标签使用详解 一个android开发者肯定懂得使用 xml 定义一个 Drawable,比如定义一个 rect 或者 circle 作为一个 View 的背景. ...
- Node.js npm 详解
一.npm简介 安装npm请阅读我之前的文章Hello Node中npm安装那一部分,不过只介绍了linux平台,如果是其它平台,有前辈写了更加详细的介绍. npm的全称:Node Package M ...
- .NET应用和AEAI CAS集成详解
1 概述 数通畅联某综合SOA集成项目的统一身份认证工作,需要第三方系统配合进行单点登录的配置改造,在项目中有需要进行单点登录配置的.NET应用系统,本文专门记录.NET应用和AEAI CAS的集成过 ...
随机推荐
- phpinclude-labs做题记录
Level 1 file协议 payload:?wrappers=/flag Level 2 data协议 去包含data协议中的内容其实相当于进行了一次远程包含,所以data协议的利用条件需要 ph ...
- SpringSecurity学习笔记-前后端分离
1. 简介 Spring Security是Spring家族中的一个安全管理框架.相比于另外一个安全框架Shiro,它提供了更丰富的功能,社区资源也比Shiro丰富. 一般来说中大型的项目都是使用Sp ...
- k8s 报错: node(s) didn't match Pod's node affinity.
前言 k8s集群中,有pod出现了 Affinity ,使用 kubectl describe pod 命令,发现了报错 2 node(s) didn't match Pod's node affin ...
- python代码格式风格 PEP 8
前言 Python Enhancement Proposal #8叫做PEP 8,它是针对 Python 代码格式而编订的风格指南. 编写 Python 代码时,总是应该遵循 PEP 8 风格指南. ...
- mongodb 查看、创建、修改、删除索引
简介 索引通常能够极大的提高查询的效率,如果没有索引,MongoDB在读取数据时必须扫描集合中的每个文件并选取那些符合查询条件的记录. 这种扫描全集合的查询效率是非常低的,特别在处理大量的数据时,查询 ...
- 非常实用的aix 6.1系统安装的教程
今年六月,我们公司出现了一次非常严重的数据丢失的事故.生产服务器崩溃导致所有的业务都陷于停滞,而且由于涉及到公司机密又无法贸然到数据恢复公司进行恢复,可是自己又无法解决.权衡利弊还是决定找一家有保密资 ...
- Delphi 使用API函数AnimateWindow实现窗体特效功能
API函数 AnimateWindow 使用: 函数功能:窗体显示和隐藏时产生特殊的动画效果:可以产生两种类型的动画效果: 滚动动画 和 滑动动画 函数原型:BOOL AnimateWindow(HW ...
- MySQL 事务隔离级别:社交恐惧症的四个阶段
MySQL 事务隔离级别:社交恐惧症的四个阶段 在数据库的世界里,数据们也有社交问题!事务隔离级别就是控制它们互相看到对方的程度... 什么是事务隔离? 想象一下,数据库是一个繁忙的餐厅,每个事务都是 ...
- 【Docker】常用服务镜像安装
Docker常用安装 总体步骤 搜索镜像:docker search xxx 拉取镜像:docker pull xxx 查看镜像:docker images 启动镜像:docker run xxx 停 ...
- Spring AI与DeepSeek实战三:打造企业知识库
一.概述 企业应用集成大语言模型(LLM)落地的两大痛点: 知识局限性:LLM依赖静态训练数据,无法覆盖实时更新或垂直领域的知识: 幻觉:当LLM遇到训练数据外的提问时,可能生成看似合理但错误的内容. ...