sklearn中,数据集划分函数 StratifiedShuffleSplit.split() 使用踩坑
在SKLearn中,StratifiedShuffleSplit 类实现了对数据集进行洗牌、分割的功能。但在今晚的实际使用中,发现该类及其方法split()仅能够对二分类样本有效。
一个简单的例子如下:
1 import numpy as np
2 from sklearn.model_selection import StratifiedShuffleSplit
3
4 l4 = np.array([[1,2],[3,4],[1,4],[3,5]])
5 l5 = np.array([0,1,0,2])
6 splt = StratifiedShuffleSplit(n_splits=1,test_size=0.5,random_state=1)
7 for train_idx, valid_idx in splt.split(l4, l5):
8 print(train_idx,valid_idx)
9 print('=======')
10 print(l4[train_idx],l4[valid_idx])
11 print('=======')
12 print(l5[train_idx],l5[valid_idx])
l4 为样本输入列表,l5 为样本输出列表,其中,样本输出(l5)共有3类:[0,1,2] 此时,运行程序会报错:
ValueError: The least populated class in y has only 1 member, which is too few. The minimum number of groups for any class cannot be less than 2.

报错信息的字面意思是:我样本输出仅有1类,需要最少2类。但问题是我实际上有3类输出样本。这个问题百度了半天也没找到合适的解答。
后面将3类样本改为2类,该函数就能正常运行了。
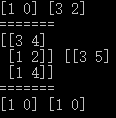
1 import numpy as np
2 from sklearn.model_selection import StratifiedShuffleSplit
3
4 l4 = np.array([[1,2],[3,4],[1,4],[3,5]])
5 l5 = np.array([0,1,0,1])
6 splt = StratifiedShuffleSplit(n_splits=1,test_size=0.5,random_state=1)
7 for train_idx, valid_idx in splt.split(l4, l5):
8 print(train_idx,valid_idx)
9 print('=======')
10 print(l4[train_idx],l4[valid_idx])
11 print('=======')
12 print(l5[train_idx],l5[valid_idx])
注意,在上方代码第5行,将 l5 的值进行修改,样本输出仅有[0,1]两类。
此时运行程序,运行无误。
StratifiedShuffleSplit.split() 函数对于多分类问题还是无法正确适配。
sklearn中,数据集划分函数 StratifiedShuffleSplit.split() 使用踩坑的更多相关文章
- Date()日期函数浏览器兼容问题踩坑
原文:Date()日期函数浏览器兼容问题踩坑 之前用layui做的一项目中,table中用到了日期格式化的问题.直接没多想,撸代码就完了呗,结果最近一段时间客户反馈说显示日期跟录入日期不一样(显示日期 ...
- Net4.6 Task 异步函数 比 同步函数 慢5倍 踩坑经历
Net4.6 Task 异步函数 比 同步函数 慢5倍 踩坑经历 https://www.cnblogs.com/shuxiaolong/p/DotNet_Task_BUG.html 异步Task简单 ...
- 机器学习实战基础(十九):sklearn中数据集
sklearn提供的自带的数据集 sklearn 的数据集有好多个种 自带的小数据集(packaged dataset):sklearn.datasets.load_<name> 可在 ...
- 『审慎』.Net4.6 Task 异步函数 比 同步函数 慢5倍 踩坑经历
异步Task简单介绍 本标题有点 哗众取宠,各位都别介意(不排除个人技术能力问题) —— 接下来:我将会用一个小Demo 把 本文思想阐述清楚. .Net 4.0 就有了 Task 函数 —— 异步编 ...
- sklearn中的分词函数countVectorizer()的改动--保留长度为1的字符串
1简述问题 使用countVectorizer()将文本向量化时发现,文本中长度唯一的字符串会被自动过滤掉,这对于我在做的情感分析来讲,一些表较重要的表达情感倾向的词汇被过滤掉,比如文本'没用的东西, ...
- Python中字符串操作函数string.split('str1')和string.join(ls)
Python中的字符串操作函数split 和 join能够实现字符串和列表之间的简单转换, 使用 .split()可以将字符串中特定部分以多个字符的形式,存储成列表 def split(self, * ...
- 转载 --- SKLearn中预测准确率函数介绍
混淆矩阵 confusion_matrix 下面将一一给出'tp','fp','fn'的具体含义: 准确率: 所有识别为"1"的数据中,正确的比率是多少. 如识别出来100个结果是 ...
- C# 中奇妙的函数–String Split 和 Join
很多时候处理字符串数据,比如从文件中读取或者存入 - 我们可能需要加入分隔符(如CSV文件中的逗号),或使用一个分隔符来合并字符串序列. 很多人都知道使用split()的方法,但使用与其对应的Join ...
- sklearn中的cross_val_score()函数
sklearn.cross_validation.cross_val_score(estimator, X, y=None, scoring=None, cv=None, n_jobs=1, verb ...
随机推荐
- Spring Boot demo系列(一):Hello World
2021.2.24 更新 1 新建工程 打开IDEA选择新建工程并选择Spring Initializer: 可以在Project JDK处选择JDK版本,下一步是选择包名,语言,构建工具以及打包工具 ...
- ssh+scp基本使用
1 ssh ssh一般用于连接服务器,可以使用密码认证与密钥认证的方式. 1.1 密码认证 直接使用ssh即可: ssh username@xxx.xxx.xxx.xxx username为用户名,后 ...
- Android Activity间跳转与传递数据
1 概述 Activity之间的跳转主要使用 startActivity(Intent intent); startActivityForResult(Intent intent,int reques ...
- 基于MATLAB的手写公式识别(4)
啊啊啊~ 目的 1.考虑图像预处理的合理性和结果.能达到什么样的结果,该结果是否满足我的需要,如果多余是否有删除的必要? 2.切割问题,他是怎样实现字符的切割的?字符之间识别的依据和划定该依据的标准是 ...
- Zabbix三种邮箱告警配置
环境 环境 IP地址 主机名 需要安装的应用 系统版本 服务端 192.168.23.140 zabbix lamp zabbix_server zabbix_agent CentOS 8 客户端 1 ...
- C++ 面向对象高级设计
inline关键字 类声明内定义的函数,自动成为inline函数,类声明外定义的函数,需要加上inline关键字才能成为inline函数 构造函数 应该使用列表初始化 class complex { ...
- Linux-鸟菜-6-文件与目录的 默认权限、隐藏权、特殊权限
Linux-鸟菜-6-文件与目录的 默认权限.隐藏权.特殊权限 除了基本r,w,x权限外,在Linux还可以设定其他系统隐藏属性,可以用chattr来设定,和lsattr来查看,但注意一点,CentO ...
- WPF中属性经动画处理后无法更改的问题
在WPF的Animation中,有一个属性为FillBehavior,用于指定时间线在其活动周期结束后但其父时间线仍处于活动周期或填充周期时的行为方式.如果希望动画在活动周期结束时保留其值,则将动画F ...
- 使用 Azure Container Registry 储存镜像
Azure Container Registry(容器注册表)是基于 Docker Registry 2.0规范的托管专用 Docker 注册表服务. 可以创建和维护 Azure 容器注册表来存储与管 ...
- 【vue-08】vuex
vuex的作用 简单理解,就是将多个组件共享的变量统一放到一个地方去管理,比如用户登录时的数据token. 快速上手 安装:npm install vuex 首先,我们在src文件夹下创建一个文件夹: ...