sklearn数据集划分
sklearn数据集划分方法有如下方法:
KFold,GroupKFold,StratifiedKFold,LeaveOneGroupOut,LeavePGroupsOut,LeaveOneOut,LeavePOut,ShuffleSplit,GroupShuffleSplit,StratifiedShuffleSplit,PredefinedSplit,TimeSeriesSplit,
①数据集划分方法——K折交叉验证:KFold,GroupKFold,StratifiedKFold,
- 将全部训练集S分成k个不相交的子集,假设S中的训练样例个数为m,那么每一个自己有m/k个训练样例,相应的子集为{s1,s2,...,sk}
- 每次从分好的子集里面,拿出一个作为测试集,其他k-1个作为训练集
- 在k-1个训练集上训练出学习器模型
- 把这个模型放到测试集上,得到分类率的平均值,作为该模型或者假设函数的真实分类率
这个方法充分利用了所以样本,但计算比较繁琐,需要训练k次,测试k次
KFold:

import numpy as np
#KFold
from sklearn.model_selection import KFold
X=np.array([[1,2],[3,4],[5,6],[7,8],[9,10],[11,12]])
y=np.array([1,2,3,4,5,6])
kf=KFold(n_splits=2) #分成几个组
kf.get_n_splits(X)
print(kf)
for train_index,test_index in kf.split(X):
print("Train Index:",train_index,",Test Index:",test_index)
X_train,X_test=X[train_index],X[test_index]
y_train,y_test=y[train_index],y[test_index]
#print(X_train,X_test,y_train,y_test)
#KFold(n_splits=2, random_state=None, shuffle=False) #Train Index: [3 4 5] ,Test Index: [0 1 2] #Train Index: [0 1 2] ,Test Index: [3 4 5]
GroupKFold:
import numpy as np
from sklearn.model_selection import GroupKFold
X=np.array([[1,2],[3,4],[5,6],[7,8],[9,10],[11,12]])
y=np.array([1,2,3,4,5,6])
groups=np.array([1,2,3,4,5,6])
group_kfold=GroupKFold(n_splits=2)
group_kfold.get_n_splits(X,y,groups)
print(group_kfold)
for train_index,test_index in group_kfold.split(X,y,groups):
print("Train Index:",train_index,",Test Index:",test_index)
X_train,X_test=X[train_index],X[test_index]
y_train,y_test=y[train_index],y[test_index]
#print(X_train,X_test,y_train,y_test) #GroupKFold(n_splits=2)
#Train Index: [0 2 4] ,Test Index: [1 3 5]
#Train Index: [1 3 5] ,Test Index: [0 2 4]
StratifiedKFold:保证训练集中每一类的比例是相同的
import numpy as np
from sklearn.model_selection import StratifiedKFold
X=np.array([[1,2],[3,4],[5,6],[7,8],[9,10],[11,12]])
y=np.array([1,1,1,2,2,2])
skf=StratifiedKFold(n_splits=3)
skf.get_n_splits(X,y)
print(skf)
for train_index,test_index in skf.split(X,y):
print("Train Index:",train_index,",Test Index:",test_index)
X_train,X_test=X[train_index],X[test_index]
y_train,y_test=y[train_index],y[test_index]
#print(X_train,X_test,y_train,y_test) #StratifiedKFold(n_splits=3, random_state=None, shuffle=False)
#Train Index: [1 2 4 5] ,Test Index: [0 3]
#Train Index: [0 2 3 5] ,Test Index: [1 4]
#Train Index: [0 1 3 4] ,Test Index: [2 5]
②数据集划分方法——留一法:LeaveOneGroupOut,LeavePGroupsOut,LeaveOneOut,LeavePOut,
- 留一法验证(Leave-one-out,LOO):假设有N个样本,将每一个样本作为测试样本,其他N-1个样本作为训练样本,这样得到N个分类器,N个测试结果,用这N个结果的平均值来衡量模型的性能
- 如果LOO与K-fold CV比较,LOO在N个样本上建立N个模型而不是k个,更进一步,N个模型的每一个都是在N-1个样本上训练的,而不是(k-1)*n/k。两种方法中,假定k不是很大而且k<<N,LOO比k-fold CV更耗时
- 留P法验证(Leave-p-out):有N个样本,将每P个样本作为测试样本,其它N-P个样本作为训练样本,这样得到
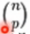 个train-test pairs,不像LeaveOneOut和KFold,当P>1时,测试集将会发生重叠,当P=1的时候,就变成了留一法
个train-test pairs,不像LeaveOneOut和KFold,当P>1时,测试集将会发生重叠,当P=1的时候,就变成了留一法
leaveOneOut:测试集就留下一个
import numpy as np
from sklearn.model_selection import LeaveOneOut
X=np.array([[1,2],[3,4],[5,6],[7,8],[9,10],[11,12]])
y=np.array([1,2,3,4,5,6])
loo=LeaveOneOut()
loo.get_n_splits(X)
print(loo)
for train_index,test_index in loo.split(X,y):
print("Train Index:",train_index,",Test Index:",test_index)
X_train,X_test=X[train_index],X[test_index]
y_train,y_test=y[train_index],y[test_index]
#print(X_train,X_test,y_train,y_test)
#LeaveOneOut()
#Train Index: [1 2 3 4 5] ,Test Index: [0]
#Train Index: [0 2 3 4 5] ,Test Index: [1]
#Train Index: [0 1 3 4 5] ,Test Index: [2]
#Train Index: [0 1 2 4 5] ,Test Index: [3]
#Train Index: [0 1 2 3 5] ,Test Index: [4]
#Train Index: [0 1 2 3 4] ,Test Index: [5
LeavePOut:测试集留下P个
import numpy as np
from sklearn.model_selection import LeavePOut
X=np.array([[1,2],[3,4],[5,6],[7,8],[9,10],[11,12]])
y=np.array([1,2,3,4,5,6])
lpo=LeavePOut(p=3)
lpo.get_n_splits(X)
print(lpo)
for train_index,test_index in lpo.split(X,y):
print("Train Index:",train_index,",Test Index:",test_index)
X_train,X_test=X[train_index],X[test_index]
y_train,y_test=y[train_index],y[test_index]
#print(X_train,X_test,y_train,y_test) #LeavePOut(p=3)
#Train Index: [3 4 5] ,Test Index: [0 1 2]
#Train Index: [2 4 5] ,Test Index: [0 1 3]
#Train Index: [2 3 5] ,Test Index: [0 1 4]
#Train Index: [2 3 4] ,Test Index: [0 1 5]
#Train Index: [1 4 5] ,Test Index: [0 2 3]
#Train Index: [1 3 5] ,Test Index: [0 2 4]
#Train Index: [1 3 4] ,Test Index: [0 2 5]
#Train Index: [1 2 5] ,Test Index: [0 3 4]
#Train Index: [1 2 4] ,Test Index: [0 3 5]
#Train Index: [1 2 3] ,Test Index: [0 4 5]
#Train Index: [0 4 5] ,Test Index: [1 2 3]
#Train Index: [0 3 5] ,Test Index: [1 2 4]
#Train Index: [0 3 4] ,Test Index: [1 2 5]
#Train Index: [0 2 5] ,Test Index: [1 3 4]
#Train Index: [0 2 4] ,Test Index: [1 3 5]
#Train Index: [0 2 3] ,Test Index: [1 4 5]
#Train Index: [0 1 5] ,Test Index: [2 3 4]
#Train Index: [0 1 4] ,Test Index: [2 3 5]
#Train Index: [0 1 3] ,Test Index: [2 4 5]
#Train Index: [0 1 2] ,Test Index: [3 4 5]
③数据集划分方法——随机划分法:ShuffleSplit,GroupShuffleSplit,StratifiedShuffleSplit
- ShuffleSplit迭代器产生指定数量的独立的train/test数据集划分,首先对样本全体随机打乱,然后再划分出train/test对,可以使用随机数种子random_state来控制数字序列发生器使得讯算结果可重现
- ShuffleSplit是KFlod交叉验证的比较好的替代,他允许更好的控制迭代次数和train/test的样本比例
- StratifiedShuffleSplit和ShuffleSplit的一个变体,返回分层划分,也就是在创建划分的时候要保证每一个划分中类的样本比例与整体数据集中的原始比例保持一致
#ShuffleSplit 把数据集打乱顺序,然后划分测试集和训练集,训练集额和测试集的比例随机选定,训练集和测试集的比例的和可以小于1
import numpy as np
from sklearn.model_selection import ShuffleSplit
X=np.array([[1,2],[3,4],[5,6],[7,8],[9,10],[11,12]])
y=np.array([1,2,3,4,5,6])
rs=ShuffleSplit(n_splits=3,test_size=.25,random_state=0)
rs.get_n_splits(X)
print(rs)
for train_index,test_index in rs.split(X,y):
print("Train Index:",train_index,",Test Index:",test_index)
X_train,X_test=X[train_index],X[test_index]
y_train,y_test=y[train_index],y[test_index]
#print(X_train,X_test,y_train,y_test)
print("==============================")
rs=ShuffleSplit(n_splits=3,train_size=.5,test_size=.25,random_state=0)
rs.get_n_splits(X)
print(rs)
for train_index,test_index in rs.split(X,y):
print("Train Index:",train_index,",Test Index:",test_index) #ShuffleSplit(n_splits=3, random_state=0, test_size=0.25, train_size=None)
#Train Index: [1 3 0 4] ,Test Index: [5 2]
#Train Index: [4 0 2 5] ,Test Index: [1 3]
#Train Index: [1 2 4 0] ,Test Index: [3 5]
#==============================
#ShuffleSplit(n_splits=3, random_state=0, test_size=0.25, train_size=0.5)
#Train Index: [1 3 0] ,Test Index: [5 2]
#Train Index: [4 0 2] ,Test Index: [1 3]
#Train Index: [1 2 4] ,Test Index: [3 5]
#StratifiedShuffleSplitShuffleSplit 把数据集打乱顺序,然后划分测试集和训练集,训练集额和测试集的比例随机选定,训练集和测试集的比例的和可以小于1,但是还要保证训练集中各类所占的比例是一样的
import numpy as np
from sklearn.model_selection import StratifiedShuffleSplit
X=np.array([[1,2],[3,4],[5,6],[7,8],[9,10],[11,12]])
y=np.array([1,2,1,2,1,2])
sss=StratifiedShuffleSplit(n_splits=3,test_size=.5,random_state=0)
sss.get_n_splits(X,y)
print(sss)
for train_index,test_index in sss.split(X,y):
print("Train Index:",train_index,",Test Index:",test_index)
X_train,X_test=X[train_index],X[test_index]
y_train,y_test=y[train_index],y[test_index]
#print(X_train,X_test,y_train,y_test) #StratifiedShuffleSplit(n_splits=3, random_state=0, test_size=0.5,train_size=None)
#Train Index: [5 4 1] ,Test Index: [3 2 0]
#Train Index: [5 2 3] ,Test Index: [0 4 1]
#Train Index: [5 0 4] ,Test Index: [3 1 2]
sklearn数据集划分的更多相关文章
- 【学习笔记】sklearn数据集与估计器
数据集划分 机器学习一般的数据集会划分为两个部分: 训练数据:用于训练,构建模型 测试数据:在模型检验时使用,用于评估模型是否有效 训练数据和测试数据常用的比例一般为:70%: 30%, 80%: 2 ...
- sklearn数据集
数据集划分: 机器学习一般的数据集会划分为两个部分 训练数据: 用于训练,构建模型 测试数据: 在模型检验时使用,用于评估模型是否有效 sklearn数据集划分API: 代码示例文末! scikit- ...
- sklearn数据集的导入及划分
鸢尾花数据集的导入及查看: ①鸢尾花数据集的导入: from sklearn.datasets import load_iris ②查看鸢尾花数据集: iris=load_iris()print(&q ...
- 机器学习笔记(四)--sklearn数据集
sklearn数据集 (一)机器学习的一般数据集会划分为两个部分 训练数据:用于训练,构建模型. 测试数据:在模型检验时使用,用于评估模型是否有效. 划分数据的API:sklearn.model_se ...
- 十折交叉验证10-fold cross validation, 数据集划分 训练集 验证集 测试集
机器学习 数据挖掘 数据集划分 训练集 验证集 测试集 Q:如何将数据集划分为测试数据集和训练数据集? A:three ways: 1.像sklearn一样,提供一个将数据集切分成训练集和测试集的函数 ...
- Sklearn数据集与机器学习
sklearn数据集与机器学习组成 机器学习组成:模型.策略.优化 <统计机器学习>中指出:机器学习=模型+策略+算法.其实机器学习可以表示为:Learning= Representati ...
- 数据集划分——train set, validate set and test set
先扯点闲篇儿,直取干货者,可以点击这里. 我曾误打误撞的搞过一年多的量化交易,期间尝试过做价格和涨跌的预测,当时全凭一腔热血,拿到行情数据就迫不及待地开始测试各种算法. 最基本的算法是技术指标类型的, ...
- 13_数据的划分和介绍之sklearn数据集
1.数据集是如何划分?训练数据和评估数据不能使用相同数据,不然自己测自己,会使得准确率虚高,在遇到陌生数据时,不够准确. 2.数据集的获取: 通过load或者fetch方法. 3.数据集进行分割: 训 ...
- sklearn中,数据集划分函数 StratifiedShuffleSplit.split() 使用踩坑
在SKLearn中,StratifiedShuffleSplit 类实现了对数据集进行洗牌.分割的功能.但在今晚的实际使用中,发现该类及其方法split()仅能够对二分类样本有效. 一个简单的例子如下 ...
随机推荐
- yield和生成器, 通过斐波那契数列学习(2.5)
实现斐波那契数列的集中方法 返回一个数 def fib(max): n, a, b = 0, 0, 1 while n < max: print(b) a, b = b, a+b n += 1 ...
- Python练习题中做错题目
1,一下代码执行的结果为 a = b = "julyedu.com" a = 'AI 教育' print(b) 答案: julyedu.com 要点: 在python中, 不可变对 ...
- appium自动化获取app的appPackage与appActivity方法总结
一,获取apppackage 方法不止一种,我只介绍自己知道的两种. 1,通过APPIUM工具添加APK包后,会自动显示出来. 2,打开UI AUTOMATOR VIEWER 定位工具,随便指向一个定 ...
- docker集群故障迁移
docker swarm 故障时候镜像迁移(无法添加新节点的时候)生产docker集群出现了故障,无法正常添加删除节点.在这样的情况下只能想办法把故障集群的镜像迁移到新的docker集群当中.将发生故 ...
- PHP面试 PHP基础知识 十(网络协议)
网络协议 HTTP协议状态码 状态分为五大类:1XX.2XX.3XX.4XX.5XX 1XX:信息类状态码 表示接受请求正在处理 2XX:success 成功状态码 请求正常处理完毕 3XX:重定 ...
- HTTP协议的消息头:Content-Type和Accept的作用 转载https://www.cnblogs.com/lexiaofei/p/7289436.html
一.背景知识 1.概述 Http报头分为通用报头,请求报头,响应报头和实体报头. 请求方的http报头结构:通用报头|请求报头|实体报头 响应方的http报头结构:通用报头|响应报头|实体报头 Acc ...
- 2019 ACM-ICPC 上海网络赛 B. Light bulbs (差分)
题目链接:Light bulbs 比赛链接:The Preliminary Contest for ICPC Asia Shanghai 2019 题意 给定 \(N\) 个灯泡 (编号从 \(0\) ...
- ICPC Asia Nanning 2017 I. Rake It In (DFS+贪心 或 对抗搜索+Alpha-Beta剪枝)
题目链接:Rake It In 比赛链接:ICPC Asia Nanning 2017 Description The designers have come up with a new simple ...
- Java.util.ArrayDeque类
java.util.ArrayDeque 类提供了可调整大小的阵列,并实现了Deque接口.以下是关于阵列双端队列的要点: 数组双端队列没有容量限制,使他们增长为必要支持使用. 它们不是线程安全的;如 ...
- Spring IOC源码分析(一):ApplicationContext体系结构设计之自底向上分析
spring-context包1. ApplicationContext接口 public interface ApplicationContext extends EnvironmentCapabl ...