sklearn中的投票法
投票法(voting)是集成学习里面针对分类问题的一种结合策略。基本思想是选择所有机器学习算法当中输出最多的那个类。
分类的机器学习算法输出有两种类型:一种是直接输出类标签,另外一种是输出类概率,使用前者进行投票叫做硬投票(Majority/Hard voting),使用后者进行分类叫做软投票(Soft voting)。 sklearn中的VotingClassifier是投票法的实现。
硬投票
硬投票是选择算法输出最多的标签,如果标签数量相等,那么按照升序的次序进行选择。下面是一个例子:
from sklearn import datasets
from sklearn.model_selection import cross_val_score
from sklearn.linear_model import LogisticRegression
from sklearn.naive_bayes import GaussianNB
from sklearn.ensemble import RandomForestClassifier
from sklearn.ensemble import VotingClassifier iris = datasets.load_iris()
X, y = iris.data[:,1:3], iris.target
clf1 = LogisticRegression(random_state=1)
clf2 = RandomForestClassifier(random_state=1)
clf3 = GaussianNB() eclf = VotingClassifier(estimators=[('lr',clf1),('rf',clf2),('gnb',clf3)], voting='hard')
#使用投票法将三个模型结合在以前,estimotor采用 [(name1,clf1),(name2,clf2),...]这样的输入,和Pipeline的输入相同 voting='hard'表示硬投票 for clf, clf_name in zip([clf1, clf2, clf3, eclf],['Logistic Regrsssion', 'Random Forest', 'naive Bayes', 'Ensemble']):
scores = cross_val_score(clf, X, y, cv=5, scoring='accuracy')
print('Accuracy: {:.2f} (+/- {:.2f}) [{}]'.format(scores.mean(), scores.std(), clf_name))
输出结果如下:
Accuracy: 0.90 (+/- 0.05) [Logistic Regrsssion]
Accuracy: 0.93 (+/- 0.05) [Random Forest]
Accuracy: 0.91 (+/- 0.04) [naive Bayes]
Accuracy: 0.95 (+/- 0.05) [Ensemble] 实际当中会报:DeprecationWarning
软投票
软投票是使用各个算法输出的类概率来进行类的选择,输入权重的话,会得到每个类的类概率的加权平均值,值大的类会被选择。
from itertools import product import numpy as np
import matplotlib.pyplot as plt from sklearn import datasets
from sklearn.tree import DecisionTreeClassifier
from sklearn.neighbors import KNeighborsClassifier
from sklearn.svm import SVC
from sklearn.ensemble import VotingClassifier iris = datasets.load_iris()
X = iris.data[:,[0,2]] #取两列,方便绘图
y = iris.target clf1 = DecisionTreeClassifier(max_depth=4)
clf2 = KNeighborsClassifier(n_neighbors=7)
clf3 = SVC(kernel='rbf', probability=True)
eclf = VotingClassifier(estimators=[('dt',clf1),('knn',clf2),('svc',clf3)], voting='soft', weights=[2,1,1])
#weights控制每个算法的权重, voting=’soft' 使用了软权重 clf1.fit(X,y)
clf2.fit(X,y)
clf3.fit(X,y)
eclf.fit(X,y) x_min, x_max = X[:,0].min() -1, X[:,0].max() + 1
y_min, y_max = X[:,1].min() -1, X[:,1].max() + 1
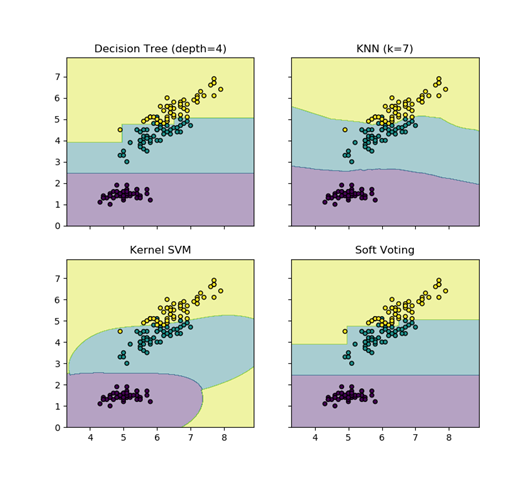
xx, yy = np.meshgrid(np.arange(x_min, x_max, 0.01), np.arange(y_min, y_max, 0.01)) #创建网格 fig, axes = plt.subplots(2, 2, sharex='col', sharey='row', figsize=(10, 8)) #共享X轴和Y轴 for idx, clf, title in zip(product([0, 1],[0, 1]),
[clf1, clf2, clf3, eclf],
['Decision Tree (depth=4)', 'KNN (k=7)',
'Kernel SVM', 'Soft Voting']):
Z = clf.predict(np.c_[xx.ravel(), yy.ravel()]) #起初我以为是预测的X的值,实际上是预测了上面创建的网格的值,以这些值来进行描绘区域
Z = Z.reshape(xx.shape)
axes[idx[0], idx[1]].contourf(xx, yy, Z, alpha=0.4)
axes[idx[0], idx[1]].scatter(X[:, 0],X[:, 1], c=y, s=20, edgecolor='k')
axes[idx[0], idx[1]].set_title(title)
plt.show()
输出结果如下:
参考:
sklearn中的投票法的更多相关文章
- 剑指 Offer 39. 数组中出现次数超过一半的数字 + 摩尔投票法
剑指 Offer 39. 数组中出现次数超过一半的数字 Offer_39 题目描述 方法一:使用map存储数字出现的次数 public class Offer_39 { public int majo ...
- LeetCode题解-----Majority Element II 摩尔投票法
题目描述: Given an integer array of size n, find all elements that appear more than ⌊ n/3 ⌋ times. The a ...
- sklearn中LinearRegression使用及源码解读
sklearn中的LinearRegression 函数原型:class sklearn.linear_model.LinearRegression(fit_intercept=True,normal ...
- Leetcode Majority Element系列 摩尔投票法
先看一题,洛谷2397: 题目背景 自动上次redbag用加法好好的刁难过了yyy同学以后,yyy十分愤怒.他还击给了redbag一题,但是这题他惊讶的发现自己居然也不会,所以只好找你 题目描述 [h ...
- sklearn中调用集成学习算法
1.集成学习是指对于同一个基础数据集使用不同的机器学习算法进行训练,最后结合不同的算法给出的意见进行决策,这个方法兼顾了许多算法的"意见",比较全面,因此在机器学习领域也使用地非常 ...
- sklearn中的多项式回归算法
sklearn中的多项式回归算法 1.多项式回归法多项式回归的思路和线性回归的思路以及优化算法是一致的,它是在线性回归的基础上在原来的数据集维度特征上增加一些另外的多项式特征,使得原始数据集的维度增加 ...
- 【笔记】多项式回归的思想以及在sklearn中使用多项式回归和pipeline
多项式回归以及在sklearn中使用多项式回归和pipeline 多项式回归 线性回归法有一个很大的局限性,就是假设数据背后是存在线性关系的,但是实际上,具有线性关系的数据集是相对来说比较少的,更多时 ...
- 机器学习——sklearn中的API
import matplotlib.pyplot as pltfrom sklearn.svm import SVCfrom sklearn.model_selection import Strati ...
- 【Warrior刷题笔记】力扣169. 多数元素 【排序 || 哈希 || 随机算法 || 摩尔投票法】详细注释 不断优化 极致压榨
题目 来源:力扣(LeetCode) 链接:https://leetcode-cn.com/problems/majority-element/ 注意,该题在LC中被标注为easy,所以我们更多应该关 ...
随机推荐
- 用CRF做命名实体识别(一)
用CRF做命名实体识别(二) 用CRF做命名实体识别(三) 用BILSTM-CRF做命名实体识别 博客园的markdown格式可能不太方便看,也欢迎大家去我的简书里看 摘要 本文主要讲述了关于人民日报 ...
- Linux内核同步原语之原子操作【转】
转自:http://blog.csdn.net/npy_lp/article/details/7262388 避免对同一数据的并发访问(通常由中断.对称多处理器.内核抢占等引起)称为同步. ——题记 ...
- FileZilla 配置备份与还原【转】
FileZilla是一款免费开源的FTP软件,安装和配置都很简单.在安装目录下的FileZilla Server Interface.xml和FileZilla Server.xml两个文件是程序的配 ...
- [How to] 使用HBase协处理器---基本概念和regionObserver的简单实现
1. 简介 对于HBase的协处理器概念可由其官方博文了解:https://blogs.apache.org/hbase/entry/coprocessor_introduction 总体来说其包含两 ...
- Selenium_Grid
Selenium Grid 工作原理 Grid是一种分布式测试工具,整个结果由一个hub主节点和若干个node代理节点组成. hub用来管理各个代理节点的注册和状态信息,并且接收远程客户端代码请求调用 ...
- python【项目】:基于socket的FTP服务器
功能要求 1. 用户加密认证 2. 服务端采用 SocketServer实现,支持多客户端连接 3. 每个用户有自己的家目录且只能访问自己的家目录 4. 对用户进行磁盘配额.不同用户配额可不同 5. ...
- 关于IdByName 为什么一个消息主题要有 Id和 Name的解释
- Java Character & String & Scanner类
Character类 Character 类用于对单个字符进行操作. Character 类在对象中包装一个基本类型 char 的值 char用法: char ch = 'a'; // Unicode ...
- Java 中可变参数
可变参数 Java 中可变参数 现在需要编写一个求和的功能,但是不知道有几个参数,在调用的时候才知道有几个参数,请问这如何实现呢? Java 给我们提供了一个 JDK 1.5 的新特性---可变参数 ...
- Java 中 List 向前和向后遍历
Java 中 List 向前和向后遍历 import java.util.*; public class TestCollectionIterator { public static void mai ...