Mysql Innodb cluster集群搭建
之前搭建过一个Mysql Ndb cluster集群,但是mysql版本是5.7的,看到官网上mysql8的还是开发者版本,所以尝试搭建下mysql Innodb cluster集群。
- MySQL的高可用架构无论是社区还是官方,一直在技术上进行探索,这么多年提出了多种解决方案,比如
MMM,MHA,NDB Cluster,Galera Cluster,InnoDB Cluster, 腾讯的PhxSQL,MySQL Fabric,aliSQL。 NDB:基于集群的引擎-数据被自动切分并复制到数个机器上(数据节点), 适合于那些需要极高查询性能和高可用性的应用, 原来是为爱立信的电信应用设计的。NDB提供了高达99.999%的可靠性,在读操作多的应用中表现优异。 对于有很多并发写操作的应用, 还是推荐用InnoDB。- 本次部署采用
InnoDB Cluster. 每台服务器实例都运行MySQL Group Replication(冗余复制机制,内置failover) MGR有两种模式,一种是Single-Primary,一种是Multi-Primary,即单主或者多主。- 注意:
Multi-Primary模式中,所有的节点都是主节点,都可以同时被读写,看上去这似乎更好,但是因为多主的复杂性,在功能上如果设置了多主模式,则会有一些使用的限制,比如不支持Foreign Keys with Cascading Constraints。
一.工作原理
MySQL InnoDB集群提供了一个集成的,本地的,HA解决方案。Mysq Innodb Cluster是利用组复制的 pxos 协议,保障数据一致性,组复制支持单主模式和多主模式。
MySQL InnoDB集群由以下几部分组成:
- MySQL Servers with Group Replication:向集群的所有成员复制数据,同时提供容错、自动故障转移和弹性。MySQL Server 5.7.17或更高的版本。
- MySQL Router:确保客户端请求是负载平衡的,并在任何数据库故障时路由到正确的服务器。MySQL Router 2.1.3或更高的版本。
- MySQL Shell:通过内置的管理API创建及管理Innodb集群。MySQL Shell 1.0.9或更高的版本。
各个组件的关系和工作流程如下:
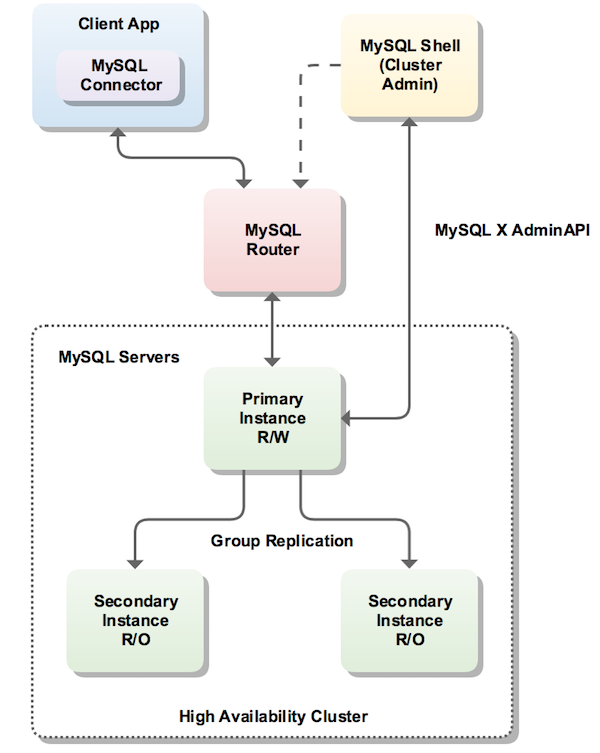

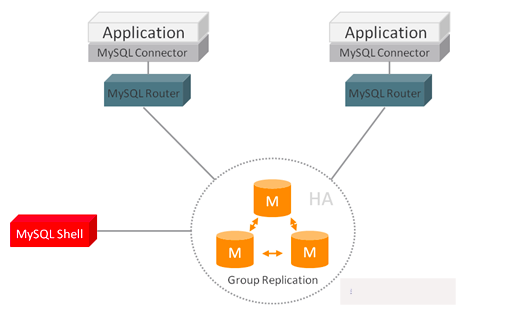
二.集群方案
我创建了四台虚拟机,一台用来负责管理,另外三台是主从节点,一个主,两个从。
管理节点安装mysql-shell和mysql-router,主从节点三个均安装mysql和mysql-shell
后期名称都改为:manager,master和slave1,slave2
mysql,mysql shell 和mysql router的安装包如下:
mysql:mysql-8.0.17-linux-glibc2.12-x86_64.tar.xz
mysql-shell:mysql-shell-8.0.17-linux-glibc2.12-x86-64bit.tar.gz
mysql-router:mysql-router-8.0.17-linux-glibc2.12-x86_64.tar.xz
根据官方的文档 https://dev.mysql.com/doc/refman/8.0/en/mysql-innodb-cluster-userguide.html,mysql-shell需要python环境,至少在2.7版本以上,所以在安装使用前,需要提前部署好python环境。
三.环境准备(所有服务器都要操作)
1.关闭防火墙,关闭方法因系统不同,所以不列出
2.关闭selinux(Centos),关闭方法因系统不同,所以不列出
3.修改/etc/hosts文件,将四台服务器的ip分别映射成manager,master和slave1,slave2
4.优化配置
[root@localhost ~]# cat>>/etc/sysctl.conf <<EOF
fs.aio-max-nr =
fs.file-max =
kernel.shmmax =
kernel.shmmni =
kernel.sem =
net.ipv4.ip_local_port_range =
net.core.rmem_default =
net.core.rmem_max =
net.core.wmem_default =
net.core.wmem_max =
EOF [root@localhost ~]# sysctl -p [root@localhost ~]# cat>>/etc/security/limits.conf <<EOF
mysql soft nproc
mysql hard nproc
mysql soft nofile
mysql hard nofile
EOF [root@localhost ~]# cat>>/etc/pam.d/login <<EOF
session required /lib/security/pam_limits.so
session required pam_limits.so
EOF [root@localhost ~]# cat>>/etc/profile<<EOF
if [ $USER = "mysql" ]; then
ulimit -u -n
fi
EOF [root@localhost ~]# source /etc/profile
四.在主节点安装mysql和mysql-shell
1.解压安装包
tar xvf mysql-8.0.-linux-glibc2.-x86_64.tar.xz
tar zxvf mysql-shell-8.0.-linux-glibc2.-x86-64bit.tar.gz
mv mysql-8.0.-linux-glibc2.-x86_64 /usr/local/mysql/
mv zxvf mysql-shell-8.0.-linux-glibc2.-x86-64bit /usr/local/mysql-shell/
2.添加用户并赋权
groupadd mysql
useradd -g mysql mysql
cd /usr/local/mysql/
mkdir data
cd ..
chown -R mysql:mysql mysql
3.修改环境变量
vi /etc/profile
..........
export PATH=$PATH:/usr/local/mysql-shell/bin/:/usr/local/mysql/bin/
source /etc/profile
4.在/etc/下增加配置文件my.cnf
[mysqld]
character-set-server=utf8
port=
socket=/tmp/mysql.sock
basedir=/usr/local/mysql
datadir=/usr/local/mysql/data
log-error=/usr/local/mysql/data/mysqld.log
pid-file=/usr/local/mysql/data/mysql.pid
user = mysql
tmpdir = /tmp
default-storage-engine=INNODB #复制框架
server_id=
gtid_mode=ON
enforce_gtid_consistency=ON
master_info_repository=TABLE
relay_log_info_repository=TABLE
binlog_checksum=NONE
log_slave_updates=ON
log_bin=binlog
binlog_format=ROW
max_connections=
max_allowed_packet=16M #组复制设置
#server必须为每个事务收集写集合,并使用XXHASH64哈希算法将其编码为散列
transaction_write_set_extraction=XXHASH64
#告知插件加入或创建组命名,UUID
loose-group_replication_group_name="aaaaaaaa-aaaa-aaaa-aaaa-aaaaaaaaaaaa"
#server启动时不自启组复制,为了避免每次启动自动引导具有相同名称的第二个组,所以设置为OFF。
loose-group_replication_start_on_boot=off
#告诉插件使用IP地址,端口33061用于接收组中其他成员转入连接
loose-group_replication_local_address="master:33061"
#启动组server,种子server,加入组应该连接这些的ip和端口;其他server要加入组得由组成员同意
loose-group_replication_group_seeds="master:33061,slave1:33061,slave2:33061"
loose-group_replication_ip_whitelist="master,slave1,slave2,manager"
loose-group_replication_bootstrap_group=off
# 使用MGR的单主模式
loose-group_replication_single_primary_mode=on
loose-group_replication_enforce_update_everywhere_checks=off
disabled_storage_engines = MyISAM,BLACKHOLE,FEDERATED,CSV,ARCHIVE
5.安装mysql
/usr/local/mysql/bin/mysqld --initialize-insecure --basedir=/usr/local/mysql --datadir=/usr/local/mysql/data
6.进入到mysql的base目录,设置开机自启动
#加入到service服务
cp support-files/mysql.server /etc/init.d/mysqld
chmod +x /etc/init.d/mysqld #加入到开机自启动列表
chkconfig --add mysqld
7.登陆mysql,修改登陆密码(这里因为是不安全安装,所以密码为空,没有默认密码,登陆后直接回车就可以进入客户端页面)
mysql> ALTER USER 'root'@'localhost' IDENTIFIED BY '';
五.创建cluster集群
1.进到master的 mysql-shell 的安装目录,登陆mysql-shell
bin/mysqlsh
mysql-js> shell.connect('root@localhost:3306');
#连接成功后
#配置实例
dba.configureLocalInstance();
#此时会让选择创建管理cluster的用户,我选1,使用root管理,并且允许远程登陆“%”
#接着查看实例状态
dba.checkInstanceConfiguration("root@localhost:3306");
如果出现:
You can now use it in an InnoDB Cluster.
{
"status": "ok"
}
说明配置成功。
2.登陆manager管理节点,讲router和shell都解压到/usr/local/文件夹下分别为mysql-route和mysql-shell
3.登陆manager节点的shell,连接master,创建cluster
bin/mysqlsh # 连接01
mysql-js> shell.connect('root@master:3306'); # 创建一个 cluster,命名为 'myCluster'
mysql-js> var cluster = dba.createCluster('myCluster'); # 创建成功后,查看cluster状态
mysql-js> cluster.status();
创建后,可以看到master已经添加进cluster,并且状态是读写,我这里用别人的状态图,表示一下:
mysql-js> cluster.status();
{
"clusterName": "myCluster",
"defaultReplicaSet": {
"name": "default",
"primary": "master:3306",
"status": "OK_NO_TOLERANCE",
"statusText": "Cluster is NOT tolerant to any failures.",
"topology": {
"master:3306": {
"address": "master:3306",
"mode": "R/W",
"readReplicas": {},
"role": "HA",
"status": "ONLINE"
}
}
}
}
4.添加slave1节点
和上面一样的方法,先安装好mysql和mysql-shell,注意配置文件中server_id需要改成
server_id=
同时,
loose-group_replication_local_address="slave1:33061"
登陆shell,执行配置
bin/mysqlsh
mysql-js> shell.connect('root@localhost:3306');
mysql-js> dba.configureLocalInstance();
停掉mysql服务,在配置文件my.cnf末尾添加配置:
loose-group_replication_allow_local_disjoint_gtids_join=ON
重启mysql后,通过manager节点的shell,将slave1添加到cluster:
# 添加实例
cluster.addInstance('root@slave1:3306'); # 创建成功后,查看cluster状态
mysql-js> cluster.status();
成功后状态:
mysql-js> cluster.status();
{
"clusterName": "myCluster",
"defaultReplicaSet": {
"name": "default",
"primary": "master:3306",
"status": "OK_NO_TOLERANCE",
"statusText": "Cluster is NOT tolerant to any failures.",
"topology": {
"master:3306": {
"address": "master:3306",
"mode": "R/W",
"readReplicas": {},
"role": "HA",
"status": "ONLINE"
},
"slave1:3306": {
"address": "slave1:3306",
"mode": "R/O",
"readReplicas": {},
"role": "HA",
"status": "ONLINE"
}
}
}
}
5.和slave1一样,添加slave2节点,注意server_id和loose-group_replication_local_address需要修改成3和slave2:33061
六.安装mysql-router
在manager节点上,安装router:
/usr/local/mysql-route/bin/mysqlrouter --bootstrap root@master: -d myrouter --user=root
这里会在当前目录下产生mysql-router 目录, 并生成router配置文件,默认通过route连接mysql后, 6446端口连接后可以进行读写操作. 6447端口连接后只能进行只读操作.
然后启动mysql-route
myrouter/start.sh
查看route进程:
ps -ef|grep myroute
netstat -tunlp|grep (route的pid)
这样就可以使用MySQL客户端连接router了. 下面验证下连接router:a) 管理节点本机mysql-shell连接:mysqlsh --uri root@localhost:
b) 管理节点本机mysql连接:mysql -u root -h 127.0.0.1 -P -p
c) 远程客户机通过route连接mysqlmysql -u root -h manager_ip -P -p
七.验证cluster集群
1.登陆后,新建一个表,往里面写进数据,查看从节点数据会不会同步;
2.关闭master的mysql服务,route将主节点自动切换到slave1,slave1从只读变为可读写,重新启动master mysql后,master变为只读模式。
参考链接:
https://www.cnblogs.com/shc336/p/9537904.html
https://blog.csdn.net/chiweiliu4439/article/details/100860080
https://www.cnblogs.com/kevingrace/p/10466530.html
https://blog.csdn.net/qq_15092079/article/details/82665307
https://www.jianshu.com/p/6e2918845ec8
https://blog.csdn.net/weixin_41850404/article/details/84615842
https://www.cnblogs.com/williamzheng/p/11347362.html
https://dev.mysql.com/doc/refman/8.0/en/mysql-innodb-cluster-userguide.html
Mysql Innodb cluster集群搭建的更多相关文章
- Linux下MySQL/MariaDB Galera集群搭建过程【转】
MariaDB介绍 MariaDB是开源社区维护的一个MySQL分支,由MySQL的创始人Michael Widenius主导开发,采用GPL授权许可证. MariaDB的目的是完全兼容MySQL,包 ...
- 重要参考步骤---ProxySQL Cluster 集群搭建步骤
环境 proxysql-1:192.168.20.202 proxysql-2:192.168.20.203 均采用yum方式安装 # cat <<EOF | tee /etc/yum.r ...
- Redis Cluster集群搭建与应用
1.redis-cluster设计 Redis集群搭建的方式有多种,例如使用zookeeper,但从redis 3.0之后版本支持redis-cluster集群,redis-cluster采用无中心结 ...
- MySQL之PXC集群搭建
一.PXC 介绍 1.1 PXC 简介 PXC 是一套 MySQL 高可用集群解决方案,与传统的基于主从复制模式的集群架构相比 PXC 最突出特点就是解决了诟病已久的数据复制延迟问题,基本上可以达到实 ...
- MySQL优化之——集群搭建步骤具体解释
转载请注明出处:http://blog.csdn.net/l1028386804/article/details/46833179 1 概述 MySQL Cluster 是MySQL 适合于分布式计算 ...
- MariaDB Galera Cluster集群搭建
MariaDB Galera Cluster是什么? Galera Cluster是由第三方公司Codership所研发的一套免费开源的集群高可用方案,实现了数据零丢失,官网地址为http://g ...
- Innodb Cluster集群部署配置
目录 一.简介 二.环境声明 三.部署 安装(均操作) 配置(均操作) 开启group_replication(均操作) 启动group_replication 创建集群(在mysql-1执行) 创建 ...
- redis 学习笔记(6)-cluster集群搭建
上次写redis的学习笔记还是2014年,一转眼已经快2年过去了,在段时间里,redis最大的变化之一就是cluster功能的正式发布,以前要搞redis集群,得借助一致性hash来自己搞shardi ...
- Redis Cluster集群搭建与配置
Redis Cluster是一种服务器sharding分片技术,关于Redis的集群方案应该怎么做,请参考我的另一篇博客http://www.cnblogs.com/xckk/p/6134655.ht ...
随机推荐
- Java中的Redis 哨兵高可用性
让我们探索Redis Sentinel,看看如何在Java上运行它,一起来看看,最近get了很多新知识,分享给大家参考学习.需要详细的java架构思维导图路线也可以评论获取! 什么是Redis哨兵? ...
- 如何看Crash 文件
如何查看崩溃日志 好了,获得是人类可读语言的崩溃日志后,或者是从别人手机到处崩溃日志后,下一步就是查看了.下面就正对一个程序猿该如何看稍微说说. 崩溃日志头 1 2 3 4 5 6 7 8 9 ...
- java中使用javaMail工具类发送邮件
1.引入依赖 <!--javaMail--> <dependency> <groupId>javax.mail</groupId> <artifa ...
- requests爬取梨视频主页所有视频
爬取梨视频步骤: 1.爬取梨视频主页,获取主页所有的详情页链接 - url: https://www.pearvideo.com/ - 1) 往url发送请求,获取主页的html文本 - 2) 解析并 ...
- mysql主从之多线程复制
多线程复制 mysql 主从复制原理: 1. master 节点上的binlogdump 线程,在slave 与其正常连接的情况下,将binlog 发送到slave 上. 2. slave 节点的I/ ...
- python实现上传文件到linux指定目录
今天接到一个小需求,就是想在windows环境下,上传压缩文件到linux指定的目录位置并且解压出来,然后我想了一下,这个可以用python试试写下. 环境:1.linux操作系统一台2.window ...
- 网络状态诊断工具——netstat命令
netstat命令可以用来查询整个系统的网络状态.百度百科的定义如下: Netstat的定义是: Netstat是在内核中访问网络连接状态及其相关信息的程序,它能提供TCP连接,TCP和UDP监听,进 ...
- 2020了你还不会Java8新特性?(五)收集器比较器用法详解及源码剖析
收集器用法详解与多级分组和分区 为什么在collectors类中定义一个静态内部类? static class CollectorImpl<T, A, R> implements Coll ...
- Arrays.asList() 导致的java.lang.UnsupportedOperationException异常
Arrays.asList() 只支持遍历和取值 不支持增删改 继承至AbstractList内部类
- 小白学 Python 爬虫(41):爬虫框架 Scrapy 入门基础(八)对接 Splash 实战
人生苦短,我用 Python 前文传送门: 小白学 Python 爬虫(1):开篇 小白学 Python 爬虫(2):前置准备(一)基本类库的安装 小白学 Python 爬虫(3):前置准备(二)Li ...